
新智元报道
编辑:KingHZ
AI 编程梦被撕碎!最新研究用 57.6 万个代码样本揭示:超 20% 代码依赖的是不存在的软件包。苹果、微软都曾中招,而 Meta 和微软还在高喊「未来 AI 写 95% 代码」。AI 写代码的神话,正在变成安全灾难。
最近,扎克伯格表示,Meta 正在内部开发专门用于编程和 AI 研究的智能体——
这些并不是通用型工具,而是为提升 Meta 自家 AI 项目(如 LLaMA)量身定制的专用智能体。

他预测,在未来的12 到 18 个月内,Meta 用于 AI 开发的大部分代码将不再由人类编写,而是由 AI 智能体生成。
微软首席技术官 Kevin Scott 的预测更长远,但更大胆。
在最近的一档播客节目中,他预估在未来五年,AI 生成的代码将占据主导地位,表示道:
95% 的代码将由 AI 生成,人类完全手动编写的代码几乎一行也没有。

左:微软首席技术官 Kevin Scott;右:播客主持人 Harry Stebbings
Scott 拥有 41 年的编程经验,足以让他见证行业内的多次变革。
20 世纪 80 年代,汇编语言编程开始向高级语言编程转变,
当时,有些老程序员会说:「如果你不会写汇编语言,就不算真正的程序员,那是唯一正确的编程方式。」
如今,已经没人再提这些了。
在他看来,AI 的崛起与当年的变革并无太大不同。
Scott 认为,「最优秀的程序员」会迅速适应 AI 工具:
一开始,开发者对这些工具持怀疑态度,但现在他们的态度变成了「除非我死了,否则别想让我放弃这些工具」。
AI 已经成为他们工具箱中不可或缺的一部分。
但软件工程中,「没有银弹」:如果开发的次要部分少于整个工作的 9/10,那么即使不占用任何时间,也不会给生产率带来数量级的提高。
正如 Scott 所言:「代码的创造性和核心设计,仍然完全依赖于人类。」

论文链接:https://www.cs.unc.edu/techreports/86-020.pdf
拥有超过 25 年经验的记者 Dan Goodin,则报道了 AI 生成代码,不仅不能取代人类开发者,甚至可能对软件供应链造成灾难性影响。

AI 带来的灾难性影响
在 2025 年美国计算机安全协会安全研讨会(USENIX Security 2025)上,研究人员计划发表一篇论文,报告发现的 「软件包幻觉」现象。

USENIX Security 2025 在今年 8 月 13 日到 8 月 15 日举行
这项研究显示,AI 生成的计算机代码中充斥着对并不存在的第三方库的引用,这为供应链攻击创造了绝佳机会。
攻击者可以利用恶意软件包毒害合法程序,进而窃取数据、植入后门,以及实施其他恶意行为。

论文链接:https://arxiv.org/abs/2406.10279v3
该研究使用 16 种主流大型语言模型(LLM)生成了 57.6 万个代码样本。
结果发现,这些样本中包含的软件包依赖项里,有 44 万个是 「幻觉产物」,也就是说它们根本不存在。
开源模型的虚构依赖比例最高,生成的代码所包含的依赖项中 21% 并不存在。
新型软件攻击:软件包混淆
这些并不存在的依赖项加剧了所谓的「依赖项混淆攻击」,对软件供应链构成了威胁。
这类攻击的原理是让软件包访问错误的组件依赖项。
例如,攻击者发布一个恶意软件包,给它起一个与合法软件包相同的名字,但标注一个更新的版本号。在某些情况下,依赖该软件包的软件会选择恶意版本,而不是合法版本,因为恶意版本看起来更新。
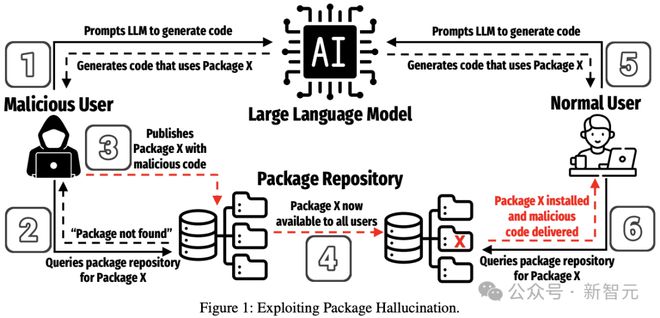
这种攻击方式,也称为「软件包混淆」,在 2021 年的一次概念验证中首次展示,成功在苹果、微软等巨头公司的网络中执行了伪造代码。

这属于软件供应链攻击,目的是污染软件源头,感染所有下游用户。
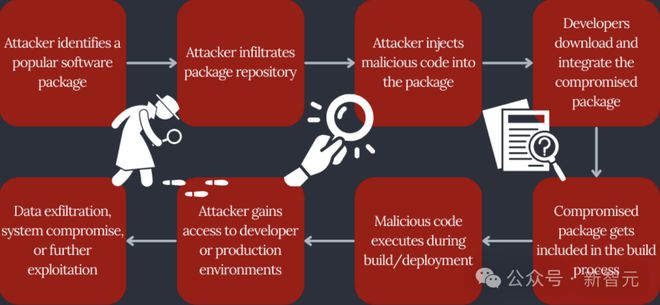
软件供应链攻击(software supply chain attack)一般步骤
该研究的主要负责人、德克萨斯大学圣安东尼奥分校的博士生 Joseph Spracklen,在给媒体的电子邮件中表示:「一旦攻击者利用虚构软件包名称发布包含恶意代码的软件包,并依靠模型向毫无戒心的用户推荐该名称,如果用户没有仔细验证就安装了该软件包,隐藏在其中的恶意代码就会在用户系统上执行。」

软件包幻觉多严重?
为了评估软件包幻觉问题的严重性,研究人员测试了 16 种代码生成 AI 模型(包括 GPT-4、Claude、CodeLlama、DeepSeek Coder、Mistral 等),使用两个独特的提示数据集,生成了 576,000 个 Python 和 JavaScript 代码样本。
结果显示,推荐的软件包中有近 20% 是不存在的。
研究发现,不同 LLM 和编程语言的虚构软件包比例差异显著。
开源模型的平均虚构比例接近 22%,而商业模型仅略超5%。Python 代码的虚构比例平均为 16%,低于 JavaScript 的 21%。
这种差异可能与模型复杂性和训练数据有关。
商业模型(如 ChatGPT 系列)通常拥有比开源模型多 10 倍以上的参数,参数量更大可能减少幻觉。此外,训练数据、微调和安全优化也可能影响虚构比例。
至于 JavaScript 虚构比例高于 Python,研究推测这与 JavaScript 生态系统中软件包数量(约为 Python 的 10 倍)和命名空间复杂性有关。
更大的软件包生态和复杂命名增加了模型准确回忆包名的难度,导致虚构比例上升。
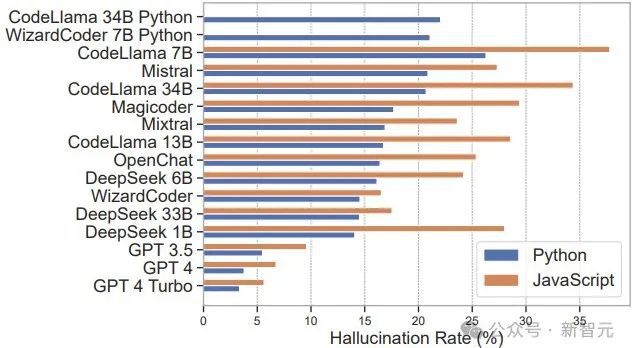
不同语言模型在 Python 和 JavaScript 代码中的幻觉率
为了验证 LLM 是否会反复幻觉相同的软件包,研究人员随机抽取了 500 个引发幻觉的提示,并对每个提示重复查询 10 次。
结果发现:
-
43% 的幻觉软件包在 10 次查询中均被重复提及;
-
39% 的幻觉软件包在 10 次查询中完全未重复;
-
58% 的幻觉软件包在 10 次迭代中被重复提及超过一次。
研究人员指出:「这表明,大多数幻觉不是随机错误,而是可重复、持续的现象。这种持久性对恶意攻击者更有价值,让幻觉攻击成为更现实的威胁。」
尽管许多模型在某些情况下能检测到自己的幻觉,但问题在于,许多开发者依赖 AI 生成代码,并盲目信任AI 的输出。
「幻觉」难以根除
在 AI 领域,当大语言模型产生的输出结果在事实上不正确、毫无意义,或者与分配给它的任务完全无关时,就会出现 「幻觉」 现象。
长期以来,「幻觉」 一直困扰着大语言模型,因为它降低了模型的实用性和可信度;而且事实证明,LLM「幻觉」 很难预测和解决。
幻觉软件包是否可能源于模型预训练数据中已删除的软件包?
研究人员调查结果发现:已删除软件包对幻觉的贡献「微乎其微」。
他们还发现了「跨语言幻觉」:某个编程语言中的幻觉软件包名称与另一种语言中存在的软件包名称相同。
而跨语言幻觉在 JavaScript 中更常见。
此外,大多数幻觉软件包的名称与现有软件包名称「实质性不同」,但这些名称往往令人信服,且与上下文高度相关。
对于使用 LLM 的开发者,研究人员的建议是:在使用 AI 推荐的代码之前,仔细检查推荐的软件包是否存在,以避免落入供应链攻击的陷阱。
开发者提高警惕和验证,可以有效降低因软件包幻觉引发的安全风险,确保代码安全可靠。
参考资料:
https://www.helpnetsecurity.com/2025/04/14/package-hallucination-slopsquatting-malicious-code/






