
新智元报道
编辑:桃子英智
AI 界「智商大考」ARC-AGI-2 重磅出炉了!一个人类用 5 分钟轻松解开的谜题,却让最顶尖 LLM 全线崩盘得分挂零,o3 更是从曾经 76% 暴跌至4%。它正式宣告,人类还未实现 AGI。
时隔 6 年,ARC-AGI-2 正式推出!
一大早,Keras 之父 François Chollet 官宣了全新迭代后的 ARC-AGI-2,再次拉高了 AI「大考」的难度。

这些对人类再简单不过的题目,LLM 最先败北,先上结果:
基础大模型(GPT-4.5、Claude 3.7 Sonnet、Gemini 2 ),全部得 0 分。
CoT 推理模型(Claude Thinking、R1、o3-mini),得分也不过4%。

相较之下,2024 年 ARC Prize 冠军模型(53.5%)却在新版本考试中,成绩仅剩 3.5%。
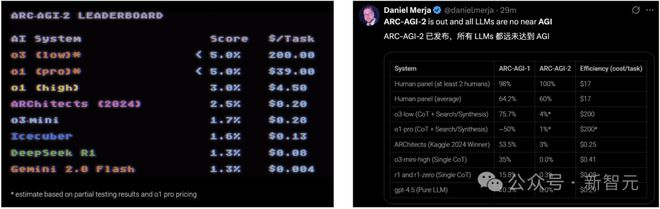
OpenAI 的 o3-low 模型也从 75.7% 骤降至4%。而且,每项任务成本效率也是 o3-low 和 o1-pro 最高,达到 200 美金。
相反,在 ARC-AGI-2 里的每个任务,都至少有两名人类能在两次尝试内成功解决。
ARC-AGI-2 的出世,证明了「人类尚未实现 AGI」!

现场 400 人实测,普通人无训练能拿下 60% 准确率,10 人小组能达到 100%
初代 ARC-AGI(2019 年),曾在去年揭示了 AI 重大转变,LLM 从「纯记忆」向「测试时推理」的进化。
许多之前一眼就看透的问题,在 ARC-AGI-2 中,至少需要几分钟的深思熟虑——人类测试者平均需要 5 分钟才能解题。
最新 ARC-AGI-2,恰恰暴露了当前 AI 三大短板:符号解释、组合推理、上下文规则应用。
这些皆需要 LLM 在测试时,展现真正的适应能力,具备灵活应对新问题的「流体智力」,而不是靠预训练数据「硬背」过关。
值得一提的是,2025 年 ARC 奖本周将在 Kaggle 平台上线,总奖金高达 100 万美元。
今年的竞赛在去年基础上再加码,计算资源翻倍,旨在推动开源项目发展,助力打造能战胜 ARC-AGI-2 的系统。
AI「大考」难度进阶,AGI 梦碎?
其他 AI 基准测试,基本都聚焦于测试「博士以上水平」的技能,来考察超越人类的能力或专业知识。
但 ARC-AGI 关注的是对人类相对容易,对 AI 却困难重重的任务。
这样一来,就能精准定位那些不会因为规模扩大就自动消失的能力差距。
ARC 奖将此融入对 AGI 的衡量标准:对人类容易、对 AI 困难的任务之间的差距,即「人机差距」。
当这个差距变为零,也就是不存在能难倒 AI 的任务时,我们就实现了 AGI。

要弥补这些能力差距,需要全新的见解和思路。ARC-AGI 不只是衡量 AGI 的进展,更重要的是激励研究人员探索新思路。
AI 系统在不少特定领域(如围棋、图像识别)已超越人类。但这些只是狭隘、专门的能力。
「人机差距」揭示了 AGI 所欠缺的部分:高效获取新技能的能力。
ARC-AGI-2 登场,基础 LLM 挂零
今日正式发布的 ARC-AGI-2 基准测试,在对人类难度不变的前提下,极大提高了对 AI 的难度挑战。
在一项有 400 人参与的对照研究中,ARC-AGI-2 的每个任务,都至少有两名参与者能在两次或更少的尝试内解决。
这和给 AI 设定的规则一致,每个任务 AI 都有两次尝试机会。
与 ARC-AGI-1 类似,ARC-AGI-2 采用「两次尝试通过(pass@2)」的评估体系,因为部分任务存在显著的模糊性,需要两次猜测来消除歧义,同时也用于排查数据集中可能无意出现的模糊或错误之处。
经过人类测试,相较于 ARC-AGI-1,作者对 ARC-AGI-2 任务质量更具信心。
以下是 ARC-AGI-2 的官方更新内容:
-
所有评估集(公开、半私有、私有)的任务数量从 100 个增加至 120 个。
-
剔除了评估集中易受暴力搜索破解的任务,即 2020 年原始 Kaggle 竞赛中已被解决的所有任务。
-
开展人类测试,以校准评估集难度,确保任务独立同分布,并验证至少有两名人类可在两次尝试内解决任务,这与对 AI 的要求一致。
-
根据研究成果,设计了新任务来挑战 AI 推理系统,涵盖符号解释、组合推理、上下文规则等多个方面。
2019 年推出的 ARC-AGI-1,主要是为了挑战深度学习,尤其是防止模型单纯「记忆」训练数据集。

ARC-AGI 包含一个训练数据集和多个评估集,其中私有评估集用于 2024 年 ARC 奖竞赛。训练集的作用是让模型学习解决评估集中任务所需的核心知识。
为了完成评估集中的任务,AI 必须展现出适应全新任务的能力。
打个比方,训练集就像是教你认识小学算术符号,而评估集则要求用这些符号知识去解代数方程。你不能靠死记硬背得出答案,必须把知识灵活运用到新问题上。
ARC-AGI-2 对 AI 的要求更高,要想战胜它,必须具备高度的适应性和高效性。
下面是 ARC-AGI-2 的示例任务,满足两个条件:一是至少有两名人类能在两次尝试内解决;二是所有前沿 AI 推理系统都无法解决。
符号解释
前沿 AI 推理系统在处理需要赋予符号超出视觉模式意义的任务时,表现欠佳。
系统能进行对称性检查、镜像、变换,甚至识别连接元素,但就是无法理解符号本身的语义。

组合推理
AI 推理系统在处理需要同时应用多个规则,或者应用相互关联规则的任务时,困难重重。
相反,要是任务只有一两条全局规则,这些系统就能发现并运用规则。

上下文规则应用
AI 推理系统在面对需根据上下文灵活应用规则的任务时,也会陷入困境。
它们往往只关注表面模式,无法理解背后的选择原则。

两人组队拿满分,o3 仅4%
ARC-AGI-2 由以下数据集构成:

校准指的是这些任务具有独立同分布(IDD)特性。理论上,在公开、半私有和私有评估集上,未出现过拟合情况的分数应具有直接可比性。
为收集相关数据,在严格受控的环境下,对 400 多位人类进行了测试。
接下来几周,公开任务的人类可解性数据将与 ARC-AGI-2 论文一同发布。
对所有公开的 AI 系统重新评估,ARC-AGI-2 起始分数如下:

带*的分数,是根据目前收集到的部分结果,还有 o1-pro 的定价估算出来的。完整结果一出来,马上会公布。
所有分数均按照「两次尝试通过(pass@2)」标准,且基于半私有评估集得出(ARC-AGI-1 人类小组和 ARChitects 除外,分别基于公开评估集和私有评估集)。
人类小组的效率计算基于 115-150 美元的到场费用,外加解决每个任务奖励 5 美元。
对成本进行了优化以提升到场率(实际到场率为注册人数的 70%)。尽管人类智能成本效率的极限可能在每个任务2-5 美元区间,但基于实际收集的数据,报告中每个任务 17 美元。
等 OpenAI o3 low/high 的 API 开放,将对其正式版本进行测试。
用从 ARC-AGI-1 转到 ARC-AGI-2 的任务进行预估,o3-low 得分约为4%,如果计算量特别大(每个任务数千美元),o3-high 得分有望达到 15-20%。
智能并非仅是能力
从现在开始,所有 ARC-AGI 的报告都将附带一项效率指标。
首先选择成本作为指标,因为在对比人类与 AI 性能时,成本具有最直接的可比性。
智能并非仅是解决问题和获取高分的能力。获取和运用这些能力的效率,是智能的关键要素。
核心问题不仅在于「AI 能否掌握解决任务的技能?」,更在于「以怎样的效率或成本来掌握?」
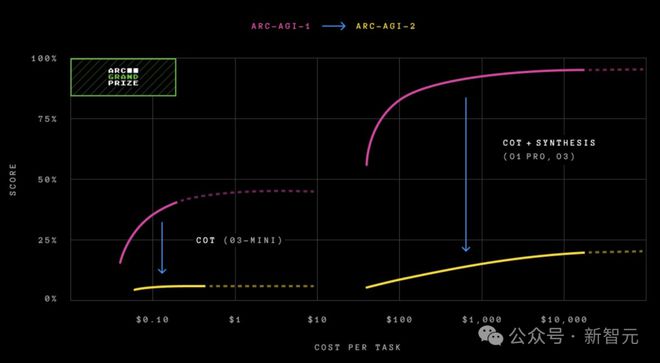
前沿 AI 系统在 ARC-AGI-1 与 ARC-AGI-2 上的得分
仅靠规模远远不够
在资源与搜索时间不受限的情况下,暴力搜索最终能够解决 ARC-AGI 问题。
但这绝非真正的智能。智能在于高效地找到解决方案,而非盲目穷举。
关注效率是 ARC-AGI 的核心原则。
明确量化智能的成本,要求解决方案不仅展示能力,更要展现对资源的高效利用,这才是 AGI 的本质。
全新的 ARC-AGI 排行榜页面将从分数和成本两个维度同步呈现。

截至 2025 年 3 月 24 日,ARC-AGI 新排行榜同时展示分数与效率
本周竞赛盛大开启!
随着 ARC-AGI-2 的发布,2025 年 ARC Prize 重磅回归!竞赛将于 3 月至 11 月期间在 Kaggle 平台举办。
竞赛设有 12.5 万美元的保底进展奖,以及高达 70 万美元的大奖,团队得分超过 85% 即可解锁!
此外,还有 17.5 万美元的奖项待后续公布细则。
Kaggle 竞赛规则禁止使用互联网 API,每次提交仅可使用约 50 美元的计算资源。
为获取获奖资格,参赛者需在竞赛结束时开源解决方案。
去年的竞赛成果斐然,超过 1500 支团队踊跃参与,产出了 40 篇极具影响力的研究论文。
获奖研究人员提出的创新理念已在 AI 行业得到广泛应用。
参考资料:
https://x.com/arcprize/status/1904269307284230593
https://x.com/fchollet/status/1904265979192086882
https://arcprize.org/blog/announcing-arc-agi-2-and-arc-prize-2025






