DeepSeek 最新开源的模型,已经被硅谷夸疯了!
因为实在太 DeepSeek 了。3B 规模、指数级效能变革、大道至简,甚至被认为把谷歌 Gemini 严防死守的商业机密开源了。
唯一的问题可能就是被“OCR”命名耽误了。
是的,DeepSeek 刚刚开源即火爆的模型就叫:DeepSeek-OCR。

这个模型瞄准的是大模型处理长文本时的算力爆炸难题……虽然模型参数很小,但四两拨千斤,其背后所代表的“用视觉方式压缩一切”的思想,大道至简,既是人类智能的现实,也不断出现在诸如《三体》的科幻作品中。
简单来说,由于一张图能包含大量文字(用的 token 还更少),所以他们想到并验证了“将视觉作为文本压缩媒介”这一方法——就好比优秀的人看书都是扫一眼就知道内容,不必一字一句读完才理解内容。
一图胜千言。
而且 DeepSeek 研究后发现,当压缩率小于 10 倍时(即文本 token 数是视觉 token 数的 10 倍以内),模型 OCR 解码准确率高达 97%;即使压缩率高达20 倍,准确率依旧能保持在60%左右,效果相当能打。
更主要的是,DeepSeek 再次展现了高效能风格,他们的方法之下,生成训练数据——仅凭一块 A100-40G GPU,每天就能生成超过 20 万页的优质 LLM/VLM 训练数据。
所以这个研究一经公布,已经快速在 GitHub 斩获了 3.3K star。HuggingFace 则已经热榜第二……X上热议,好评声一片。
刚“尖锐”评价过 AI 现状的卡帕西说:我很喜欢……特别是图像比文字更适合 LLM 输入,妙啊。
还有人认为这是“AI 的 JPEG 时刻”,AI 记忆架构打开了新路径。
还有爆料猜测,谷歌 Gemini 的核心商业机密被开源了:

当然,如此火爆的工作还带了更多思考——不少人看过论文后,认为这种统一视觉与语言的方法,或许是通往 AGI 的大门之一。
以及 DeepSeek 还在论文中,谈到了 AI 的记忆和“遗忘”机制。
所以,DeepSeek 的新模型,论文究竟是怎么说的?
DeepSeek 新研究:两大核心组件实现“以小博大”
概括而言,DeepSeek 这次提出了一种名为“上下文光学压缩”(Contexts Optical Compression)的思路。
其灵感来自这样一个巧妙的逆向思维:
既然一张图片能“装下”成千上万个字,那我们能不能把文字信息压缩到图片里,让模型通过“看图”来理解内容呢?

本质上来说,这就是一种视觉-文本压缩范式,通过用少量的视觉 token 来表示原本需要大量文本 token 的内容,以此降低大模型的计算开销。
为验证这一想法,他们构建了 3B 大小的 DeepSeek-OCR 模型,结果发现它在主流文档解析基准 OmniDocBench 上取得了新 SOTA。
下图显示,DeepSeek-OCR(红色圆点)在“平均每张图的视觉 token 数”(横轴)上位于最右侧,这说明它使用的 token 数量最少;而在“整体性能”(纵轴,越低越好)上,它却达到了 SOTA 水平,而且大多还是“以小博大”。
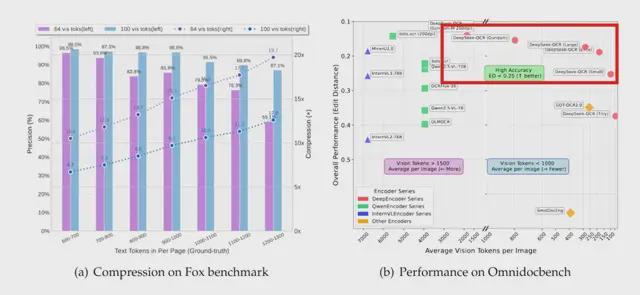
更具体的对比如下:
- 仅用 100 个视觉 token,DeepSeek-OCR 就超过了每页使用 256 个 token 的 GOT-OCR2.0;
- 当使用 400 个视觉 token 时(其中有效 token 为 285),DeepSeek-OCR 就能和之前的 SOTA 模型表现相当;
- 使用不到 800 个视觉 token,DeepSeek-OCR 便大大超过了平均每页近 7000 个视觉 token 的 MinerU2.0。
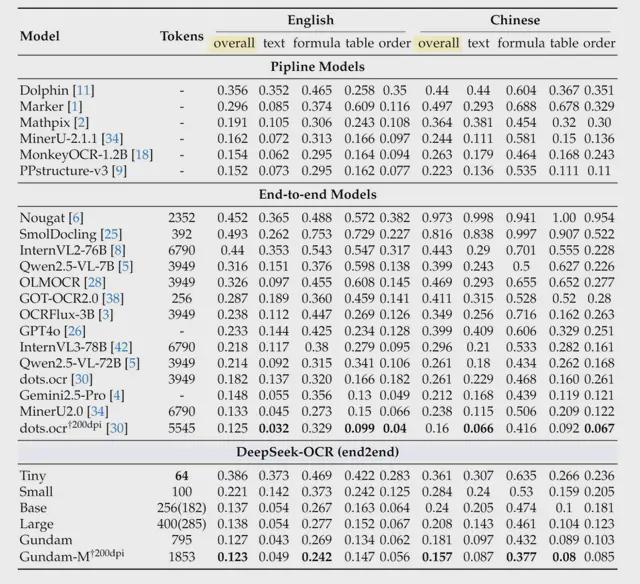
这一切背后都不开 DeepSeek-OCR 架构的两大核心组件:
- 编码器 DeepEncoder:负责把图片转成高度压缩的视觉 token;
- 解码器 DeepSeek3B-MoE-A570M:负责从压缩的视觉 token 里重建文字。

这里重点说一下整个系统的创新关键——编码器 DeepEncoder。
其核心使命为,在处理高分辨率图像时,能够产出数量极少但信息密度极高的视觉 token。
为此它采用了“先局部处理,再压缩,后全局理解”的串行设计:
- 局部处理:利用仅使用“窗口注意力”机制的 SAM-base 模型(8000 万参数),第一步先在高分辨率图像上进行细粒度的局部特征提取。尽管此时生成的视觉 token 数量庞大,但由于窗口注意力的高效性,内存开销仍在可控范围内;
- 再压缩:然后在中间部分加一个 16 倍卷积压缩器,从而在特征进入全局注意力模块前大幅砍掉 token 数量,比如一张 1024x1024 的图片,经过第一阶段会产生 4096 个 token,但经过压缩机后,只剩下 256 个 token 进入第二阶段;
- 后全局理解:最后利用使用“全局注意力”机制的 CLIP-large 模型(3 亿参数),更深入地理解这些经过浓缩后的少量 token,此时由于输入的 token 数量已经大幅减少,所以这里的计算开销也变得可以接受。
此外值得一提的是,为了灵活应对不同的压缩比需求和实际应用场景,DeepEncoder 被训练成支持从“Tiny”(512x512, 64token)到“Gundam”(动态分块,近 800token)等多种输入模式。
就是说,同一个模型可以根据任务需要,随机应变地调整其“压缩强度”。
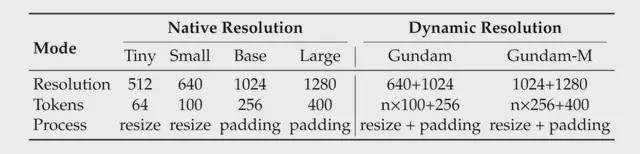
总之,基于以上原理和组件搭配,目前 DeepSeek-OCR 除了具备常规识别能力,还支持对金融报表、化学分子式、数学几何图、100 多种语言等更为复杂的图像进行深度解析。

三位作者亮相
如此被夸赞的新研究,来自三位研究人员,依然很 DeepSeek——几人都相对低调,网上公开资料很少。

Haoran Wei,曾就职于阶跃星辰,当时还主导开发了意在实现“第二代 OCR”的 GOT-OCR2.0 系统。
(2024 年 9 月发表的这篇论文显示,身为论文一作的 Haoran Wei 所处单位为阶跃。)
此次 DeepSeek-OCR 的工作也可谓延续了 GOT-OCR2.0 之前的技术路径,即致力于通过端到端模型解决复杂文档解析问题。

Yaofeng Sun,从去年开始就陆续参与 DeepSeek 多款模型研发,包括 R1、V3 中都有他的身影。
Yukun Li(李宇琨),谷歌学术论文近万引研究员,也持续参与了包括 DeepSeek V2/V3 在内的多款模型研发。
有意思的是,这三人在提出 DeepSeek-OCR 之后,还贡献了一个脑洞大开的想法——
用光学压缩模拟人类的遗忘机制。

只需将上下文光学压缩与人类记忆的衰退过程进行类比,我们就能发现二者高度相似:
- 近期记忆:就像近处的物体,清晰可见。所以可以将其渲染成高分辨率图像,用较多的视觉 token 来保留高保真信息。
- 远期记忆 :就像远处的物体,逐渐模糊。所以可以将其渐进式地缩放成更小、更模糊的图像,用更少的视觉 token 来表示,从而实现信息的自然遗忘和压缩。
这样一来,理论上模型就可以在处理超长对话或文档时,动态地为不同时期的上下文分配不同数量的计算资源,从而可能构建出一种无限长上下文的架构。
团队表示,虽然这还是个早期研究方向,但不失为模型处理超长上下文的一种新思路。
这个思路确实也更像人类的智能。
之前 AI 的上下文研究,对于短期中期远期的都是一视同仁,机器味儿十足,但计算资源和响应问题也会相应暴涨……
而现在,DeepSeek 提出新思路,是时候让 AI 记忆更像人了。
传送门:
Hugging Face:
https://huggingface.co/deepseek-ai/DeepSeek-OCR
GitHub:






