
新智元报道
编辑:海狸
UIUC、斯坦福与哈佛联合提出全新「能量驱动 Transformer(EBT)」架构,突破传统前馈推理方式,以能量最小化模拟人类 System 2 思维,预训练扩展性能较 Transformer++ 最高提升 35%。下一代 AI 基础架构新变革,来了!
在 Transformer 统治 AI 世界十余年之后,
Attention 的时代正在退场,真正的思考刚刚开始——
由 UIUC、斯坦福、哈佛等顶尖机构联合提出的 Energy-Based Transformer(EBT)震撼登场。
它首次将 Transformer 架构引入能量建模(Energy-Based Models, EBM)框架,彻底打破「前馈即推理」的旧范式。

论文链接:https://arxiv.org/pdf/2507.02092
EBT 既不是轻量化微调,也不是 RNN 的改进,而是一种彻底不同的推理机制:
模型不再一次性「说完答案」,而是像人类一样从模糊猜测出发,逐步优化推理路径。
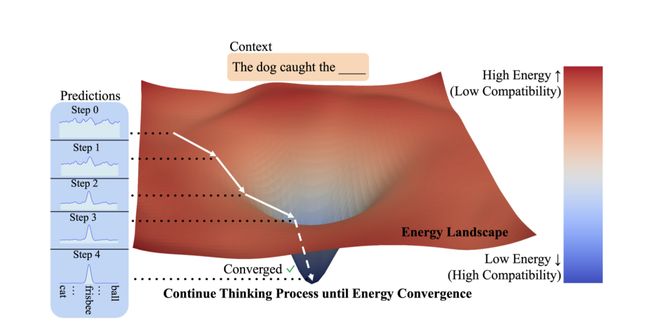
EBT 训练更高效,推理更精准,对 OOD(Out of Distribution)数据更稳健,在训练效率、提升幅度等方面大幅超越前馈式 Transformer(Transformer++):
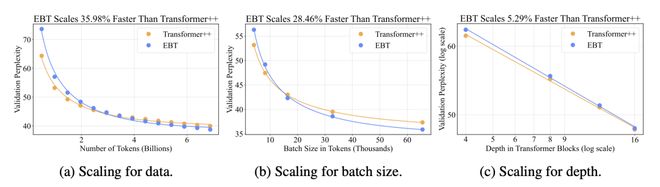
并且,EBT 在文本与图像等多模态任务中展现出惊人的扩展性能,有望实现无监督跨模态通用推理。
「一次生成」vs「动态优化」
传统 Transformer 是一种典型的「前馈预测器」,每次推理过程都是按照从输入 prompt,到固定的前向传播路径,再到输出结果一次完成的。
无论问题简单还是复杂,模型都以固定的计算路径和步骤完成推理,无法因难度灵活调整。
每个 token 都只做一次决策,不进行「反悔」或者「修改」。
这就像一个学生答题时,只能「一遍写完不许改」。
在这种模式下,模型既不能「检查答案」,也无法「修正思路」,更谈不上「深入思考」。
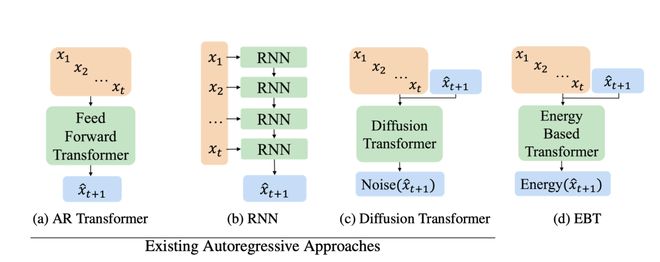
而 EBT 彻底颠覆了这种机制。
EBT 对每个预测都进行多轮优化:
-
不直接输出 token,从随机初始预测开始
-
模型计算该预测与上下文的「能量值」(兼容性高对应能量低,兼容性差对应能量高)
-
通过对能量的梯度下降,不断更新预测,逐步将其「调得更合适」
这个过程会持续多轮,直到能量收敛,也就是模型认为这个预测「足够合理」了。
这样 EBT 最后得到的每个 token 都是动态计算、多步修正的产物,像在能量地形图中「下山」一样逐步收敛到最优答案。
也就是说,模型的「思考」被建模成了一个小型优化任务,不是一遍完全输出答案,而是反复尝试—验证—更新—收敛。

这个「能量最小化」的过程就是 EBT 前所未有的 System 2 Thinking——更慢,更准,更通用的类人深度思考能力。
EBT「三大跃迁」
EBT 的思考过程赋予了它三项关键能力上的根本性突破。
动态计算
传统 Transformer 模型是静态的:每个 token、每个预测都使用固定的计算路径和深度,无论问题简单还是复杂,计算量一视同仁。
而 EBT 拥有动态计算资源分配能力,可以像人一样,遇到简单问题快速处理,遇到困难问题则投入更多思考。
换句话说,EBT 可以动态决定要「多想几步」还是「快速收敛」。
不确定度
而且,EBT 预测能量的设计决定了它可以在连续空间中表达不确定性。
Transformer 虽然能在离散的 token 输出中使用 softmax 表示「概率分布」,但在图像、视频等连续模态中就很难表达不确定性。
EBT 预测上下文之间的能量建模,自然地通过能量高低表达了预测的「可信程度」。
这种能力让 EBT 能在图像、 视频等连续任务中识别哪些位置「值得多想」。
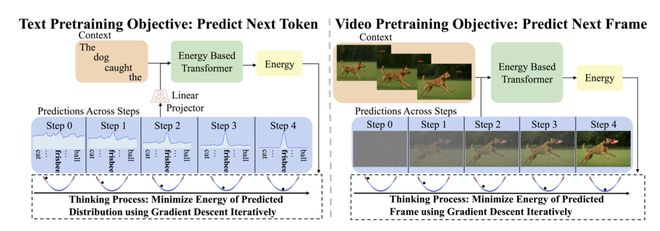
自我验证
在能量分数的加持下,EBT 天生具备显式的自我验证能力。
每次预测,它都会计算衡量上下文匹配程度的「能量分数」。
这个分数不仅可以用来判断答案是否靠谱,而且可以生成多个候选答案,并挑出能量最低的答案作为最终结果。
这种机制彻底摆脱了对外部打分器或奖励函数的依赖,将「反思」环节引入了模型结构本身。
相比之下,传统架构在「思考能力」上几乎全面溃败。

无论是 Feed Forward Transformer 还是 RNN,都缺乏动态计算分配能力、无法建模连续空间中的不确定性,更谈不上对预测结果进行验证。
就连在生成模型中备受追捧的 Diffusion Transformer,也仅在“动态计算”这一项上有所突破,其余两项依然是空白。
相比之下,EBT 是目前为止最接近「人类式思考流程」的方案。
越想越准!Transformer 望尘莫及
EBT 不仅在理论特性上惊艳四座,在实际实验中也表现惊人。
无论有多少数据、加多大批次,模型有多深,EBT 都比经典 Transformer++ 学得更快、更省、效果更稳。
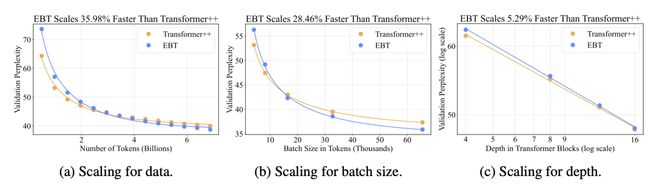
具体而言,要达到相同的困惑度(Perplexity),EBT 的下降速度快 35.98%。也就是说,它只需大约2/3 的训练语料,在「数据瓶颈」的情况下更具性价比。
在分布式大批次训练环境下,EBT 训练收敛速度比 Transformer++ 快 28.46%,深度扩展效率提升 5.29%,效率不掉队。
在 OOD(Out of Distribution)数据上,EBT 也展现出更强的稳健性。
EBT 能通过「多轮推理」与「自我验证」大幅缓解泛化性能下降的问题。
相比之下,传统 Transformer++ 的表现几乎不随推理次数改变。
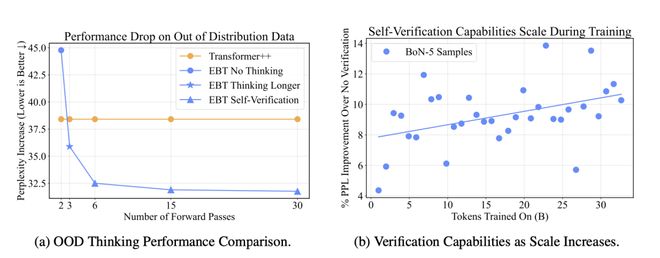
这意味着,哪怕 EBT 预训练指标比 Transformer 略差,一旦开始「思考」,它就能后来居上,「越想越准」。
这种「思维带来泛化」的机制,在当前所有主流大模型架构中都是独一无二的。
跨模态通吃:AGI 更近一步
只要定义清楚「输入」和「候选预测」,EBT 就能在无监督中思考和优化。
EBT 的设计不依赖监督、不依赖额外奖励、不局限于文本或编程,天然适用于任意模态与任务。
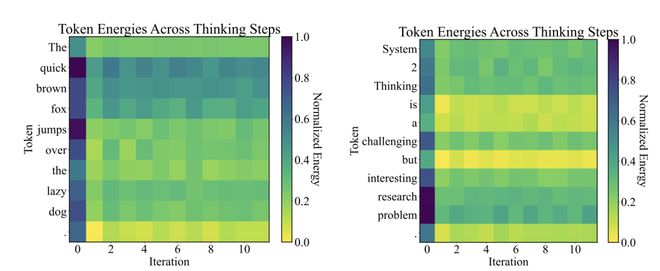
对于文本,EBT 能自动学出不同词的规律:简单词能量低,难词能量高,借此自然表达出语义上的不确定性。
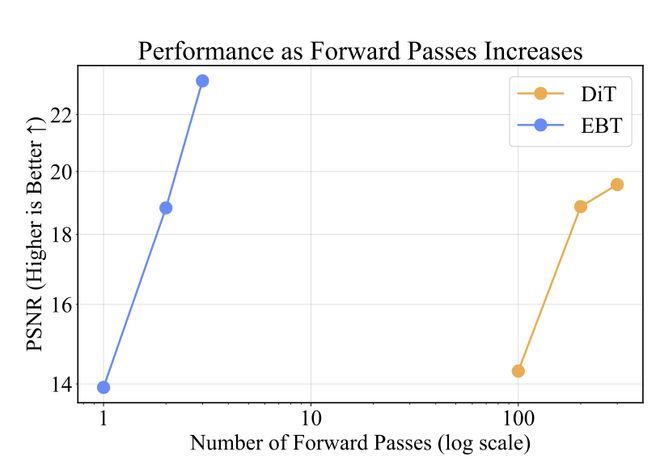
在图像任务中,EBT 告别 Diffusion 模型的上百步生成式推理,仅用1% 的推理步数就能超越 Diffusion Transformer(DiT)在图像去噪和分类上的表现。
视频帧的「不确定性」预测和注意力调整更是不在话下。
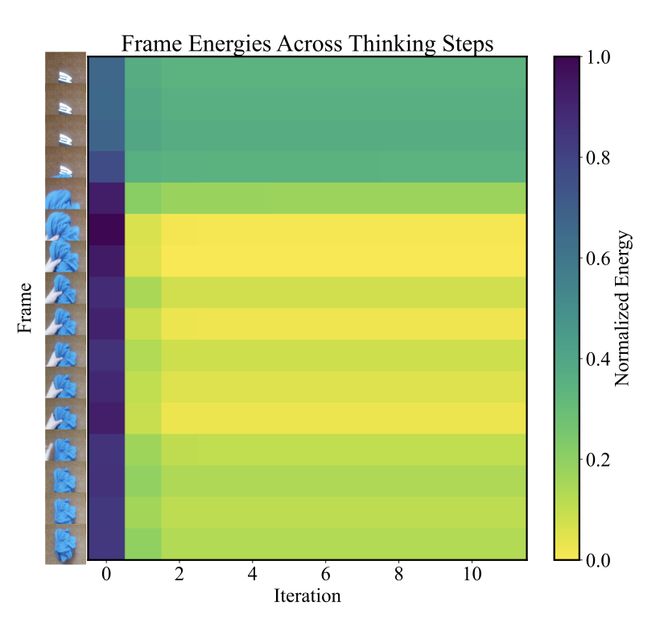
这种统一、灵活、高效的推理机制,很可能成为通往「通用智能」的关键。
毕竟,关于大模型的终极疑问始终存在:它们,真的会「思考」吗?
EBT,或许就是首批有资格回答这个问题的架构之一。
参考资料:
https://x.com/AlexiGlad/status/1942231878305714462






