
新智元报道
编辑:桃子好困
AAAI 2026 录用结果重磅公布!这一届,投稿量暴增至 23,680 篇,录用率仅 17.6%,竞争程度远超往年。一些成功上岸的研究员们晒出了录用成绩单,有人甚至拿下了 88887 高分。
AAAI 2026 录用结果出炉!
这几天,AAAI 组委会陆续发出邮件,AI 圈年度顶会录用结果随之揭晓。
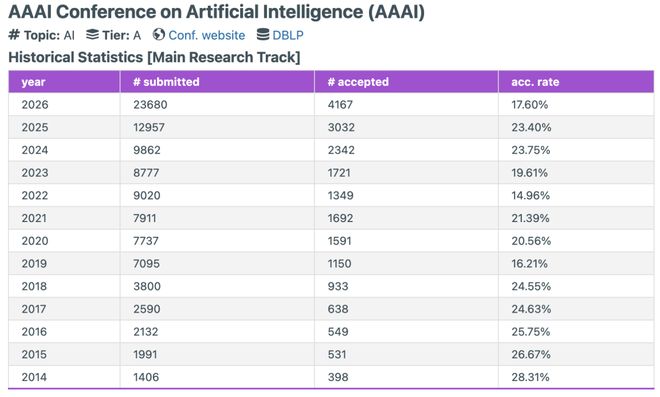
邮件显示,AAAI 2026 共收到 23,680 份论文投稿,创历史新高,AAAI 2025 一共收到 12957 篇有效投稿。
同时,4,167 篇被录用,录用率仅为 17.6%。作为对比,今年 AAAI 录用了 3032 篇论文,录用率 23.4%。

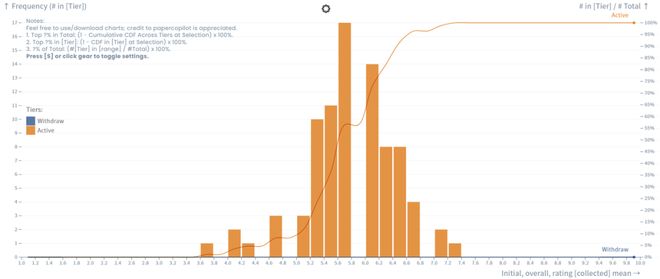
地址: https://papercopilot.com/statistics/aaai-statistics/aaai-2026-statistics/
作为 AI 领域公认的顶会之一,AAAI 创办于 1980 年,每年举办一次。
今年,是 AAAI 第四十届年会,将于 2026 年 1 月 20 日-1 月 27 日在新加坡博览中心举办。

一些收到录用邮件的研究员们,纷纷晒出了自己的成绩单。
网友晒出成绩单
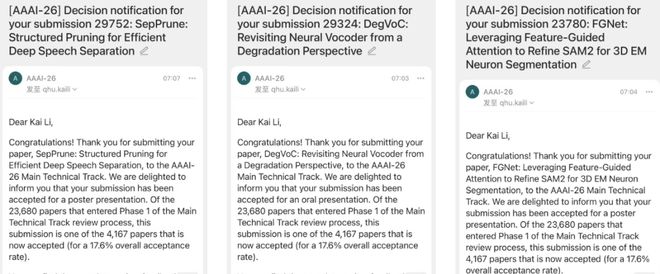
北大张铭教授组中,一位博五同学顾怿洋作为一作的论文被 AAAI 2026 录用,题为「CogniTrust:基于认知记忆的可验证监督的鲁棒散列方法」。
今年,他已有 4 篇 CCF-A 一作论文,前三篇分别被 Artificial Intelligence、NeurIPS、ACM MM 接收。

如今,很多数据标签存在被损坏、不完整、模糊的问题,这种带噪音的标签严重会影响 AI 模型学习的可靠性。
团队受人类记忆方式的启发,提出了 CogniTrust,将可验证监督与三元记忆模型相结合的新框架:情景记忆、语义记忆和重构记忆。
这些组件共同构成了一个闭环机制,从空间和语义两个角度验证、校准和综合监督。
实验显示,CogniTrust 可从结构上验证监督信号的方式,并为标签决策提供了可解释的依据。

来自南洋理工加小俊分享了,自己和团队在 AAAI 2026 上连中五篇,其中 3 篇 Poster,2 篇 Oral。
分别聚焦大模型隐私保护、安全对齐、多模态安全、自动驾驶鲁棒性、多智能体安全通信等方向。
-
两篇 Oral 论文:
MPAS:基于图消息传递的并行多智能体系统,打破顺序通信限制,将通信时长从 84.6s 降至 14.2s,并显著增强抗后门鲁棒性。
SECURE:提出微调安全约束方法,惩罚正交更新以保持模型在「狭窄安全盆地」内,减少 7.6% 有害行为、提升 3.4% 性能。
-
三篇 Poster 论文:
GeoShield:首个面向 VLM 地理隐私防护的对抗框架,通过特征解耦、暴露识别、尺度自适应增强,有效阻止模型推测地理位置,显著优于现有方法。
EmoAgent:首个多模态推理模型情感对抗框架,揭示「安全-推理悖论」,通过夸张情感提示劫持推理路径,暴露深层安全错位。
PhysPatch:面向自动驾驶的可物理实现对抗贴片框架,联合优化贴片参数与语义位置,在多种 MLLM 上具有高迁移性与真实部署价值。
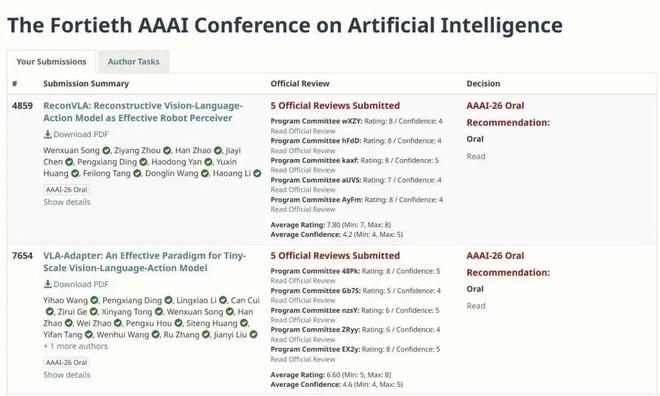
来自香港科技大学(广州)的博士生宋文轩,也斩获了 2 篇 Oral 论文,均是关于 VLA(视觉-语言-动作)大模型的研究,其中一篇 ReconVLA 拿到了 88887 高分。
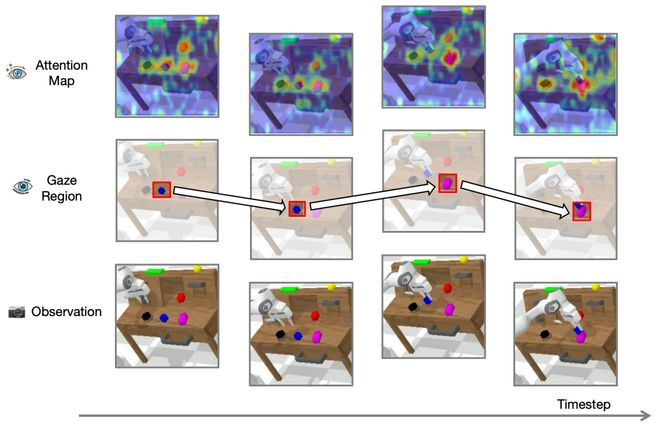
ReconVLA 提出了一种面向 VLA 视觉表征学习的新思路,通过引入「视觉 token」引导重建「凝视区域」的辅助任务,隐式增强了 VLA 落地的能力。
另外一篇,VLA-Adapter 作为已经破圈的轻量级 VLA 基座,在 GitHub 拿下 1.6k 个星。它仅需 0.5B 的小模型就在主流基准上(CALVIN、LIBERO)达到了 SOTA 性能。两篇工作均完全开源。

清华李凯和团队共有 1 篇 Oral 和 2 篇 Poster。
拿下 Oral 的这篇,拿下了 689 的高分(其中 9 分置信度为5),审稿人对此评价:
我很好奇,这个思路在我们领域居然一直没被探索过。
团队提出的 DegVoC 借鉴了「压缩感知」的思想,将 vocoder 建模成反退化问题,并利用迭代优化求解思想将其建模成初始化与深度先验正则。
结果实证,DegVoC 以 3.89M 和 45.62GMACs/5s 显著更低开销,达到目前 GAN/DDPM/FM 方法的 SOTA。
另外两篇 Poster 分别是:
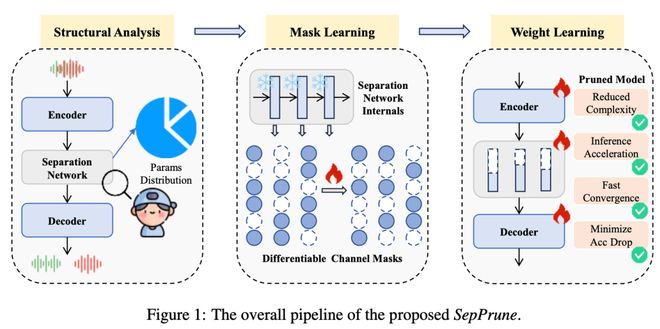
一篇提出了 SepPrune,专为深度语音分离模型构建结构化剪枝框架引入创新的「可微分掩码策略」,让模型通过梯度学习自动剔除冗余通道。
剪枝后的模型收敛速度比从零开始训练快 36 倍。而且,仅需 1 个 epoch 的微调,模型就能恢复预训练模型高达 85% 的性能。
另一篇提出了一个 FGNet 框架,将视觉基础大模型 Segment Anything 2(SAM2)在海量自然图像中学习到的强大先验知识,高效迁移至 EM 神经元分割领域。
即便在 SAM2 权重完全冻结时,新方法的性能已媲美 SOTA。一经微调,更是显著超越所有方案。
来自蒙纳士大学的副教授 Hamid Rezatofighi 称,团队也有三篇论文(1 Oral)被录用。

还有更多学者纷纷分享了被录用论文的结果。

2 万篇论文厮杀,还有「关系户」?
在 Reddit 上,关于这一届 AAAI 讨论热火朝天。
不同以往,AAAI 2026 论文总投稿量冲破 2 万,打破了以往多年来的纪录。

在此之前,曾有网友爆出 AAAI 2026 收到了近 3 万篇投稿
根据 openaccept 统计,AAAI 2026 录用率是近三年来最低的一次。这对于投稿人来说,并不是一件好事。
地址:https://openaccept.org/c/ai/aaai/
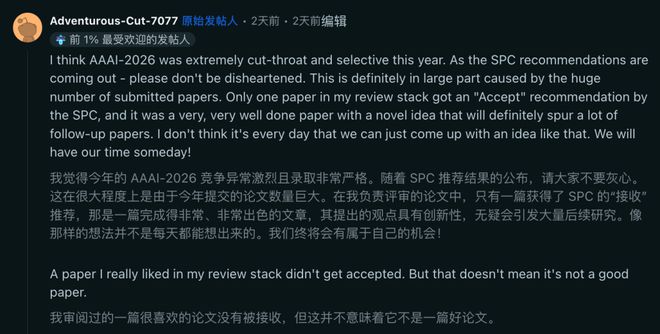
有一位审稿人现身表示,今年 AAAI 竞争异常激烈,而且录取非常严格。很大程度上,是由于提交论文数量巨大。
在他负责评审的论文中,仅一篇获得 SPC 接收,而且是那种极具创新性的。
更离谱的是,还有那些刚提交 rebuttal 的作者,其他几个评审反手就把分数给调低了。
这架势,简直像是联合组团卡拒稿的。

另有作者表示,根据自己了解情况,总体得分大约在 5 分以上论文都有可能被录用。

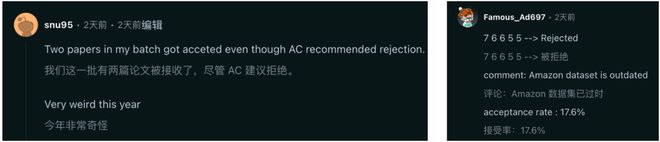
还有人两篇论文都被 AC 拒绝了,但最终还是被顶会录用。一位拿下 76665 成绩的人,因数据集过时却被拒了。
在 AAAI 还未公布结果之前,一位审稿人亲历:我给的 3 分论文,竟被「关系户」抬到 8 分。
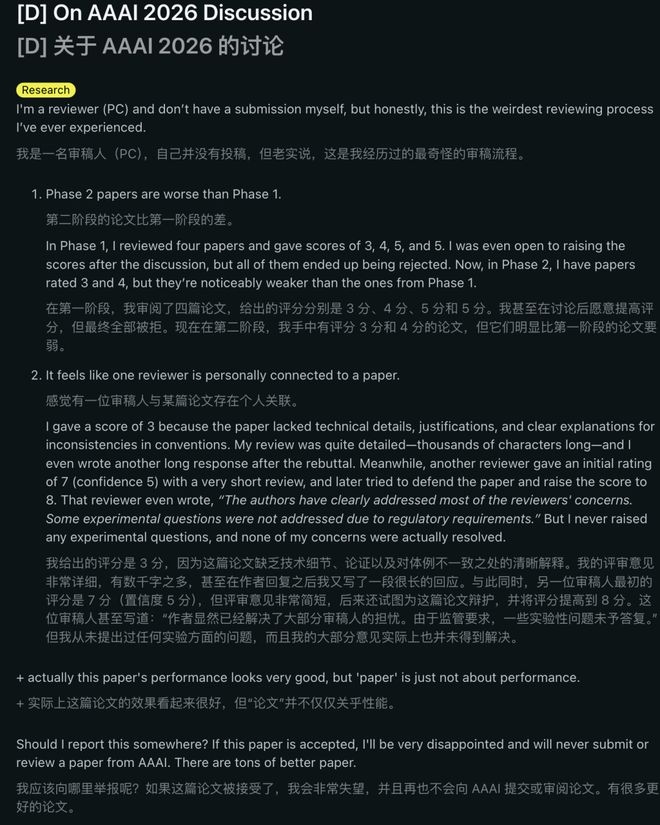
这次,我并没有投稿。但说实话,这是我经历过的最奇怪的审稿过程。
-
第二阶段的论文比第一阶段还差。
在第一阶段,他评审了四篇论文,给出的分数是3、4、5、5。
审稿人甚至愿意在讨论后提高分数,但它们最终全被拒了。现在第二阶段,自己评审的论文分数是 3 和4,但它们明显比第一阶段的论文要弱。
-
感觉像是有审稿人与某篇论文存在私人关系
审稿人给了一篇论文 3 分,因为它缺乏技术细节、论证依据,并且对规范不一致之处没有清晰解释。
他的审稿意见相当详细——长达数千字——而且在作者 rebuttal 后,又写了另一篇长篇回复。
与此同时,另一位审稿人最初给出了 7 分(置信度5),审稿意见非常简短,后来却试图为该论文辩护,并将分数提高到 8 分。
那位审稿人甚至写道:作者已经清楚地回应了大多数审稿人的关切。一些实验问题因监管要求未予解决。
但审稿人认为,自己从未提出任何实验问题,而且他提出的关切点实际上一个都没得到解决。
-
实际上,这篇论文展示的效果很能打,但实际上的重点不只是在秀性能。
正如网友所言,录用与否不取决于评分,而是由主席决定的。

参考资料:
https://openaccept.org/c/ai/aaai/
https://x.com/lyson_ober/status/1986939786163011775
https://papercopilot.com/statistics/aaai-statistics/aaai-2026-statistics/






