
新智元报道
编辑:KingHZ
DeepSeek-R1 引爆了 LLM 推理革命,人们几乎形成了共识:推理能力越强,LLM 越好。但多位华人参与的研究揭示:思维链 CoT 分散模型「注意力」,可能是性能崩塌的导火索。
DeepSeek-R1 火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!
模型很聪明,问题是:它还听你的话吗?思维链很好,但代价呢?
当大家以为大语言模型越「会思考」越靠谱时,来自哈佛大学、亚马逊和纽约大学的最新研究, 可谓当头棒喝:
思维链(Chain-of-Thought)并不总是锦上添花,
有时候,它会让大模型越想越错、越帮越忙!

论文链接:https://arxiv.org/abs/2505.11423
他们直截了当地指出:
在需要遵守指令或格式的任务中,使用 CoT 推理,模型遵守指令的准确率会下降!
例如,Meta-Llama-3-8B 在 IFEval 基准中:
-
不使用推理时准确率:75. 2%
-
启用 CoT 后:直接跌至 59.0%
而且这不是个例,在多个模型、多个任务上都验证了这个现象。
不是模型不聪明,是它「想太多」了。
在表 1 中,研究人员展示了具体的测评结果。
其中绿色与红色分别标识原始模式与CoT 模式的性能。
各改进方法列同时报告绝对准确率及相对于 CoT 模式的变化(↑表示提升,↓表示下降),最优改进方案用加粗字体标出。
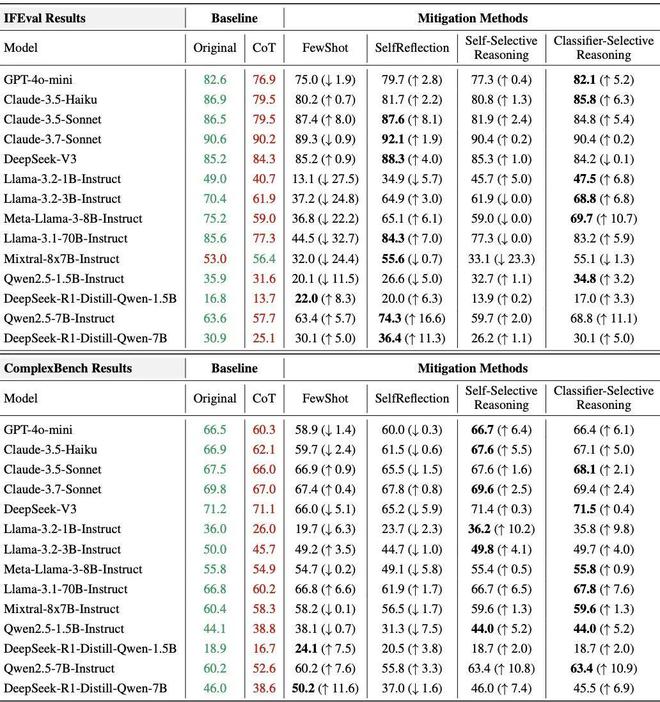
表1:模型在 IFEval 和 ComplexBench 上的指令遵循性能表现
这不是 LLM 的滑铁卢,这是推理的自爆现场。
这个新发现颠覆了常识:推理越多,表现越差!

表2:推理增强模型与基础模型性能对比
表 2 中绿色标注每对模型中性能较优模型,红色标注较差模型。
对 LLM 而言,推理到底帮了哪些忙,又添了哪些乱?
四大模式,暗藏玄机
对 IFEval 数据集中的全部 541 个样本,以及 ComplexBench 中的 1000 多个样本,研究人员进行了人工分析。
案例分析显示,虽然存在个体差异,但成功与失败案例主要呈现四大重复模式,具体总结如下:
推理对指令遵循的好处:
-
格式和结构遵守:推理提高了对结构约束的遵循程度,例如生成有效的 JSON、用双引号包裹输出或者遵循 markdown 语法。
-
词汇和关键词精确性:推理增强了对词汇要求的遵守,包括插入稀有字符(如字母q使用六次)、省略最终标点符号或使用恰好 15 个大写单词。
推理对指令遵循的害处:
-
过度关注高层次内容而忽略简单约束:当存在多个约束时,推理通常会强调内容规划而忽视较为简单的机械约束。
常见问题包括超出字数限制、未能准确重复提示、在仅限小写字母的任务中使用大写字母,或附加不必要的内容。
-
自作聪明,画蛇添足,擅自加戏:推理经常插入冗余或出于好意添加的内容——比如解释、翻译或强调——这些都可能破坏约束条件。
典型的行为包括:在「仅外语」输出中插入英文文本,在「无逗号」任务中包含逗号,向仅需引用的回答后附加评论,或超出大写单词数量的限制。
总结一句:你要它听话,它偏偏表演。
真相:CoT 分散模型「注意力」
在许多失败案例中,研究者观察到模型忽视了某些约束,原因可能是过度强调内容规划,或引入了无关的信息。
研究者引入了一个新指标:「约束注意力」,来衡量模型有没有关注任务中的关键限制条件。
结果很扎心:
-
DeepSeek-R1-Distill:使用 CoT 时注意力下降0. 161
-
Qwen2.5-1.5B-Instruct:下降0. 090
CoT 推理就像在耳边说「要不你再想想?」
模型真的「想多了」,但忘了你原本说了什么。
注意力溃散
在大语言模型中,「注意力机制」,用来决定模型在每一步生成中关注哪些输入信息最重要。
理想情况下:
如果你让模型执行「按要求格式输出」「只输出选项A或B」,那它的注意力就应该聚焦在指令里的关键约束词上,比如「必须输出A或B」「不得添加解释」。
然而,CoT 推理的引入却改变了这种聚焦机制:
当你让模型「一步步来思考」(即 CoT)时,它反而会被自己的推理内容吸引,逐渐忽略最开始的指令约束。
这就好比:
模型本该「盯着规则干活」, 但你让它「先思考思路」,它反而被自己的「内心独白」带偏了。
你给它一张待办清单,它却跑去写日记,写着写着忘了要办啥。

实证支持:「约束注意力」下降
论文中引入了一个衡量指标:约束注意力得分。
具体来说,对于每条指令,首先使用 GPT-4o 自动提取出与各个约束对应的子字符串,并将这些子字符串映射为提示中的对应 token 索引。
在生成过程中,计算模型对这些约束相关 token 的注意力得分,分别针对性分析了推理过程和最终回答两个阶段,计算第t步的层平均约束注意力。
每个模型在每条指令上会运行两次:
1. 基础运行(Base run):直接从指令生成回答(Instruction→Answer);
2. 推理运行(Reasoning run,即 CoT):从指令生成思考过程再生成回答(Instruction→Think→Answer)。
研究人员将注意力下降量定义为基线模式与思维链模式的平均约束注意力差值,用来量化模型在执行任务时,有多少注意力落在了那些「必须遵守」的关键词或结构限制上。
在 IFEval 和 ComplexBench 基准上,在图 1 中可视化了某开源模型生成响应时的约束注意力轨迹。
通过对数百个样本的分析,研究者观察到以下普遍规律:
注意力平坦化现象。
推理过程会使约束注意力轨迹趋于平缓;在性能下降的案例中,答案生成阶段的约束注意力普遍降低约 23%。
注意力增强现象。
当推理提升性能时,答案段会出现明显的注意力峰值(平均提升 15%);这种增强与关键约束的准确识别呈正相关(r=0.62)。
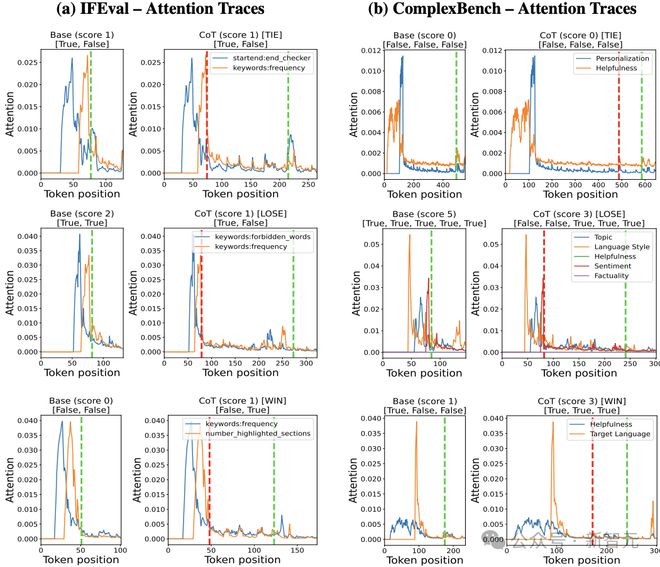
图1:Qwen2.5-1.5B-Instruct 模型在两个数据集上的约束注意力轨迹示例。自上而下分别展示推理导致持平(TIE)、失败(LOSE)和成功(WIN)三种情况的对比。红色虚线标记思维过程(Thinking)的开始位置,绿色虚线标记答案生成(Answer)阶段的起始点
当使用 CoT 推理时,多款主流模型的这个分数显著下降:
-
DeepSeek-R1-Distill:下降0. 161
-
Qwen2.5-1.5B-Instruct:下降0. 090
这意味着:模型确实更少关注任务限制,更容易出错,比如加了不该加的标点、解释、格式错位等。
图 2 展示了在「成功」(WIN)与「失败」(LOSE)两类样本中,这种注意力下降在不同。
数据显示,与未使用推理的情况相比,失败案例的注意力下降幅度普遍更为显著。
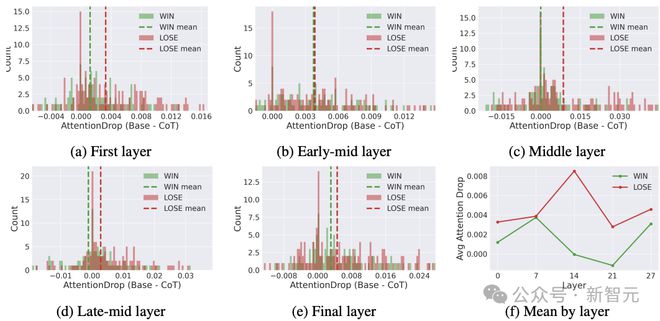
图2:Qwen2.5-1.5B-Instruct 模型在 IFEval 数据集中,WIN(成功)与 LOSE(失败)案例在各典型层的约束注意力下降值(基线-思维链模式)
论文还发现:推理步骤越多,指令遵循能力越差;两者间的相关性几乎为0,长推理≠高表现!
换句话说,CoT 不是写论文,不是越长越有用,反而可能「越写越偏」。
如何解决?4 种缓解策略来了!
改进方法
基于这些发现,研究人员提出四种改进方案:
上下文学习:通过典型错误示例修正推理偏差,带来了小幅度的性能提升;
自我反思:引导模型对推理过程进行自检。在 IFEval 数据集上,自我反思带来了显著提升;ComplexBench 数据集上,效果较差。
自选择推理:让模型自主判断是否需要推理。在 IFEval 上,它带来了中等程度的提升;在 ComplexBench 上表现更为出色,所有模型性能均有提升。
分类器选择推理:用训练好的分类器控制推理触发。
该方法效果显著,几乎在所有模型和两个基准测试上都带来了性能提升,但需要针对每个模型单独训练分类器,这会增加额外的开发和运维成本。
每种缓解策略在不同的模型能力和任务复杂度下都有其优缺点。
根据结果,研究者推荐如下决策流程:
-
首先评估任务指令的复杂度——可以通过简单的启发式规则或训练好的分类器来判断;
-
对于较简单的任务(如 IFEval),推荐使用自我反思或分类器选择推理;
-
对于更复杂或逻辑结构更复杂的任务(如 ComplexBench),推荐使用自我选择推理或分类器选择推理。
总体而言,分类器选择推理在两个基准测试中都表现出最稳定和最优秀的性能,尽管它需要进行模型特定的训练。
详细结果见表 1 和图3,其中也包括与 CoT 基线的性能差异对比。
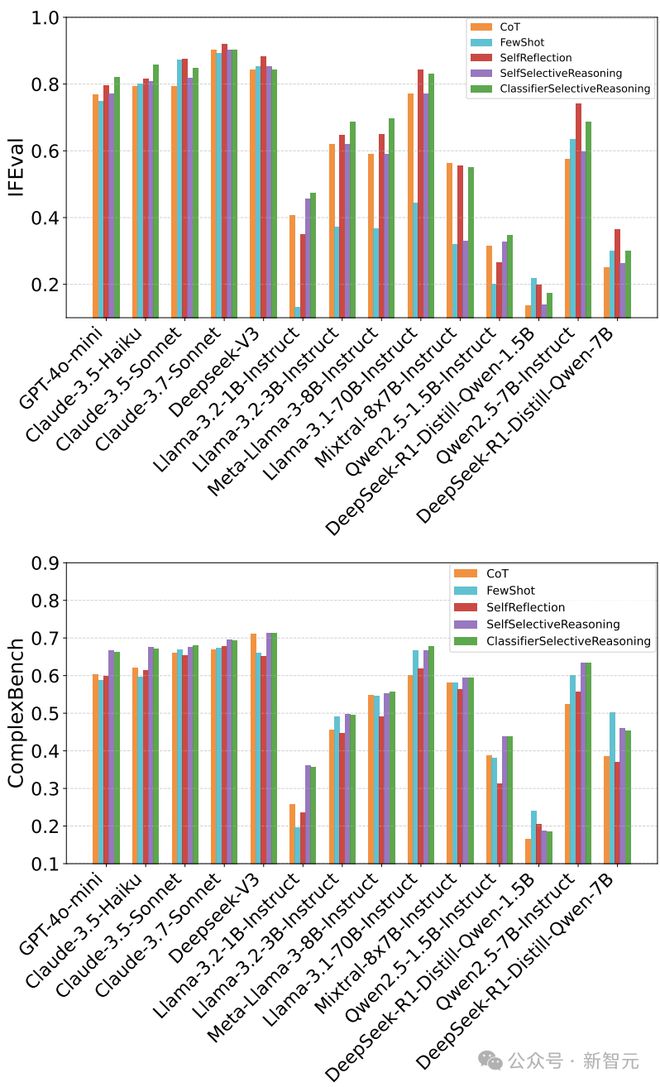
图3:跨模型与方法的指令遵循准确率可视化分析(基于 IFEval 与 ComplexBench 基准)
给 AI 开发者的几点提醒
不是所有任务都需要推理:简单任务/格式明确的输入,直接输出即可。
明确提示中的规则:不要让模型在推理时「模糊掉」关键限制。
引入判断机制:让模型或分类器判断是否需要推理。
大模型的「聪明」,该被约束。
在 AI 开发中,大家喜欢「聪明」的模型,但真正的智能不是乱想,而是:
知道什么时候该想,什么时候该闭嘴。
思维链依旧重要,但不是万能钥匙。我们需要重新理解它的边界与风险。
作者介绍
值得一提的,论文的第一作者兼通讯作者 Xiaomin Li。

他目前在哈佛大学攻读应用数学博士学位。
他的研究方向是机器学习与生成模型的数学理论,以及大语言模型的应用等。
2020 年 5 月,他以满绩点的优异成绩,获得伊利诺伊大学厄巴纳-香槟分校数学理学学士与计算机科学工程学士双学位。
同年,他于哈佛大学攻读博士学位,期间他有多段 Meta 等公司的实习经历。
参考资料:






