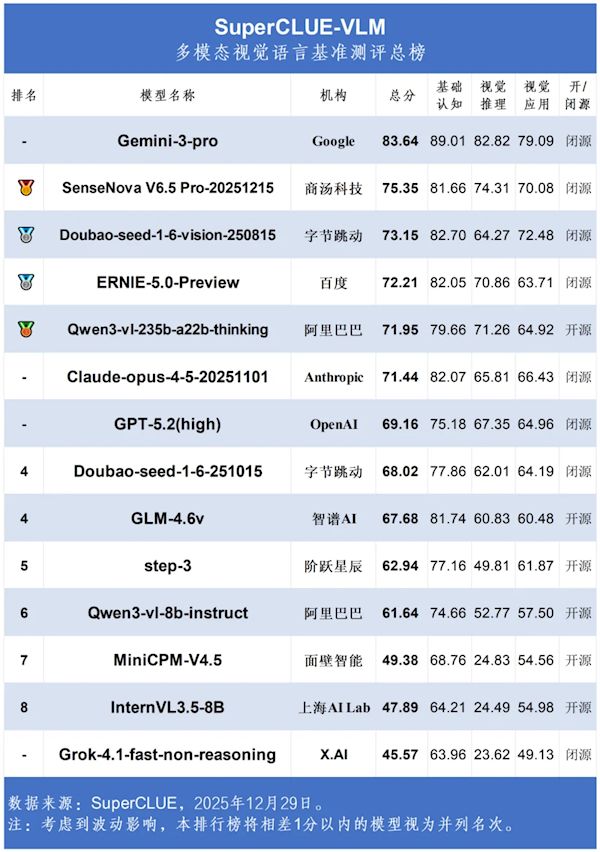
12 月 31 日消息,近日,SuperCLUE-VLM 多模态视觉语言基准测评 12 月总榜公布。
谷歌的 Gemini-3-pro 以 83.64 分遥遥领先,字节跳动的豆包大模型以 73.15 分跻身前三,展现出国内大模型的竞争力。
此次测评从基础认知、视觉推理、视觉应用三个维度对多模态大模型进行评估。
榜首 Gemini-3-pro 在三项细分指标中均表现突出,基础认知得分 89.01、视觉推理 82.82、视觉应用 79.09,全面领先其他模型。

国内阵营中,商汤科技 SenseNova V6.5 Pro 以 75.35 分位居第二,字节跳动的豆包视觉版紧随其后,其基础认知得分 82.70,甚至超过部分国际竞品,仅在视觉推理环节稍显短板。
百度 ERNIE-5.0-Preview、阿里巴巴 Qwen3-vl 等国内模型也进入前五,其中 Qwen3-vl 是榜单中首个开源且总分超 70 的模型。
国际头部模型中,Anthropic 的 Claude-opus-4-5 得分 71.44,OpenAI 的 GPT-5.2(high)仅获 69.16 分,排名相对靠后。