
梦晨发自凹非寺量子位公众号 QbitAI
Meta 最新基础模型 Llama 4 发布 36 小时后,评论区居然是这个画风:
失望,非常失望不知道他们后训练怎么搞的,总之不太行
在[各种测试]2 中失败

还被做成表情包调侃,总结起来就是一个“差评如潮”。

具体来看,大家的抱怨主要集中在代码能力。
最直观的要数经典“氛围编程”小球反弹测试,小球直接穿过墙壁掉下去了。

反映在榜单上,成绩也相当割裂。
发布时的官方测评(LiveCodeBench)分数和在大模型竞技场表现明明都很不错。
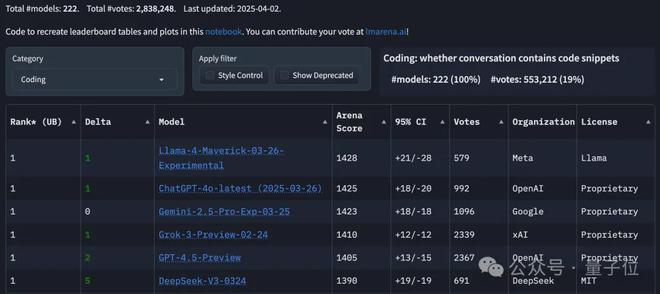
但到了各种第三方基准测试中,情况大多直接逆转,排名末尾。
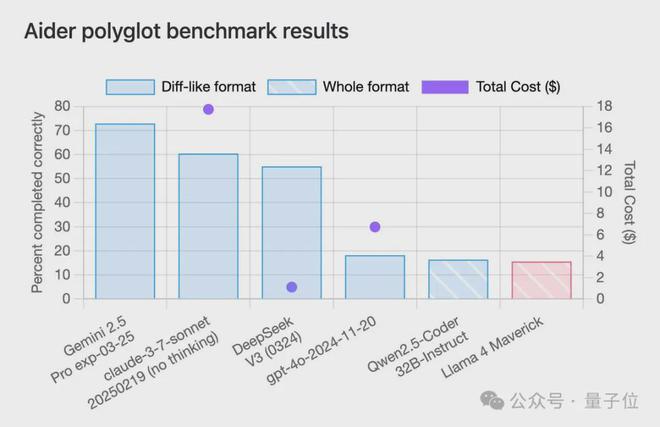
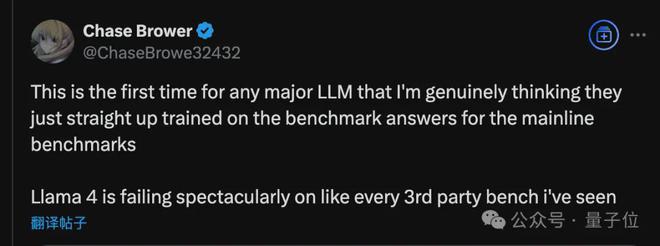
让人不由得怀疑,这个竞技场排名到底是数据过拟合,还是刷票了。
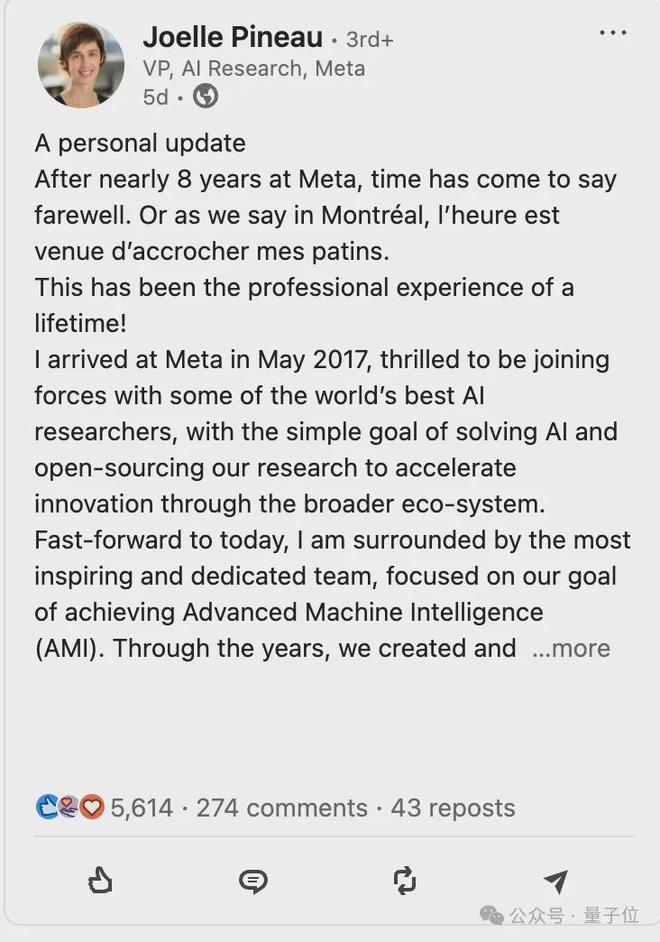
就在 Llama 4 即将发布前几天,Meta AI 研究主管 Joelle Pineau 在工作 8 年之后突然宣布离职,总之就是不太妙。
Llama 4 怎么了?
大模型关注者们火热实测吐槽之际,一则有关 Llama 4 的匿名爆料,突然引起轩然大波:
有网友称自己已向 Meta GenAI 部门提交提交辞职,并要求不要署名在 Llama 4 的技术报告上。
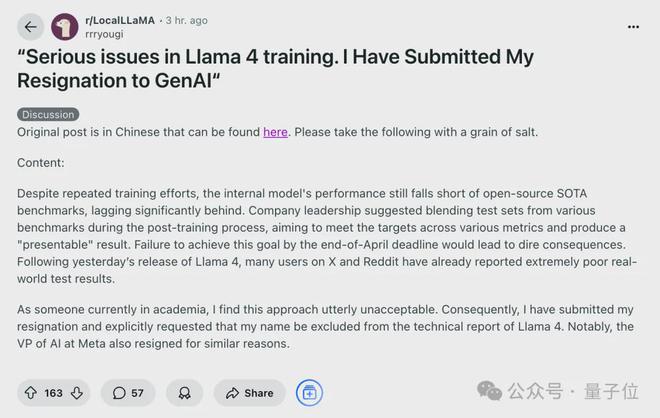
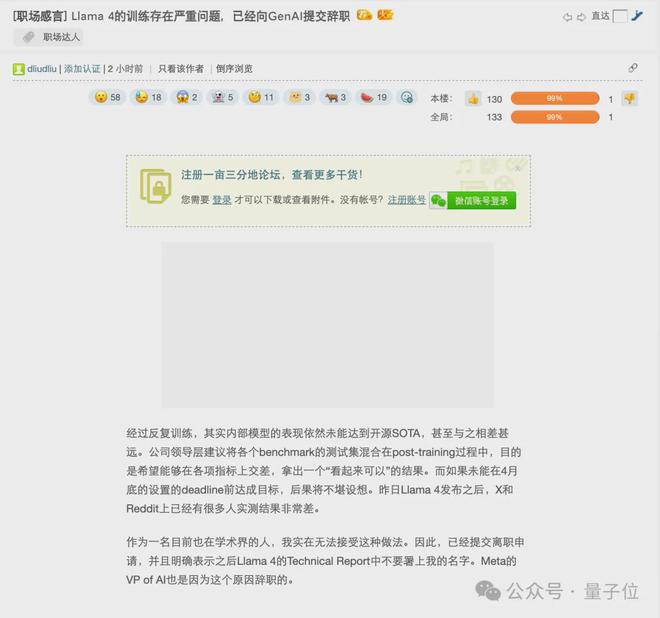
原贴发布在海外留学求职交流平台一亩三分地,在国内也引起很多讨论。
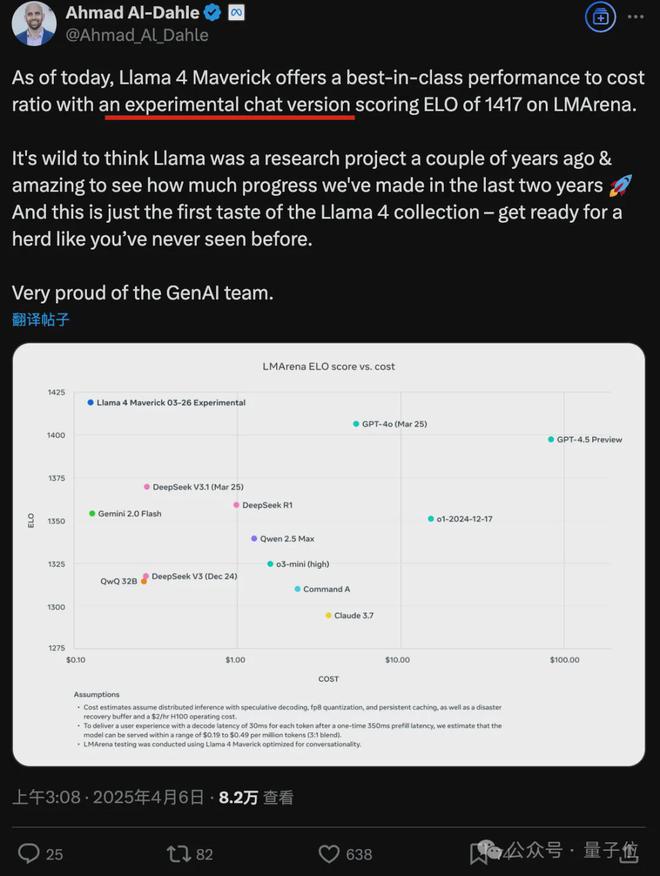
此爆料尚未得到证实,但有人搬出 Meta GenAI 负责人 Ahmad Al-Dahle 的帖子,至少能看出在 Llama 4 大模型竞技场里运行的是特殊版本模型。
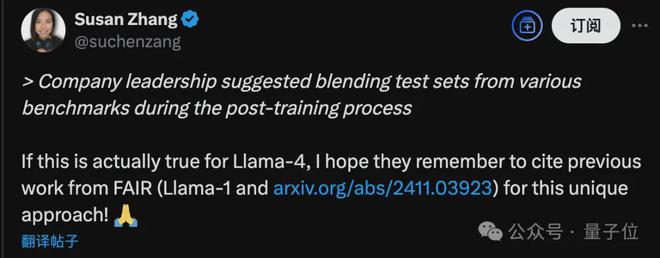
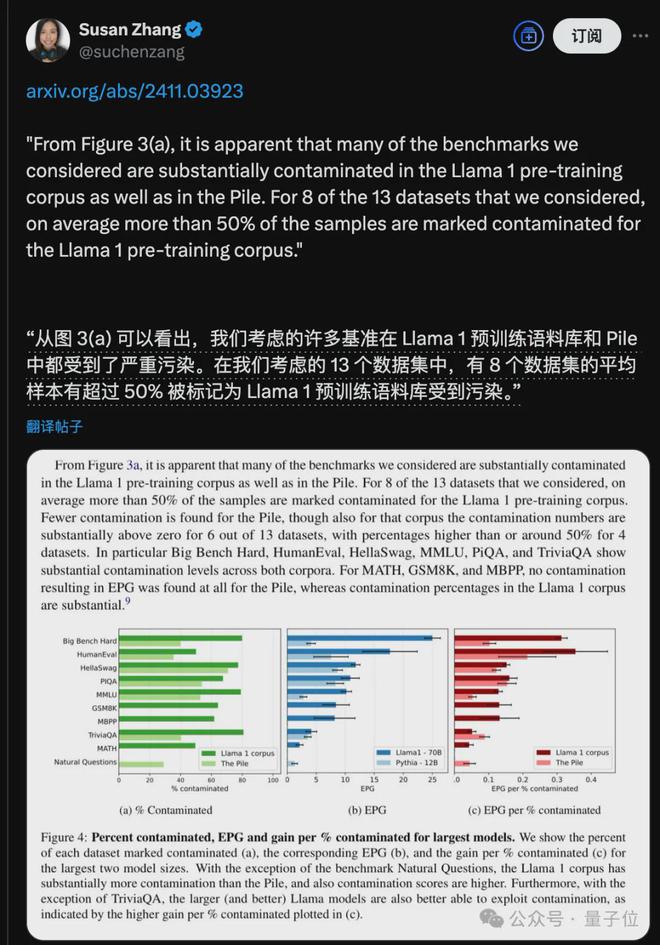
还有 Meta 前员工借此话题贴出 2024 年 11 月的一项研究,指出从 Llama 1 开始数据泄露的问题就存在了。
也不只是编程能力一个方面有问题,在 EQBench 测评基准的的长文章写作榜中,Llama 4 系列也直接垫底。
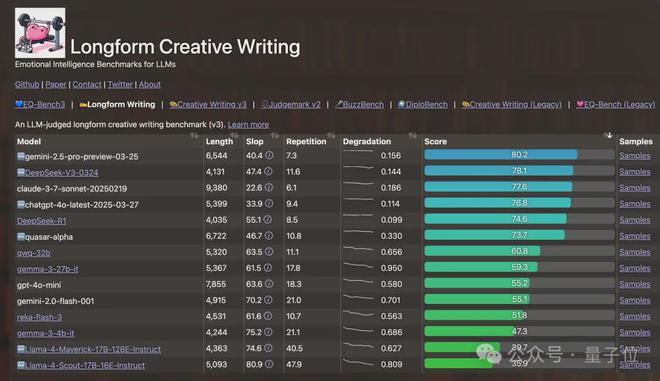
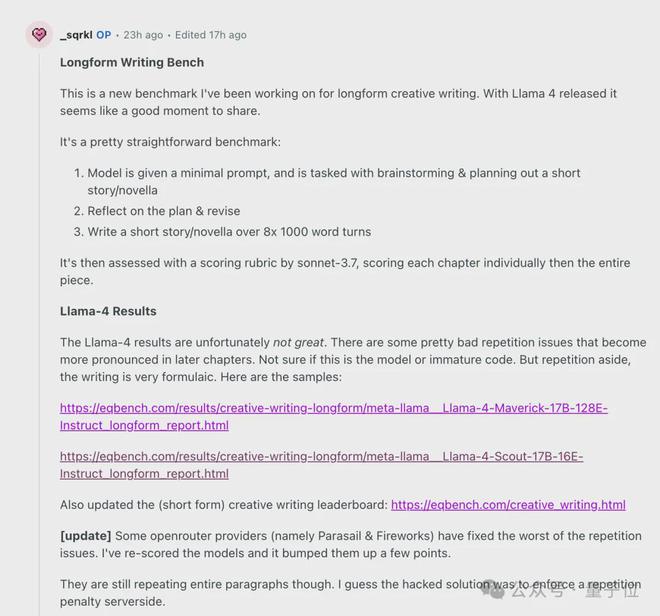
榜单维护者_sqrkl 说明了具体情况。
测试非常简单,模型需要先完成一个短篇小说的头脑风暴、反思并修改写作计划,最终每轮写 1000 字,重复 8 轮以上。
由 Claude-Sonnet 3.7 来当裁判,先对每个章节单独打分,再对整个作品打分。
Llama 4 的低分表现在写到后面开始大段的内容重复,以及写作非常公式化。
对此结果,有一个猜想是之前的版权诉讼让 Meta 删除了网络和书籍数据,使用了更多的合成数据。
在这场诉讼中,许多作家发现自己的作品可能被用于 AI 训练,还到伦敦的 Meta 办公室附近发起抗议。

Llama 4 发布后的种种,让人联想到年初的匿名员工爆,有网友表示当初只是随便看看,现在却开始相信了:
在这条爆料中,Deepseek v3 出来之后,训练中的 Llama4 就显得落后了,中层管理的薪水都比 DeepSeek V3 的训练成本都高,Meta 内部陷入恐慌模式。
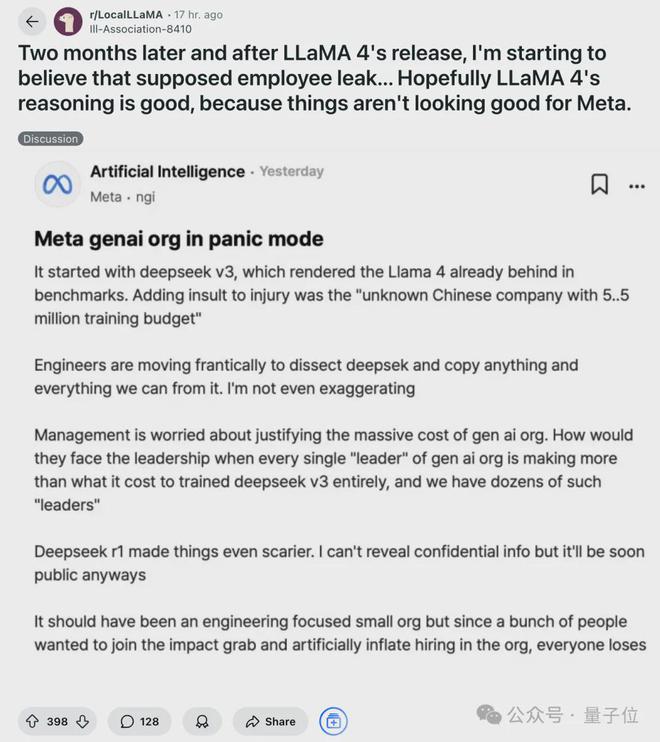
让人不由得感叹,DeepSeel-R1 横空出世仅仅两个月时间,却像过了几辈子。

[1]https://www.reddit.com/r/LocalLLaMA/comments/1jt7hlc/metas_llama_4_fell_short/
[2]https://www.1point3acres.com/bbs/thread-1122600-1-1.html






