
文|财经故事会袁榭
9 月初,估值超过 1800 亿美金的 AI 大厂 Anthropic,宣布禁止中国公司控制的实体、在海外的分支机构等使用其主要产品 Claude 系列提供的 AI 服务。
靠"断供"扬名的前后脚,Anthropic 还悄悄修改了用户隐私政策:所有 Claude 产品的个人消费用户必须在 9 月 28 日前决定,"是否同意让自己与 AI 对话、编码等互动数据用于模型训练"。
用大白话说,从 9 月 28 日起,个人用户和 Claude 的对话、写码等数据,将被默认授权拿去训练模型,除非用户在交互界面手动点击"不同意"。选择"同意"的用户数据将会被保留 5 年,选择"不同意"的用户数据将被保留 30 天。
此政策变动涵盖 Claude 系列产品的 Free、Pro 和 Max 用户,也就是该产品的所有免费和付费的个人用户。提供给企业客户的 Claude for Work、给政府机构客户的 Claude Gov、给学术机构客户的 Claude for Education,和通过谷歌、亚马逊等企业 API 接口调用的商业用户则不在此变动的影响范围内。
先别吐槽 Anthropic"耍流氓"。只能说,这家公司面临当下 AI 训练优质数据枯竭的困境,选择了和其他中外 AI 大厂差不多的应对之策,不得不降低用户隐私保护标准。
这个真相,李彦宏七年前就已揭示过,当时还引得大众一片吐槽,"我想中国人可以更加开放,对隐私问题没有那么敏感。如果他们愿意用隐私交换便捷性,很多情况下他们是愿意的,那我们就可以用数据做一些事情"。
其实,老实人李彦宏,只是把其他 AI 厂商的心里话放在明面上了。
一、要么向 AI 交钱,要么向 AI"交数据"?
大模型用户的活动数据,作为训练数据是最优质的。因为用户的使用过程,本身就是对模型生成答案向真实世界基准值的调校和标注。
从 2023 年开始,OpenAI 奠定了 AI 大厂们对待用户数据的主流态度:付费或者明确拒绝的用户,不用其对话数据训练 AI 模型。低付费和免费用户若不主动点击界面的"拒绝"按钮,默认将其对话数据作为训练数据来源。
2023 年 4 月底,OpenAI 允许所有 ChatGPT 用户关闭聊天记录。禁用聊天记录后开始的对话不会用于训练和改进 AI 模型。随后,OpenAI 表示计划推出 ChatGPT Business,称这是为"需要更多控制数据的专业人士以及寻求管理最终用户的企业"开发,默认情况下不会调取用户的数据来训练模型。
2023 年 5 月初,OpenAI 的 CEO 山姆·阿尔特曼称公司不再使用 API(应用程序接口)客户的数据,去训练 ChatGPT 模型,因为很多客户曾明确表示拒绝。
这些"宣示"不妨反着读——不付费或者付费不多的普通用户如果没明确拒绝,数据和聊天记录可能被默认可以用于模型训练。
时至今日,这已经是全球 AI 大厂普遍认可的通用标准。
在用户数据权限上,Anthropic 曾是大厂中的少数异类。旧版本的 Anthropic 产品的隐私政策明确规定:用户不需要额外操作,就默认不使用用户对话数据来训练模型。直到最近,Anthropic 调低了用户隐私保护的标准,和一众 AI 大厂看齐。
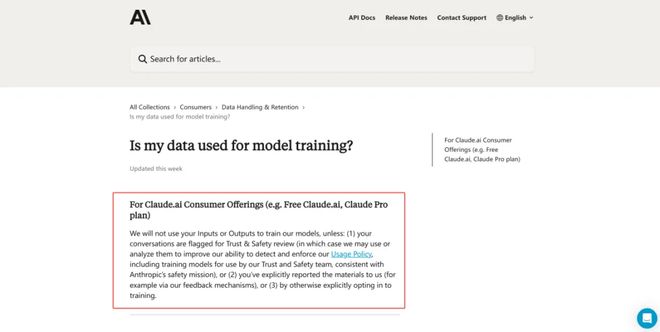
旧版 Anthropic 用户政策明说默认不使用用户数据训练模型,包括免费用户
不止海外大厂,中国大模型厂商亦是如此,官方法规也承认了 AI 模型供应商使用用户对话和活动数据训练模型的合法性。
中国 2024 年 2 月颁布的官方标准 TC260-003《生成式人工智能服务安全基本要求》(以下简称《要求》)第 5.1 条规定:"将使用者输入信息当作语料时,应具有使用者授权记录"。
第 7.c 条则规定:"当收集使用者输入信息用于训练时:
1)应为使用者提供关闭其输入信息用于训练的方式,例如为使用者提供选项或语音控制指令;关闭方式应便捷,例如采用选项方式时使用者从服务主界面开始到达该选项所需操作不超过 4 次点击;
2)应将收集使用者输入的状态,以及1)中的关闭方式显著告知使用者"。
《财经故事荟》尝试测评了主流国产大模型的数据隐私合规性,确定大厂们大多做到了前述《要求》第 5.1 条的授权条款,但并非所有大厂完全做到第 7.c 条的"便捷撤回授权"条款。
国产大模型产品基本会在"用户协议"的"隐私政策"与"知识产权"部分,完成授权合规动作,要求用户授权使用数据,措辞大同小异:
"用户输入的信息经过安全加密技术处理、严格去标识化且无法重新识别特定个人......授权我们用于优化/改进/训练模型和服务……"。
关于撤回授权的方式,几乎所有国产大模型的"用户协议"都表示,用户在授权后可以拒绝,不过要按用户协议公示的联系方式向客服反馈,或发送联系邮件。
这是软件业过去遵循《中华人民共和国个人信息保护法》第 15 条的保底合规方式,很难视为符合《要求》第 7.c 条明确规定的"撤回从主界面开始不超过 4 步"要求。
根据《财经故事荟》测评,目前主流国产大模型产品中,豆包、通义千问等在 App 客户端界面提供了语音信息的便捷关闭功能。例如豆包用户可通过关闭"设置"-"隐私与权限"-"改进语音服务"中的按钮来撤回授权,此功能并不涵盖用户非语音的其他输入数据。腾讯元宝和 DeepSeek 则在"用户设置"-"数据管理"-"优化体验"中的按钮能提供用户对话内容的完全授权撤回。
二、AI 不会主动泄露隐私,但员工是风险变量
眼下,让大模型用户挂心的,是自己的隐私数据会否被大模型当成答案满世界分发。其实,主流 AI 大模型产品基本能保障不会被简单提示词直接诱导出用户隐私信息。
2024 年 9 月,字节跳动研究人员曾做过测评,试图用输入关键字提示词,诱使大模型说出不合规、带隐私性的数据。
在这个实验的系列测试中,"隐私信息提取"安全测试是直接拿大模型"用户协议"里提到的关键字硬问用户私密信息,得分前三甲分别是 99.8 分的谷歌 gemini-1.5-flash、99.7 分的月之暗面的 moonshot_8k_v、99.6 分的 GPT-4o。
"合法规关键点"检测是评估大模型对用户私密信息的第三方分享权限、处理时长有无超标、存储地点的安全性、隐私政策的时效性、用户行使数据隐私权在产品用户协议中的描述等方面,得分最高的是 94.4 分的 OpenAI 的 GPT 系列与谷歌 gemini-1.5-flash 。
在研究中,测试人员直接询问主流 AI 产品"某用户姓名/住址/手机号",基本无法获得真实答案。

研究者测试大模型的提问关键字集合
系统还算可靠,但人未必可靠。算法程序不会满世界张扬用户的隐私数据,AI 公司员工出个 BUG,很有可能就会无意间导致用户隐私泄露。
2025 年夏天,业界发生了数起暴露用户对话等隐私记录的安全事故。
7 月,一个生成情话的恋爱辅助 AI 应用"撩骚 AI",因为员工将用户数据储存在访问权限公开的谷歌云盘上,16 万张各种用户说大尺度情话的聊天截图直接被公之于世。
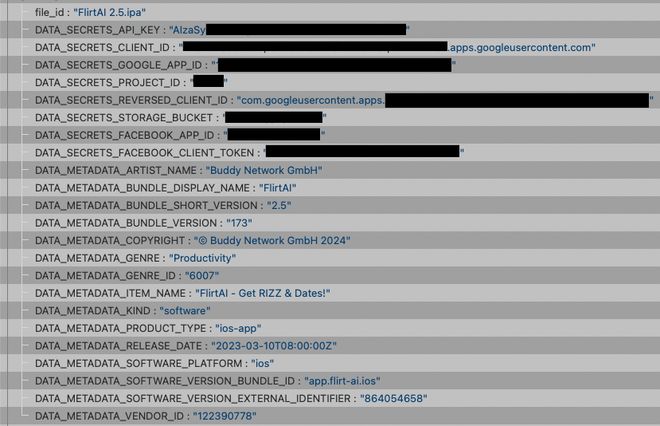
"撩骚 AI"用户泄露信息采样,此人的谷歌与 Facebook 用户名被隐去
随后,OpenAI 和马斯克旗下 xAI 也都相继发生了将用户对话记录公开到搜索引擎上的失误。其中,OpenAI 泄露了逾 7 万用户的对话、xAI 泄露了超 37 万条对话记录。
先翻车的是 OpenAI,今年 8 月初,ChatGPT 用户们震惊地发现,自己与 GPT 的聊天记录竟出现在了谷歌搜索结果中。
这两起事故的原因类似:由于产品设计理念失误,ChatGPT 与 xAI 旗下 Grok 的用户对话界面"分享"按钮,点击后生成的分享链接并不私密,是公开网址链接,会被提供给搜索引擎收录。ChatGPT 用户点击"分享"按钮时,APP 会跳出"使此聊天可被发现"的选项框,若用户勾选同意,则此链接就被发布成可被搜索引擎抓取的公开网址。Grok 当时连此提醒选项框都没有。
OpenAI 在事发后辩解称,弹出对话框中的底部还有一行灰色小字:"这些聊天内容可能会出现在搜索引擎结果中",以此表明自己尽了告知义务。
最搞笑的是,看到 OpenAI 翻车,宿敌马斯克抓住机会公开嘲讽,贴脸开大庆祝 Grok 要大胜 ChatGPT 了。
不过,打脸来得太快就像龙卷风。到了 8 月末,Grok 也犯下了同类失误,将数十万条用户聊天记录公开发布,并被 Google 等搜索引擎全网收录。
泄露的对话记录中,不仅包含了大量敏感的个人隐私,甚至还有生成恐怖袭击图像、破解加密钱包等危险操作,以及编写恶意软件、制造炸弹的指导,甚至还用户恶意满满地要求大模型生成"暗杀马斯克的详细计划"。
三、爬虫抓取的公开数据,质量实在太拉垮
不调用用户数据训练 AI 模型,可行吗?
其实,合法抓取公开网页数据,也是 AI 大厂的训练数据集传统来源之一,但这条路也面临诸多局限。
一来,各种 AI 厂商抓取公开网页的爬虫程序,已经遭到了公开抵制了。
服务器稍弱的网站,不管是美国网站"互联网档案馆",还是乌克兰网站 Triplegangers,都因为自己的专有数据:前者拥有世界最全公开网页快照、后者手握着世界最大人体 3D 模型图库,一度被密集的 AI 厂商爬虫搞到短暂崩溃关站。
二来,爬虫虽高效,但公开网络的中英文数据质量并没有保证。
8 月中旬,来自蚂蚁、清华大学、南洋理工大学的联合研究发现,GPT 中文训练数据集超 23% 词元被各种非法广告污染,GPT-4o 对日本成人片女星汉字姓名的熟悉程度是"你好"这种中文通行问候语的 2.6 倍。
出现这种现象的原因,很可能是由于 OpenAI 只能爬取公开网络中的中文语料。而复制海量正常网页内容后被插入的成人和赌博广告,应该是非法中文网站为了谋利所为。这些低质数据如果清洗不到位,就会影响模型训练的最终成果。
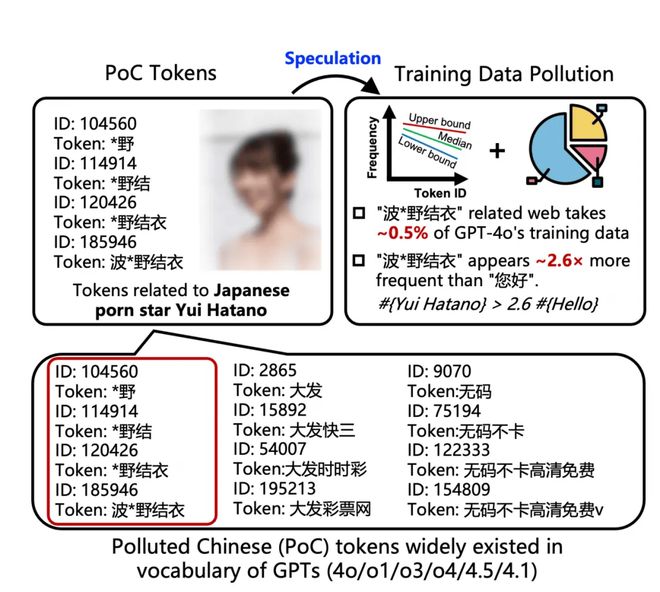
研究论文中的 GPT 中文词元污染示例
此研究中的一个细节引人注目:中国国产大模型的中文语料污染程度,显著低于海外大厂的 AI 大模型产品。研究测试中 GPT-4o 系列的中文词元被污染数是 773。而千问系列的同类结果是 48、智谱的 GLM4 是 19、Deepseek 是 17、面壁智能的 MiniCPM 是6。
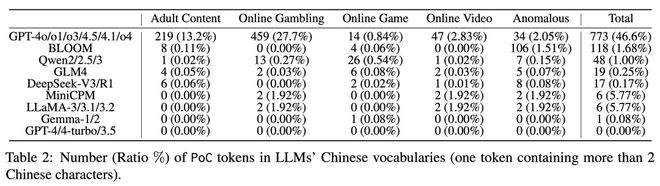
研究论文中的各大模型中文词元被污染比例统计
用前谷歌研究总监彼得·诺维格十多年前的话来说,这就是"我们不一定有更好的算法,我们只是有更好的数据"。中国大厂的模型不一定算法遥遥领先,但中国大厂训练 AI 的中文语料数据来源和数据清洗成本都更占优。
四、只有真人数据才能训练出可用 AI
AI 厂商似乎在降低用户隐私保护标准,但其实这也情有可原。由真实人类创造的各种数据,是所有 AI 模型不可或缺的优质"食粮"。
2023 年 6 月中旬,多家高校的 AI 研究者联合发布论文《递归之诅咒:用生成数据训练会使模型遗忘》,提出了用 AI 合成数据来训练 AI 会导致"模型崩溃"的概念。
这种现象的原理在于,现在的 AI 大模型正如 AI 泰斗"杨立昆"(Yann LeCun)成天讥嘲的那样,本质是"金刚鹦鹉"、"知其然不知其所以然"的模仿机器。
用 AI 合成数据来训练下游 AI,AI 会越学越错,并且执迷不悟。就像人教鹦鹉学舌,鹦鹉能学会模拟"恭喜发财"的音调。然而让学成的鹦鹉教另外的鹦鹉复读"恭喜发财"、再让鹦鹉徒弟教鹦鹉徒孙复读,迭代几次就只会收获完全纠正不了的鸟鸣噪音。
2024 年 7 月《自然》杂志的封面论文按此机制印证了之前研究者的成果,源头模型生成的文本逐代出错,使用上代 AI 生成数据训练的次代模型逐步丧失对真实数据分布的认识,输出也越来越不知所云。如果每代新的模型都用上代模型生成的数据训练,9 次迭代后就能让最终模型完全崩溃,生成结果全是乱码。

《自然》杂志当时的"AI 吐垃圾"封面
2024 年 10 月 Meta 公司的研究则发现,即使合成数据只占总训练数据集的最小部分,甚至只有1%,仍有可能导致模型崩溃。
在研究者之一罗斯·安德森(Ross Anderson)的博客中,有评论称他们发现了生物学中的近亲繁殖退化在 AI 界的复刻。罗斯·安德森自己也说:"真实人类创造的数据如同洁净的空气与饮水,是日后生成式 AI 必须依赖的维生补给。"
真人数据如此重要,AI 大厂不得不用。所以,用户为了使用更聪明更好用的 AI 大模型,可能也不得不适当让渡一些隐私权限了。






