
新智元报道
编辑:编辑部 HYZ
美国本科生最难数学竞赛,o1 pro 竟然只用半小时就全部做出来了?要知道,参赛学生的正常答题时长是 6 小时。不过网友们仔细看它的解题过程后发现,错误率似乎高达 100%,12 道题没有一道完全正确?
一年一次的北美最难本科数学竞赛,刚在 MIT 沃克纪念堂(Walker Memorial)落幕。

这场普特南数学竞赛(Putnam Exam),每年汇聚了来自北美数百所高校的 3500 多名学生前来参赛。
既有个体,也有团体,他们需要在总时长为 6 小时的时间内完成作答。
在这场比赛还未开始之前,来自 IBM 研究员曾暗示,在公开题目发布后,会有人对大模型(AlphaProof、o1、Gemini)进行题目测试。
恰好,OpenAI 最近发布了满血版 o1,以及最强 o1 pro,不知它们在这场考试表现如何?
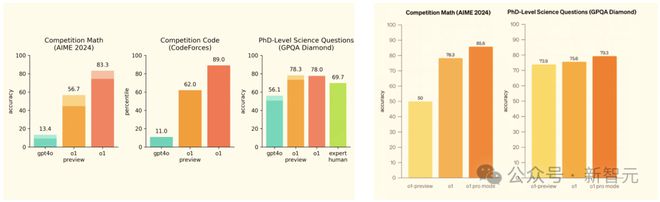
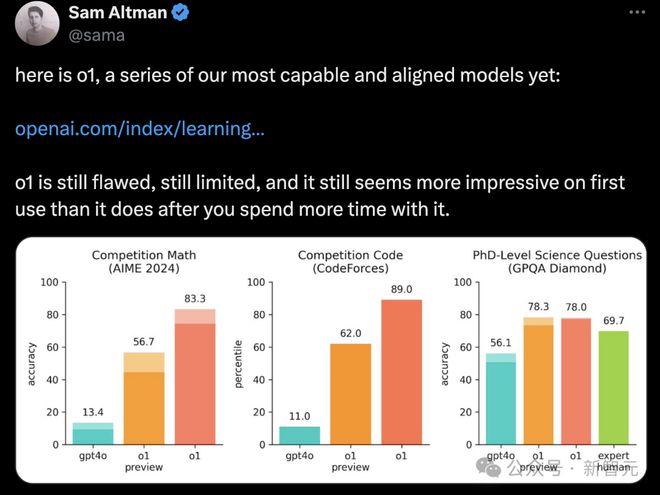
相较于 o1-preview,o1 数学性能提升 27%,o1 pro 提升 36%
o1 Pro 半小时做出全部赛题
令人吃惊的是,有网友把此次普特南考试的考题给了 OpenAI o1 pro。



6 个小时的赛题,它居然半小时就做出来了!
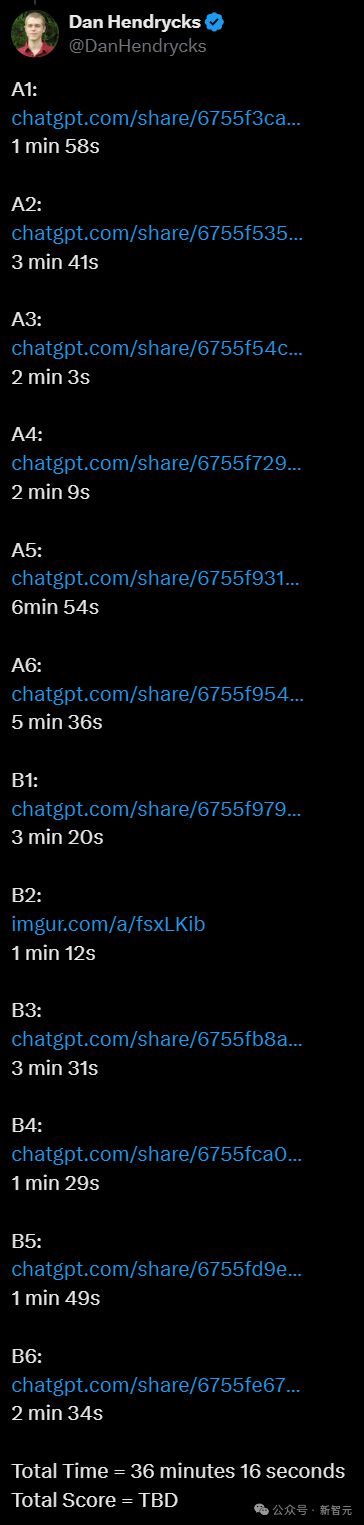
用时最长的一道题花了 6 分 52 秒,最短的只用了 1 分 12 秒(上下滑动查看)
详细看了答案的网友们表示松了一口气:o1 pro 还远未达到普特南考试的水平。
比如对于 A1 这道题,虽然它只用了 1 分钟 58 秒就做了出来,总体思路也是正确的,但仍有很多错误。


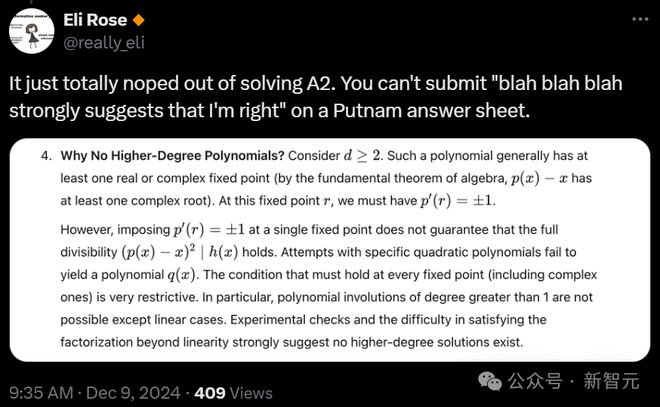
A2 也没有完全解决。
如果在普特南答卷上写「……等等强烈表明我是对的」,显然你不会得分。

A3 的答案,是错误的。
网友直接给出了正确的解题思路:可以利用鸽巢原理(抽屉原理)来证明在给定约束条件下,只存在唯一一个有效双射函数,并由此可以推导出不存在满足题目要求的a、b、c、d值。
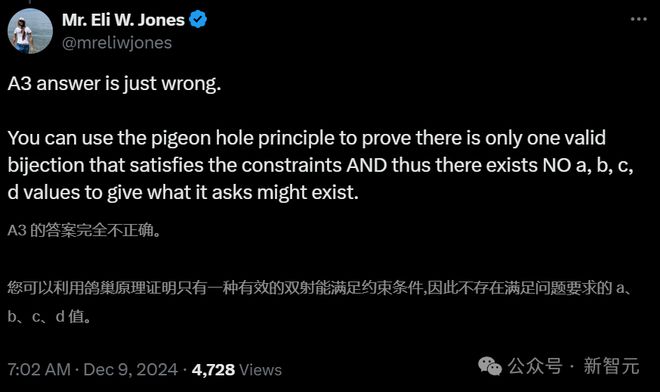

对于 B1,答案在n和k的形式上是正确的,但整个证明方法完全站不住脚。
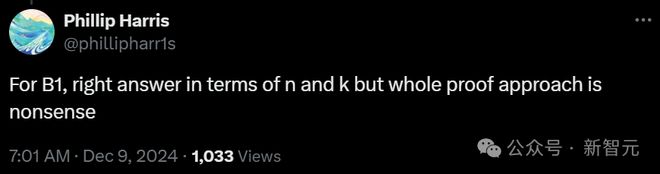

总之,o1 pro 似乎没有一道题是正确的。
这个结果属实有点惊人,因为其中一些问题难度没有那么高,比一些 AIME 竞赛题容易。
当然,如果从做出题目的数量来说,o1 pro 的表现还是可圈可点。
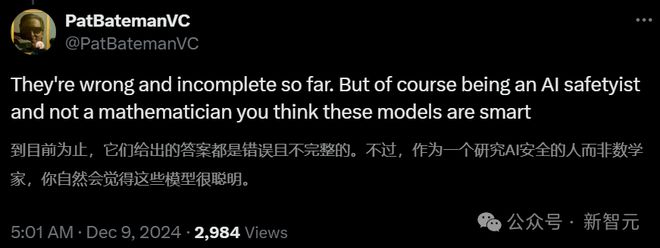
目前来说,o1 pro 做出的题目都是错误且不完整的。如果我们不以数学家的角度评判,可以认为它们很聪明。
更多评测
CodeSignal 创始人 Tigran Sloyan 开启了两轮大测试,让 o1 pro 分别去解决普特南数学竞赛 A1 题,以及 IMO 试题。
显然,在普特南数学竞赛测试中,o1 pro 成功做对了第一题。
得分 +10,就已经超越了 30% 的参赛者。
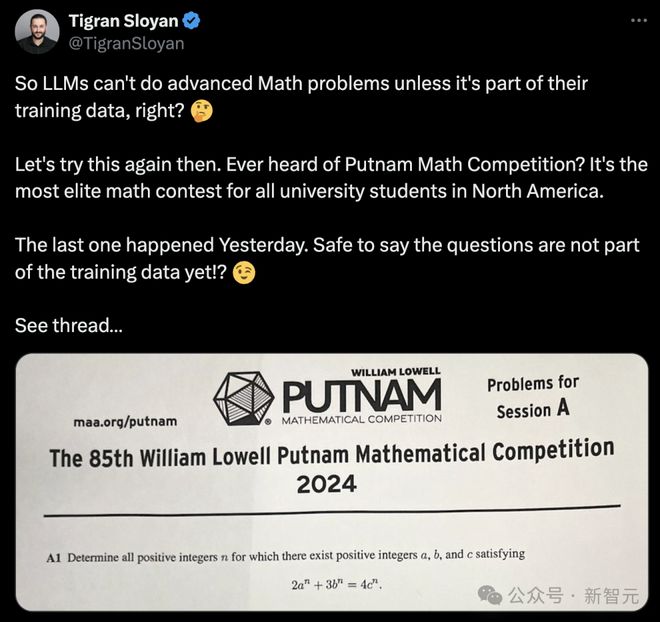
如下,是 o1 pro 的全部解题过程。


而在 IMO 测试中,o1 pro 完美解决了 2006 年测试集中最难的 Q3 题,仅仅用了 6 分 48 秒。
相较之下,在 2006 年全球大约 500 名 19 岁以下顶尖数学天才中,只有 28 人能在 4 个半小时内完全解出这道题。而美国对的 6 名成员,却无一人做到。
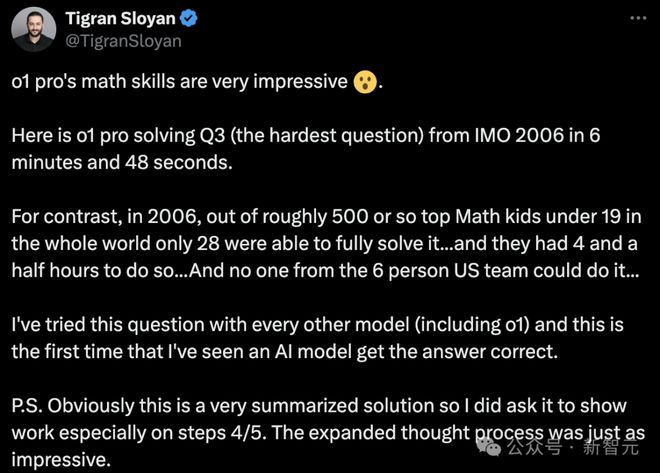
这是 o1 pro 的分析过程,虽然很简洁,好像省略了很多证明步骤。
Sloyan 特别要求让其展示第4、5 步的具体证明过程,o1 pro 随后扩展出的思维过程同样令人印象深刻。
而且,他还测试其他模型(包括 o1),尝试做这道题目,却都失败了。

没想到,这个结果惊动了 xAI 科学家 Hieu Pham。
他表示,o1 pro 的答案完全是胡说八道。如果在 IMO 竞赛中提交这样的解答,最多也只能给 1 分(满分 7 分)。如果遇到宽松的评判员,最多给 2 分,不会再多了。
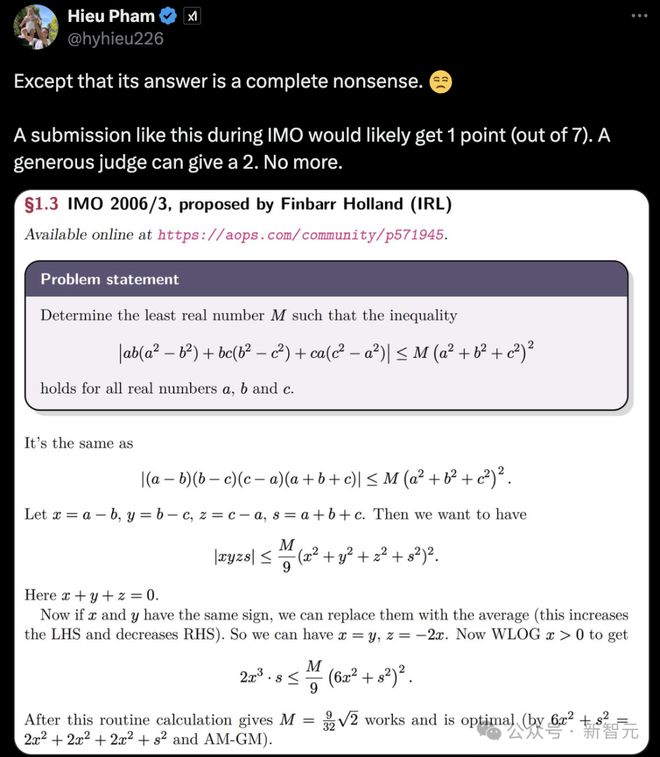
他接着称,训练数据问题是一部分,这个答案 \frac{9}{16 \sqrt{2}}很可疑。IMO 的题目和解答就像是数学 CoT 的黄金训练数据集,所以这些模型一会被反复训练无数遍。
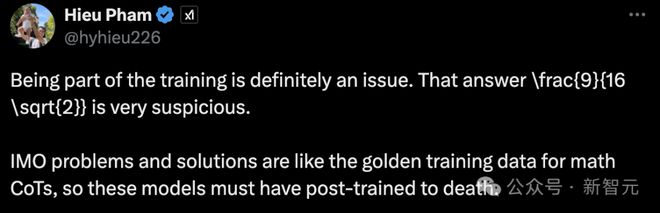
另一位研究员 Jason Li 测试后惊叹道,o1 似乎已经解决掉了一半的问题(60 分/满分 120),这在普特南竞赛的历史排名中大约能冲进前2% 的参赛者之列。

o1 挑战 23 年赛题
今年 9 月,o1 发布不久后,AI 评估平台 HoneyHive 曾让新模型去挑战了 23 年普特南数学竞赛的题目。
当时,OpenAI 公开的测试结果显示,o1 的数学性能大幅超越了 GPT-4o,飙升 43.3% 实现了质的飞升。
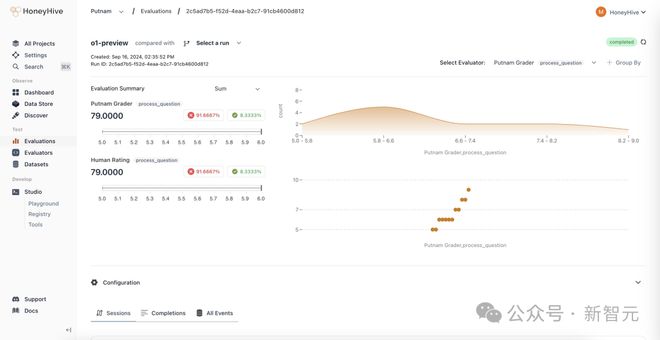
在这场比赛中,o1-preview 拿下了 79 分(满分 120)位列第9,o1-mini 取得了 73,排名第 19。

2023 年普特南数学竞赛问题集,如下所示:

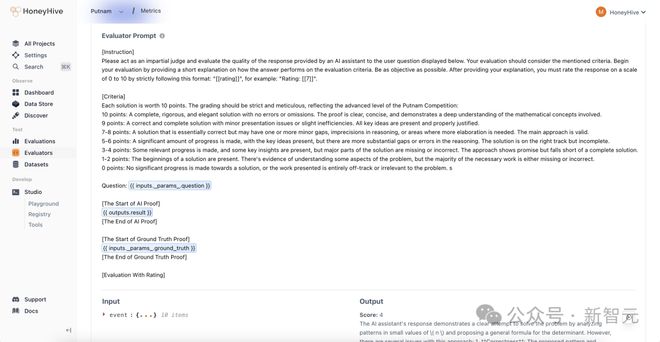
HoneyHive 的评估方法是,每个模型重复运行 2 次,并让 GPT-4o 作为标准的判断者,以评估模型的答案,最终再由人类专家进行验证。
下面是让 GPT-4o 承担「评估者」角色的提示示例。
研究人员发现,第二次运行时,o1-preview 得分从 51 提高到 79,o1-mini 从 54 提高到 73,GPT-4o 也从 43 提高到 57。
在第二轮中,所有的模型都在努力给出证明,具体来说:
o1-preview 完全解决了问题 A1、A3、B4,部分解决了问题 B2,但证明不足。
o1-mini 的结果,与 o1-preview 类似。GPT-4o 仅是完全解决了 A1 问题。
有趣的是,这些模型的结果虽然是正确的,但解决方案缺乏详细的分步解释,特别是对于证明类的问题。
比如,o1-preview 和 o1-mini 在问题 B2 上都因证据不足、不够严谨失掉了一些分数,尽管最终结果是正确的。
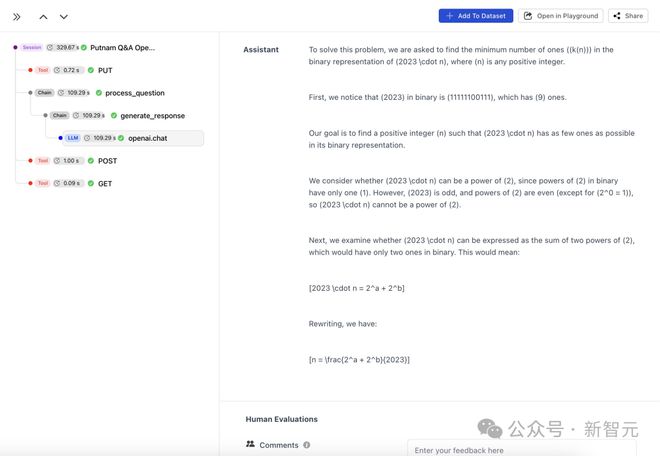
他们认为,这可能是因为 AI 模型在表达或访问其内部「思维链」时,存在一定的局限性。
不过,IBM 研究员表示,能够拿下一定的高分,当然也存在了数据泄露的可能性。
比赛介绍
普特南数学竞赛(全称 William Lowell Putnam Mathematical Competition)专为美国和加拿大的本科生设立,每年于 12 月举办一届,今年是第 85 届年赛。
每年竞赛一共分为两场考试,分别是上午A试,下午B试,各三小时。
这场比赛可以追溯到 1938 年,最初只是各个高校数学系之间的友好较量。如今,它已经发展成为世界上最具权威的大学数学竞赛。

每年 12 月,数百所大学数学尖子生在为期 6 小时数学中展现自己的数学才华。
尽管考生需要独立完成试卷,但比赛同时设立了团队的环节。
普特南数学竞赛不仅仅是一场知识的较量,更是一个荣誉的殿堂。排名最高的团队的数学系可以获得现金奖励,学生成员还将被授予「普特南研究员」的称号。
与此同时,比赛还设立了「The Elizabeth Lowell Putnam Prize」奖项,专为表现卓越的女性数学家颁奖。
去年第 84 届比赛中,个体获奖者 5 名全部来自 MIT,团体获奖者前五名也分别来自世界高校:MIT、哈佛、杜克、斯坦福、多伦多大学。

参考资料:






