
新智元报道
编辑:Aeneas 好困
【新智元导读】曾以低价高性能震撼市场的 DeepSeek,为何在自家平台遇冷,市场份额下滑?背后隐藏的「Token 经济学」和这场精心策划的战略转移,正悄然改变着 AI 的价值链与分发模式。
最近,全世界的大厂都在蠢蠢欲动了!
GPT-5、Grok 4,甚至 Claude,都已经纷纷有了消息,一场恶战仿佛就在眼前!

DeepSeek 这边,似乎也有新动静了。
就在昨天,一个疑似 DeepSeek 的新模型现身 LM Arena。
也有人猜测,这个模型更可能是 DeepSeek V4,而 DeepSeek R2 会稍后发布。
套路很可能和之前是一样的,先在第一个月发布 V3,然后在下个月发布 R1。
所以,曾经轰动全球 AI 圈的中国大模型 DeepSeek R1,如今怎样了?
到今天为止,DeepSeek R1 已经发布超过 150 天了。
当时一经问世,它就以 OpenAI 同等级的推理能力和低 90% 的价格而迅速出圈,甚至一度撼动了西方的资本市场。
可是如今,它在用户留存和官网流量上却双双遇冷,市场份额持续下滑。
DeepSeek 就这样昙花一现,红极一时后迅速衰落了?
其实不然,在这背后,其实隐藏着另一条增长曲线——
在第三方平台上,R1 已经成爆炸性增长,这背后,正是折射出 AI 模型分发与价值链的悄然变革。
SemiAnalysis 今天发布的这篇文章,挖出了不少一手的内幕信息。

DeepSeek,盛极而衰?
DeepSeek 发布后,消费者应用的流量一度激增,市场份额也随之急剧上升。
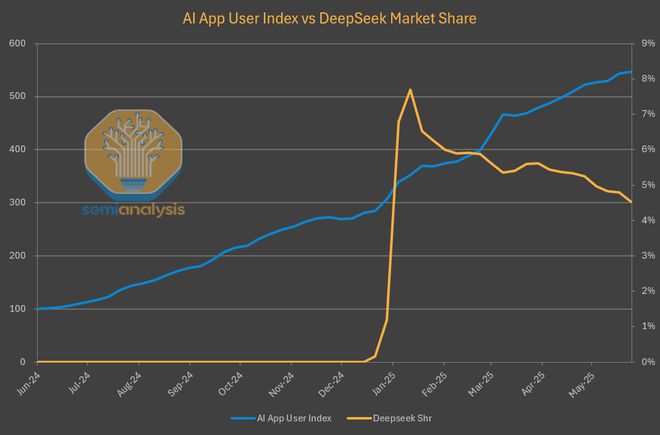
为此,SemiAnalysis 做出了下面这份统计曲线。
当然,他们也承认,由于中国的用户活动数据难以追踪,且西方实验室在中国无法运营,下面这些数据实际上低估了 DeepSeek 的总覆盖范围。
不过即便如此,曾经它爆炸性的增长势头也未能跟上其他 AI 应用的步伐,可以确定,DeepSeek 的市场份额此后已然下滑。
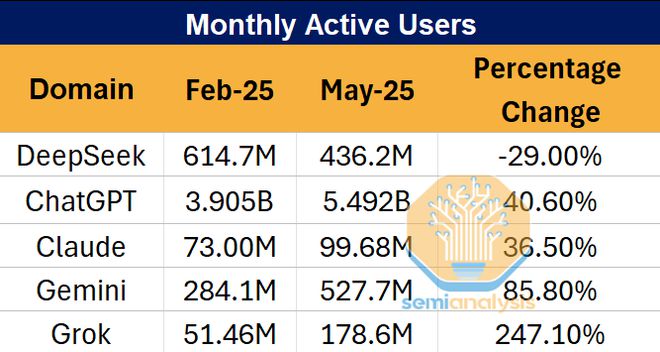
而在网络浏览器流量方面,它的数据就更为惨淡了:绝对流量一直在下降,但其他顶尖模型的用户数却噌噌飞涨,十分可观。
不过,虽然 DeepSeek 自家托管模型的用户增长乏力,但在第三方平台那里,就完全是冰火两重天了。
可以看到,R1 和 V3 模型的总使用量一直在持续快速增长,自 R1 首次发布以来,已经增长将近 20 倍!
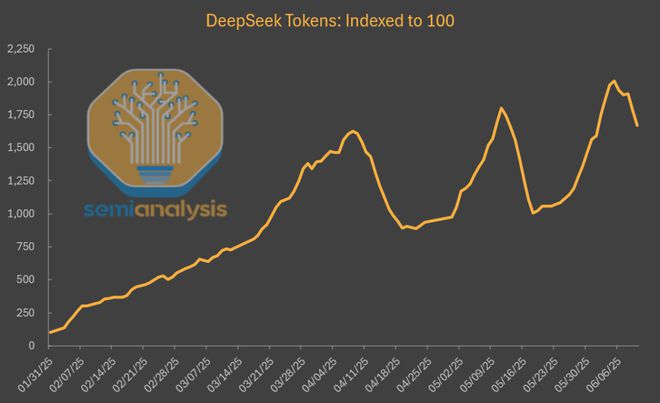
如果进一步深挖数据,就会发现:只看由 DeepSeek 自己托管的那部分 Token 流量,那它在总 Token 中的份额的确是逐月下降的。
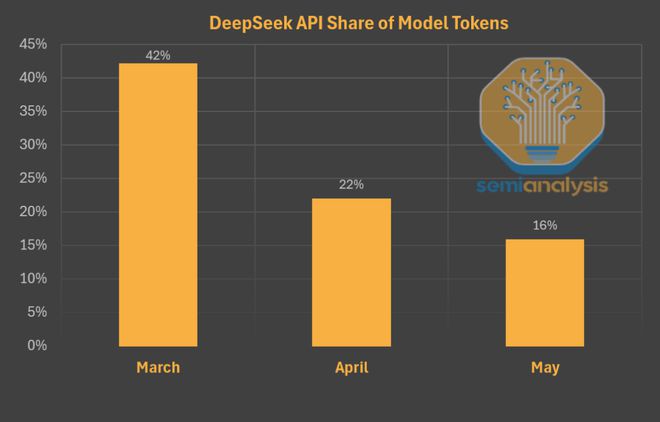
那么,问题来了:为何在 DeepSeek 模型本身越来越受欢迎、官方价格非常低廉的情况下,用户反而从 DeepSeek 自家的网页应用和 API 流失,转向了其他开源提供商呢?
SemiAnalysis 点出了问题关键——
答案就在于「Token 经济学」,以及在平衡模型服务的各项 KPI 时所做的无数权衡。
这些权衡意味着,每个 Token 的价格并非一个孤立的数字,而是模型提供商根据其硬件和模型配置,在对各项 KPI 进行决策后得出的最终结果。
Token 经济学基础
我们都知道,Token 是构成 AI 模型的基本单元。AI 模型通过读取以 Token 为单位的互联网信息进行学习,并以文本、音频、图像或行为指令等 Token 形式生成输出。
所谓 Token,就是像「fan」、「tas」、「tic」这样的小文本片段。LLM 在处理文本时,并非针对完整的单词或字母,而是对这些片段进行计数和处理。
这些 Token,便是老黄口中数据中心「AI 工厂」的输入和输出。
如同实体工厂一样,AI 工厂也遵循一个「P x Q」(价格 x 数量)的公式来盈利:其中,P代表每个 Token 的价格,Q代表输入和输出 Token 的总量。
但与普通工厂不同,Token 的价格是一个可变参数,模型服务商可以根据其他属性来设定这个价格。
以下,就是几个关键的性能指标(KPI)。
-
延迟(Latency)或首个 Token 输出时间(Time-to-First-Token)
指模型生成第一个 Token 所需的时长。这也可以理解为模型完成「预填充」阶段(即将输入提示词编码到 KVCache 中)并开始在「解码」阶段生成第一个 Token 所需的时间。
-
吞吐量(Throughput)或交互速度(Interactivity)
指生成每个 Token 的速度,通常以「每个用户每秒可生成的 Token 数量」来衡量。
当然,有些服务商也会使用其倒数——即生成每个输出 Token 的平均间隔时间(Time Per Output Token, TPOT)。
人类的阅读速度约为每秒3-5 个单词,而大部分模型服务商设定的输出速度约为每秒 20-60 个 Token。
-
上下文窗口(Context Window)
指在模型「遗忘」对话的早期部分、并清除旧的 Token 之前,其「短期记忆」中能够容纳的 Token 数量。
不同的应用场景需要大小各异的上下文窗口。
例如,分析大型文档和代码库时,就需要更大的上下文窗口,以确保模型能够对海量数据进行连贯的推理。
对于任何一个给定的模型,你都可以通过调控这三大 KPI,设定出几乎任何价位的单位 Token 价格。
因此,单纯基于「每百万 Token 的价格」($/Mtok)来讨论优劣,并没有什么意义,因为这种方式忽略了具体工作负载的性质,以及用户对 Token 的实际需求。
DeepSeek 的策略权衡
所以,DeepSeek 在 R1 模型服务上采用了何种 Token 经济学策略,以至于市场份额会不断流失?
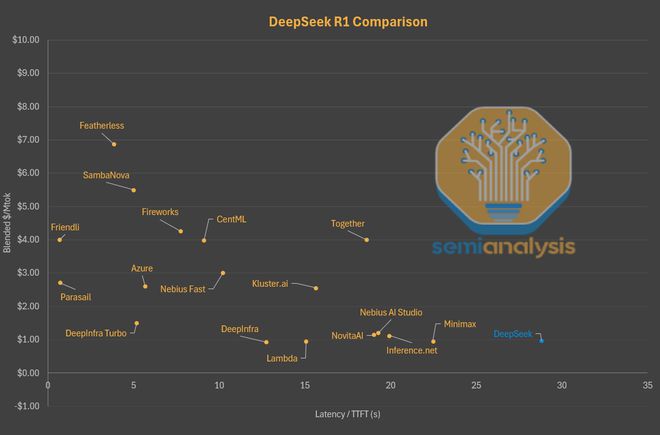
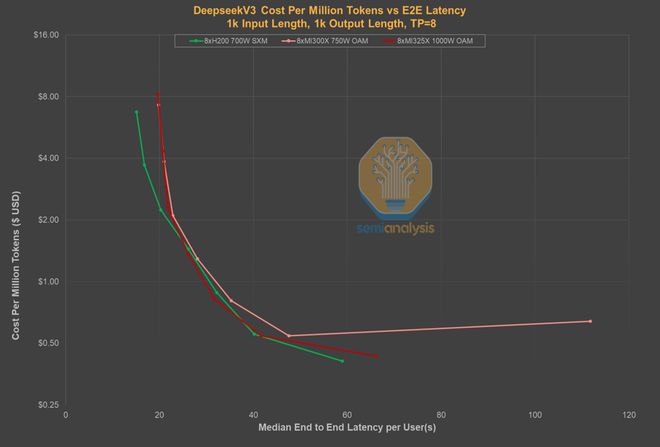
通过对比延迟与价格的关系图,可以看到,在同等延迟水平上,DeepSeek 的自有服务已不再是价格最低的选择。
事实上,DeepSeek 之所以能提供如此低廉的价格,一个重要原因在于,用户等待数秒后,才能收到模型返回的第一个 Token。
相比之下,其他服务商的延迟会短得多,价格却几乎没有差别。
也就是说,Token 消费者只需花费2-4 美元,就能从 Parasail 或 Friendli 这类服务商那里,获得近乎零延迟的体验。
同样,微软 Azure 的服务价格虽比 DeepSeek 高 2.5 倍,但延迟却减少了整整 25 秒。
这样看来,DeepSeek 现在面临的处境就尤为严峻了。
原因在于,现在几乎所有托管 R1 0528 模型的实例都实现了低于 5 秒的延迟。
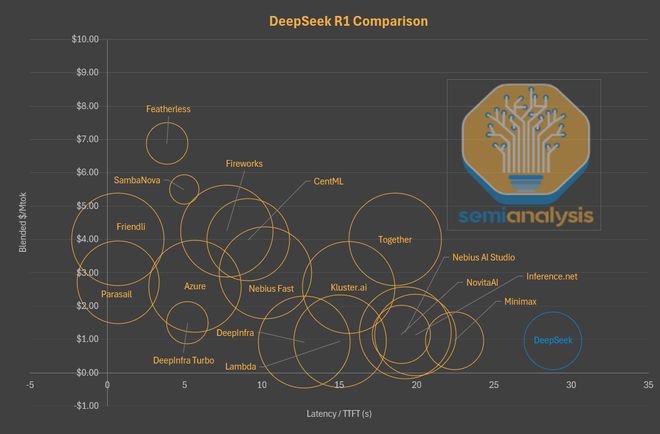
沿用同一图表,但这次我们将上下文窗口的大小用气泡面积来表示。
从中可以看到,DeepSeek 为了用有限的推理算力资源来提供低价模型,所做的另一项权衡。
他们采用的 64K 上下文窗口,几乎是主流模型服务商中最小的之一。
较小的上下文窗口限制了编程等场景的发挥,因为这类任务需要模型能够连贯地记忆代码库中的大量 Token,才能进行有效推理。
从图表中可见,若花费同样的价格,用户可以从 Lambda 和 Nebius 等服务商那里获得超过 2.5 倍的上下文窗口大小。
如果深入硬件层面,在 AMD 和英伟达芯片上对 DeepSeek V3 模型的基准测试,就可以看清服务商是如何确定其「每百万 Token 价格」($/Mtok)的——
模型服务商会通过在单个 GPU 或 GPU 集群上同时处理更多用户的请求(即「批处理」),来降低单位 Token 的总成本。
这种做法的直接后果,就是终端用户需要承受更高的延迟和更慢的吞吐量,从而导致用户体验急剧下降。
之所以 DeepSeek 完全不关心用户的体验到底如何,实际上是一种主动作出的战略选择。
毕竟,从终端用户身上赚钱,或是通过聊天应用和 API 来消耗大量 Token,并不是他们的兴趣所在。
这家公司的唯一焦点就是实现 AGI!
而通过采用极高批处理方式,DeepSeek 可以最大限度地减少用于模型推理和对外服务的计算资源消耗,从而将尽可能多的算力保留在公司内部,从而用于研发。
另外还有一点:出口管制也限制了中国 AI 生态系统在模型服务方面的能力。
因此,对 DeepSeek 而言,开源就是最合乎逻辑的选择:将宝贵的计算资源留作内部使用,同时让其他云服务商去托管其模型,以此赢得全球市场的认知度和用户基础。
不过,SemiAnalysis 也承认,这却并没有削弱中国公司训练模型的能力——无论是腾讯、阿里、百度,还是小红书最近发布的新模型,都证明了这一点。
Anthropic 也一样?
和 DeepSeek 一样,Anthropic 的算力也是同样受限的。
可以看到,它产品研发的重心显然放在了编程上,而且已经在 Cursor 等应用中大放异彩。
Cursor 的用户使用情况,就是评判模型优劣的终极试金石,因为它直接反映了用户最关心的两个问题——成本与体验。
而如今,Anthropic 的模型已雄踞榜首超过一年——在瞬息万变的 AI 行业里,这个时长仿佛已经如十年。
而在 Cursor 上大获成功后,Anthropic 立马顺势推出了 Claude Code,一款集成在终端里的编程工具。
它的用户量一路飙升,将 OpenAI 的 Codex 模型远远甩在身后。
为了对达 Claude Code,谷歌也紧急发布了 Gemini CLI。
它与 Claude Code 功能相似,但因为背靠谷歌 TPU,却有非凡的算力优势——用户能免费使用的额度,几乎无上限。

不过,尽管 Claude Code 的性能和设计都十分出色,价格却不菲。
Anthropic 在编程上的成功,反而给公司带来了巨大压力——他们在算力上已经捉襟见肘。
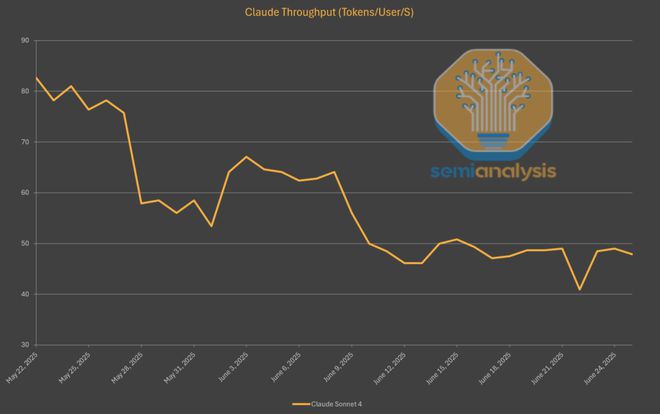
这一点,在 Claude 4 Sonnet 的 API 输出速度上就已经体现得淋漓尽致。自发布以来,它的生成速度已下降了 40%,略高于每秒 45 个 Token。
背后的原因,也和 DeepSeek 如出一辙——为了在有限的算力下处理所有涌入的请求,他们不得不提高批处理的速率。
此外,编程类的使用场景往往涉及更长的对话和更多的 Token 数量,这就进一步加剧了算力的紧张状况。
无论是何种原因,像 o3 和 Gemini 2.5 Pro 这类对标模型的运行速度要快得多,这也反映出 OpenAI 和谷歌所拥有的算力规模要庞大得多。
现在,Anthropic 正集中精力获取更多算力,已经和亚马逊达成了协议。它将获得超过五十万枚 Trainium 芯片,用于模型训练和推理。
另外,Claude 4 模型并非在 AWS Trainium 上预训练的,而是在 GPU 和 TPU 上训练。
速度劣势可由效率弥补
Claude 的生成速度虽然暴露了其算力上的局限,但总体而言,Anthropic 的用户体验(UX)要优于 DeepSeek。
-
首先,其速度虽然偏低,但仍快于 DeepSeek 的每秒 25 个 Token。
-
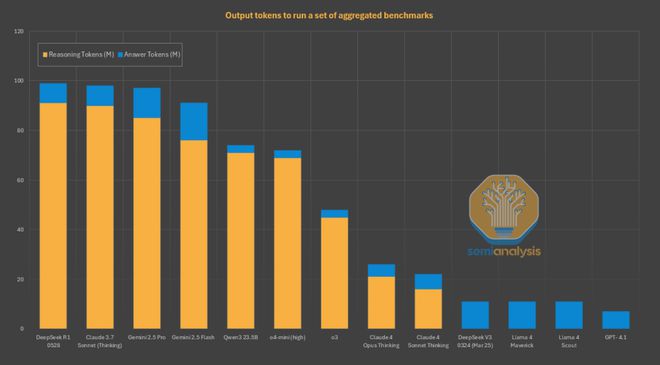
其次,Anthropic 的模型回答同一个问题所需的 Token 数量远少于其他模型。
这意味着,尽管生成速度不占优,用户实际感受到的端到端响应时间反而显著缩短了。
值得一提的是,在所有领先的推理模型中,Claude 的总输出 Token 量是最低的。
相比之下,Gemini 2.5 Pro 和 DeepSeek R1 0528 等模型的输出内容,「啰嗦」程度都是 Claude 的三倍以上。
Token 经济学的这一方面揭示出,服务商正在从多个维度上改进模型,其目标不再仅仅是提升智能水平,而是致力于提高「每单位 Token 所承载的智能」。
随着 Cursor、Windsurf、Replit、Perplexity 等一大批「GPT 套壳」应用(或称由 AI Token 驱动的应用)迅速流行并获得主流市场的认可。
我们看到,越来越多的公司开始效仿 Anthropic 的模式,专注于将 Token 作为一种服务来销售,而不是像 ChatGPT 那样以月度订阅的方式打包。
参考资料:
https://semianalysis.com/2025/07/03/deepseek-debrief-128-days-later/






