新智元报道
编辑:KingHZ 好困
刚刚,由上海交通大学人工智能学院 Agents 团队提出的 AI 专家智能体,在 OpenAI 权威基准测试 MLE-bench 中击败了业界 AI 顶流微软,夺冠登顶!
就在刚刚,一支来自中国高校的团队成功刷榜了 OpenAI 发布的权威基准测试 MLE-bench!
这一次,荣耀属于上海交通大学人工智能学院 Agents 团队。
他们提出的 AI 专家智能体「ML-Master」,凭借着 29.3% 的平均奖牌率,拿下第一!大幅领先微软的 RD-Agent(22.4%)和 OpenAI 展示的 AIDE(16.9%)。
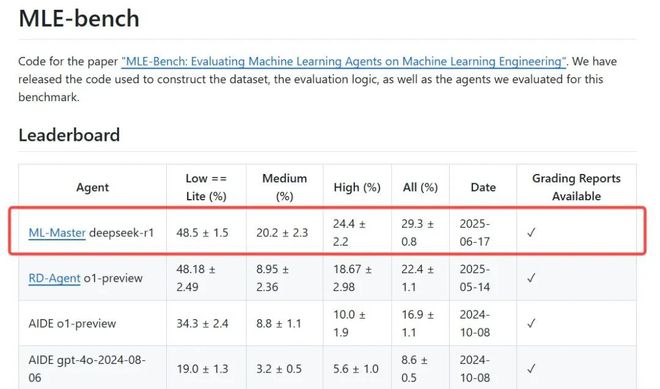
MLE-bench 是衡量 AI 在机器学习工程(MLE)中表现的权威基准。它精选 Kaggle 上的 75 个相关竞赛,构建多样任务,测试 AI 在模型训练、数据准备、实验运行等机器学习工程中的能力
这不仅意味着,ML-Master 已达到了 Kaggle 比赛「Grandmaster」(特级大师)级的水平。
而且还标志着,团队在 AI 自主优化 AI 领域,迈出了关键一步。
那么,这支学术界的团队,是如何击败业界顶尖团队的呢?
AI 开发 AI 的时代已来
ML-Master 引领变革
随着人工智能(AI)能力在多个任务中逐步逼近甚至超过人类水平,AI-for-AI(AI4AI)正成为重要发展方向——
利用 AI 技术自动化和优化 AI 系统自身的设计、训练和部署。
AI4AI 的终极形态是实现具备自主演进能力的 AI 系统,能够独立完成从问题建模、实验设计到算法探索与验证的全过程。
类似于 AlphaGo 向 AlphaZero 的演进路径,该过程经历了从人类辅助训练到完全自主优化的阶段,体现出 AI 系统在自我演进上的潜力和可行性。
为助力 AI4AI 发展,上海交通大学人工智能学院 Agents 团队提出了面向机器学习(Machine Learning)的 AI 专家智能体「ML-Master」。

项目主页:
https://sjtu-sai-agents.github.io/ML-Master
代码地址:
https://github.com/sjtu-sai-agents/ML-Master
论文地址:
https://arxiv.org/pdf/2506.16499
MLE-bench 主页:
https://github.com/openai/MLE-bench
ML-Master 通过创新的「探索-推理深度融合」范式,模拟人类专家的认知策略,整合广泛探索与深度推理,显著提升 AI4AI 性能。
在 OpenAI MLE-bench 基准测试中,ML-Master 以 29.3% 的平均奖牌率居于榜首,超越微软R&D-Agent(22.4%)和 OpenAI 展示的 AIDE 系统(16.9%)。
与先前方法相比,ML-Master 在所有评价维度上均全面领先,尤其在中等难度任务上奖牌率提升 2.2 倍(20.2% vs 9.0%),计算效率翻倍(仅需 12 小时 vs 基线 24 小时)。
⚠️AI4AI 的挑战
探索与推理彼此割裂
尽管大型语言模型(LLM)和自主智能体在 AI4AI 领域取得显著进展,但现有方法仍面临核心挑战:探索与推理的割裂限制了性能提升。
受人类专家开发 AI 的迭代与探索过程启发,研究团队观察到,高效的 AI 开发需要探索与推理的有机结合。
其中,探索通过实验和发现获取新洞察,而推理则通过分析已有知识和历史经验进行深度思考。
两者缺一不可——缺乏推理的探索会导致低效的试错,而缺乏探索的推理则容易陷入停滞。
然而,现有 AI4AI 方法在整合探索与推理时存在以下问题:
-
❌探索效率低下:传统方法常依赖单一路径探索,易陷入局部最优,缺乏系统性导航解决方案空间的能力。
-
❌推理能力受限:现有推理模型难以有效提炼探索过程中的丰富经验,导致决策缺乏历史依据,产生幻觉或不可靠输出。
-
❌深度融合困难:探索与推理往往各自为战,缺乏有效整合机制,限制了整体性能的突破。
因此,如何有效整合探索与推理,让 AI 系统能够像人类专家一样在解决复杂问题时既能广泛探索又能深度思考,成为 AI4AI 领域的核心挑战。
双模块协同
探索与推理深度融合
ML-Master 通过统一的认知框架,模拟人类专家的开发流程,实现了探索与推理的有机协同。
其核心在于平衡多轨迹探索(Balanced Multi-trajectory Exploration)和可控推理(Steerable Reasoning)两大模块,并通过自适应记忆机制(Adaptive Memory)实现两大模块的高效协同。
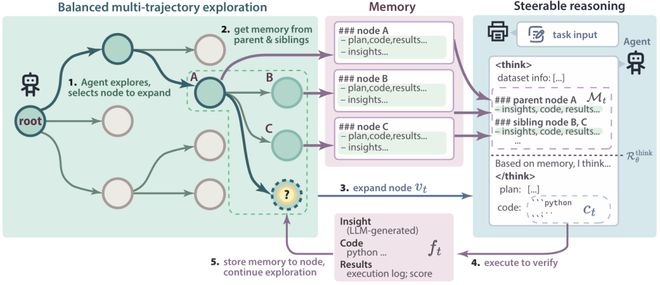
平衡多轨迹探索
Balanced Multi-trajectory Exploration
-
MCTS 启发的树搜索:利用蒙特卡洛树搜索,将研发 AI 过程建模为决策树,每个节点代表一个 AI 方案的状态。
-
并行探索策略:同时探索多个解决方案分支,突破串行限制,多条路径同时探索,大幅提升探索效率,提高解决方案多样性。
-
动态优先级调整:根据潜在价值分配计算资源,实时评估不同分支的潜力,将更多计算资源投入到更有希望的方向,避免无效探索。
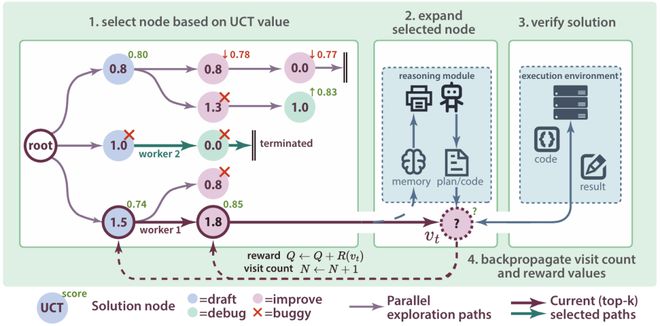
可控推理
Steerable Reasoning
-
自适应记忆机制:精准提取关键洞察,避免信息过载,智能筛选历史探索中的有效信息,既保留宝贵经验又避免冗余干扰,让每次推理都建立在更相关的知识基础上。
-
情境化决策:基于历史经验进行有根据的分析,不再是「拍脑袋」决策,而是结合具体执行反馈和成功案例,让 AI 的每个决定都有据可依。
-
闭环学习系统:持续从执行反馈中学习优化,探索结果实时反哺推理过程,形成「探索→推理→优化→再探索」的良性循环,实现持续自我提升。
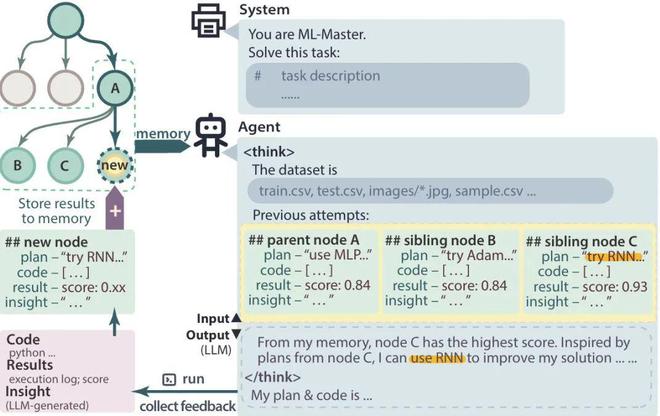
核心融合机制:自适应记忆机制
Adaptive Memory
ML-Master 通过自适应记忆机制实现了两大模块的深度融合:
-
智能记忆构建:探索模块自动收集执行结果、代码片段和性能指标,同时选择性整合来自父节点和并行兄弟节点的关键信息,避免信息过载。
-
嵌入推理决策:记忆信息直接嵌入到推理模型的「think」部分中,让每次推理都基于具体的历史执行反馈和多样化探索的经验进行精准决策。
-
协同进化机制:推理结果指导后续探索方向,探索经验持续丰富推理过程,真正实现了探索驱动推理进化,推理反哺探索路径的良性循环。
MLE-bench 实测
ML-Master 位居榜首
ML-Master 在 OpenAI 发布的 MLE-bench 基准上进行了全面评测。
MLE-bench 是 OpenAI 于 2024 年 10 月推出的类人机器学习能力评测基准,旨在衡量大模型是否具备像人类 AI 工程师一样独立完成项目的能力。
该基准由 75 个来自 Kaggle 的真实机器学习任务组成,涵盖从代码编写、模型调参到结果提交的完整流程,是目前最权威、最贴近实际工程场景的 AI 测试之一。其中不少任务取材自 CVPR 等国际顶级学术会议。
ML-Master 仅在 MLE-bench 上探索学习 900 机器小时,即达成 Kaggle 比赛的 Grandmaster 级别,获取奖牌数位居 20 余万 Kaggle 的参赛者中的 259 位。
ML-Master 在 MLE-bench 上实现了以下突破:
-
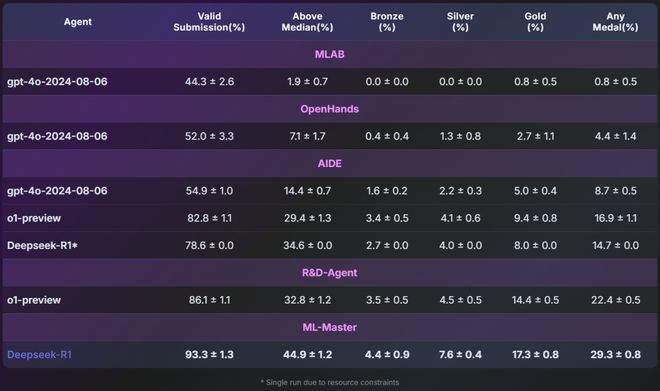
✅顶级性能:29.3% 平均奖牌率,位居 MLE-bench 榜首
-
✅广泛覆盖:93.3% 任务提交有效解,44. 9% 任务超半数人类参赛者
-
✅超高效率:仅用 12 小时完成测试,计算成本仅为基线方法一半

⚔️全面领先,展现多维度优势
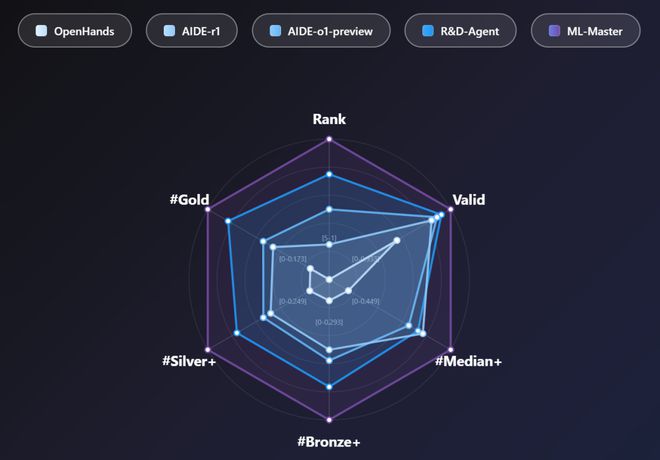
ML-Master 在 MLE-bench 的所有评价维度上均表现卓越。
采用「Bronze+」和「Silver+」指标(表示达到或超过铜牌/银牌阈值),ML-Master 展现全面实力:
-
✔️有效提交率:93. 3%,接近完美
-
⬆️超越中位率:44.9%,力超半数人类参赛者
-
️荣获奖牌率:17.3%/7.6%/4.4% 的任务斩获金/银/铜牌,实现全方面领先
这样的全面领先展现了 ML-Master 作为「六边形战士」的综合实力。
卓越适应性,覆盖各个难度等级
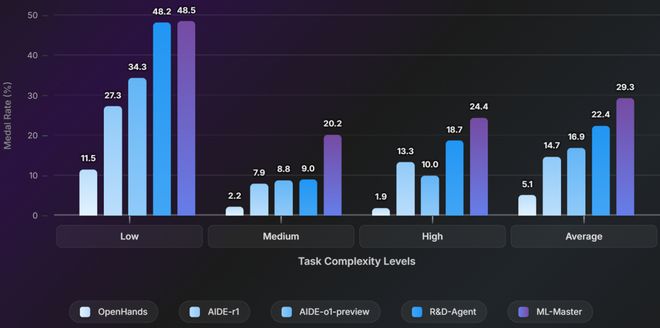
ML-Master 在不同难度级别任务中展现出压倒性优势:
-
低难度任务:48. 5%vs 48.2%,稳定领先保持优势
-
中难度任务:20. 2%vs 9.0%,2. 2 倍暴击提升
-
高难度任务:24. 4%vs 18.7%,30% 大幅超越
ML-Master 在各难度级别的领先表现体现了其卓越的泛化能力,能够在不同复杂度的挑战中保持高水平的稳定性。
持续进化,潜力巨大
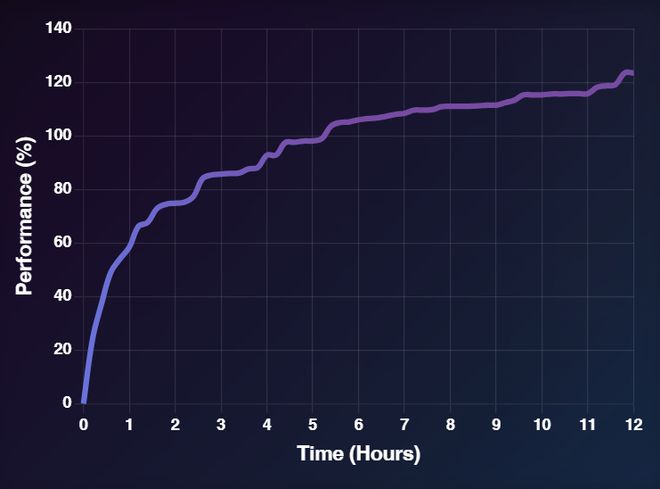
ML-Master 展现出强大的自我演进能力,在多轮任务执行过程中持续提升其解决方案质量。
与初始版本相比,最终平均性能提升超过 120%。
该系统通过动态结合探索与推理机制,实现了针对任务特性的逐步适应与优化,体现出在 AI4AI 方向上的稳步推进潜力。
解密 ML-Master
智能探索树生成全过程
通过可视化展示 ML-Master 的解决方案树生成过程,可直观看到:
-
多分支并行展开:ML-Master 同时探索多个解决方案路径
-
动态优化调整:ML-Master 根据执行反馈实时调整策略
-
智能决策收敛:ML-Master 逐步聚焦更优解决方案
这一过程展示了在性能优化中,探索与推理深度协同的关键作用。
展望未来
AI4AI 新征程
ML-Master 的突破验证了 AI4AI 的巨大潜力,其探索与推理融合的创新框架为 AI 自主开发和自我演进提供了新的方向。
在 OpenAI MLE-bench 上的领先表现为 AI4AI 技术树立了新的标杆。
当前,AI4AI 处于快速发展的初期阶段,随着技术的不断进步,AI 的智能化、效率和应用前景将持续拓展。
后续,ML-Master 也会集成在即将发布的 AI 辅助学习智能体和 AI 辅助研究智能体中。
除了推出面向机器学习的专家智能体 ML-Master,上海交通大学人工智能学院 Agents 团队后续将依托上海交通大学 AI-X 研究院,陆续推出覆盖各领域的专家智能体,构建有影响力的智能体生态体系,为人工智能技术的创新发展与广泛应用注入新动能。
上海交通大学人工智能学院简介
上海交通大学人工智能学院是上海交通大学顺应发展趋势、对接国家战略、服务城市先导产业而成立的实体学院,是举全校之力组建的特区学院。
学院通过高层次定位和全新体制机制,致力于培养中国自主的人工智能卓越人才,为国家高水平科技自立自强提供有力支撑。学院基础雄厚、生源拔尖、设施完备、条件优越,为上海交通大学百年徐汇校区注入了全新的活力。
学院秉承「用人工智能变革世界,用人才变革人工智能」的愿景,以「引育顶尖人才、产出顶尖成果、孵化顶尖企业」为目标,致力于构建全链条创新体系,打造中国人工智能领域的「黄埔军校」,引领中国人工智能发展。

人工智能学院主页:https://sai.sjtu.edu.cn
Agents 团队联系方式:sjtu.sai.agents@gmail.com
参考资料:






