金磊发自拉斯维加斯
量子位公众号 QbitAI
就在刚刚,云计算一哥亚马逊云科技,在大模型这件事儿上搞了波大的——
亚马逊 CEO Andy Jassy亲自站台re:Invent24,发布自家新款 AI 多模态系列大模型,名曰Amazon Nova。
而且是一口气涵盖文本对话、图片生成、视频生成,甚至直接吐露一个小目标:
将来我们不仅要 Speech to Speech,更要 Any-to-Any!

整体而言,Amazon Nova 系列中的所有模型,均以功能和尺寸来划分。
先来看下新版尖端基础大模型的“文本对话篇”,一共包含四个杯型:
- Amazon Nova Micro:仅限文本对话,主打一个低价格和低延迟;
- Amazon Nova Lite:低成本的多模态大模型,处理图像、视频和文本输入的速度极快。
- Amazon Nova Pro:高性能的多模态大模型,精度、速度和成本最佳“配方”,可处理广泛的任务。
- Amazon Nova Premier:亚马逊最强多模态大模型,可处理复杂的推理任务,也可用于蒸馏客户定制化的模型。
在现场,Andy 也晒出了 Amazon Nova 在 CRAG、BFCL、VisualWebBench 和 Mind2Web 等Benchmarks上取得的分数。
从成绩中不难看出,其在检索增强生成(RAG)、函数调用和智能体应用方面具有较好的性能。
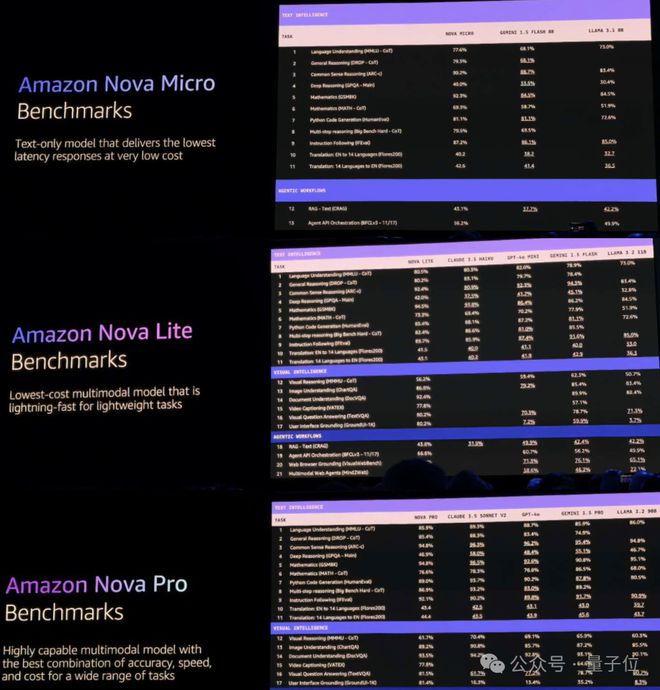
据悉,前三者已经上架亚马逊云科技的“模型工厂”Amazon Bedrock,而 Premier 版本则将于 2025 年第一季度推出。
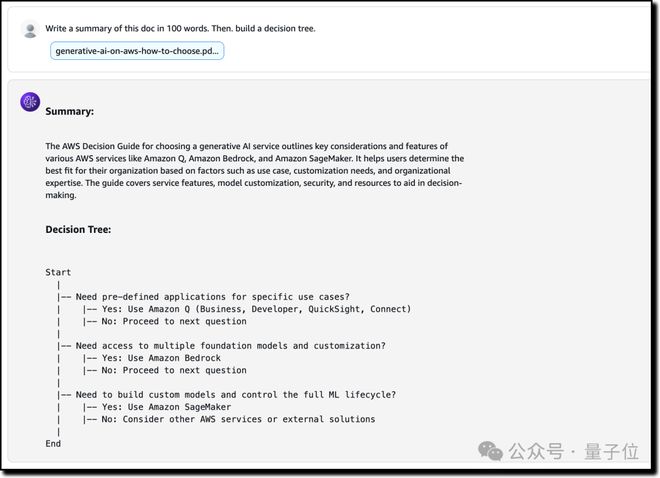
目前也有一些实测已经流出,例如给 Amazon Nova Pro 一句 Prompt:
Write a summary of this doc in 100 words. Then, build a decision tree.
写一篇 100 字的摘要。然后,构建一个决策树。
啪的一下,结果就出来了:
再如让 Amazon Nova Pro 理解下面这个合并在一起的视频:

它给出的答案是:
The video begins with a view of a rocky shore on the ocean, and then transitions to a close-up of a large seashell resting on a sandy beach.
视频一开始是海洋上的岩石海岸,然后过渡到一个大贝壳躺在沙滩上的特写。

接下来,就是“非文本生成篇”,一共包括两款。
Amazon Nova Canvas,主打的是图像生成,用官方的话来说,是达到了“State-of-the-art”(最先进)的水平:

至于视频生成模型,名叫Amazon Nova Reel,给定一张图片和一句话,即可让它动起来:

而接下来 Andy 的一番话,直接让现场不淡定了。
正如我们刚才提到的,Andy 已经放出了话,Amazon Nova 即将呈现出来的态势是万物皆可生成。

值得细细品味的一点是,亚马逊云科技在生成式 AI 时代中,先前发布自研大模型并不算最吸睛的那一批。
虽然此前也发布过 Amazon Titan 大模型,但模态上也仅限于文本,更多的精力还是聚焦在了像 Amazon Bedrock、Amazon Q 这样的平台和应用。
而这次,亚马逊云科技却一反常态,以厚积薄发之势把主流模态全面覆盖,甚至一句“Any-to-Any”彰显其雄心。
为何会如此?
纵观整场发布会,透过亚马逊云科技 CEO Matt Garman 的全程介绍,或许可以把答案总结为——
实力是一直有的,只是现在客户有需求了。

△Matt Garman 首次以 CEO 身份参加 re:Invent
这又该如何理解?我们继续往下看。
算力再升级,价格很美丽
先看实力。
作为云计算一哥,算力是亚马逊云科技的看家本领之一。
与传统云服务厂商不同,其自主研发并优化的专用芯片和数据中心,包括 Graviton 和 Nitro 等专有服务器主机,为实时计算提供支持。
而这一次,从芯片到服务器,基础设施上一系列的更新动作,可以分为三大板块来看——
计算(Compute)、存储(Storage)和数据库(Database)。

在计算层面上,亚马逊云科技先是宣布Amazon EC2 Trn2 实例正式可用。
EC2 Trn2 实例采用了第二代 Trainium 芯片(Trainium2),与上一代 Trn1 实例相比,性能提升显著。具体来说:
- 训练速度提高 4 倍:这一性能提升能有效减少模型训练所需时间,加快企业应用落地;
- 内存带宽提高 4 倍:更强的数据传输能力可以满足复杂模型对实时数据处理的高要求;
- 内存容量提高 3 倍:为高参数量模型的运行提供了足够的计算资源。
此外,Trn2 实例在性价比上比当前基于 GPU 的 EC2 P5e 和 P5en 实例高出30-40%。
每个 Trn2 实例包含 16 个 Trainium2 芯片,192 vCPUs,2 TiB 的内存,以及 3.2 Tbps 的 Elastic Fabric Adapter (EFA) v3 网络带宽,这比上一代降低了高达 35% 的延迟。

针对更高性能需求,亚马逊云科技同时推出了Trn2 UltraServer。
这是一种全新的超大规模计算产品,每台 UltraServer 包含 64 个 Trainium2 芯片,并通过高带宽、低延迟的 NeuronLink互连实现了卓越的性能。
这使得 Trn2 UltraServer 成为训练超大规模基础模型(如生成式 AI、LLM 等)的理想选择。
NeuronLink 是亚马逊云科技专有的网络互连技术,它能够将多台 Trainium 服务器组合成一个逻辑上的单一服务器,连接带宽可达 2TB/s的带宽,而延迟仅为 1 微秒。
它的设计特别适合分布式深度学习任务,在网络通信上的优化有助于显著缩短训练时间,提升资源利用率。
用官方的话来说就是:
这正是训练万亿级参数的大型人工智能模型所需要的超级计算平台,非常强大。

在现场,苹果也来为亚马逊站台,机器学习和人工智能高级总监 Benoit Dupin 表示:
苹果将使用亚马逊云科技的 Trainium2 芯片。

除此之外,在芯片层面上,亚马逊云科技发布了AWS Trainium3 芯片预览版,预计于 2025 年正式推出。
据悉,Trainium3 将采用 3 纳米工艺制造,提供两倍于 Trainium2 的计算能力,并提升 40% 的能效。

在计算(Compute)之后,便是存储(Storage)上的更新。
我们都知道,在数据分析和大数据领域,处理和查询大规模数据集的能力至关重要。
而传统的数据查询方法在处理海量数据时,常常导致性能瓶颈和管理复杂性,影响了企业的数据驱动决策能力。
为此,亚马逊云科技专门推出了Amazon S3 Tables。

Amazon S3 Tables 提供了一种新的存储方式,专为表格数据设计,支持使用 Amazon Athena、Amazon EMR 和 Apache Spark 等流行的查询引擎进行轻松查询。
S3 的表存储桶是它的第三种存储桶类型,与现有的通用存储桶和目录存储桶并列;可以将表存储桶视为一个分析仓库,用于存储具有不同模式的 Iceberg 表格。
与自管理的表格存储相比,S3 Tables 可以实现高达 3 倍的查询性能提升和10 倍的每秒事务处理能力,同时提供全托管服务的操作效率。
除此之外,元数据(Metadata)也变得越发重要,例如电话里面有很多照片,正是因为通过元数据储存数据,现在可以实现用自然语言很快找到这张照片。
基于这样的需求,亚马逊云科技推出了Amazon S3 Metadata 的预览版。

Amazon S3 Metadata 提供了一种自动化、易于查询的元数据管理方式,这些元数据几乎实时更新,帮助用户整理、识别和使用 S3 数据进行业务分析、实时推理应用等。
它支持对象元数据,包括系统定义的详细信息(如大小和对象来源)以及自定义元数据,允许用户使用标签为对象添加产品 SKU、交易 ID 或内容评级等信息。
而这些元数据同样也存储在 S3 Tables 之中。

在计算、存储之后,便是基础设施的第三大板块——数据库(Database)。
有意思的一点是,Matt 在现场分享了一张“OR”还是“AND”的图,表示企业在选择数据库时普遍遇到的艰难抉择——跨区域一致、高可用性、低延迟,往往只能 3 选2。

而亚马逊云科技此次给出的答卷是,都可以有。
这就是新型无服务器分布式数据库Amazon Aurora DSQL,旨在解决传统数据库在扩展性和性能方面的挑战。

Aurora DSQL 结合了传统关系数据库的强一致性和 NoSQL 数据库的分布式扩展能力,提供了以下几个关键优势:
- 跨区域强一致性和低延迟:采用了全新的架构,使其能够在多个地理区域中同时运行,而保持强一致性。
- 无限扩展:能够处理数 TB 到数 PB 级的数据集,适用于任何规模的企业。
- 超高可用性:提供 99.999% 的可用性,这对于许多需要高可用性和无缝运行的企业级应用至关重要。
- 性能优越:其跨区域的读写操作比 Spanner 快了四倍。

以上便是亚马逊云科技此次在基础设施上的发力了。
新的积木——推理
如果说把基础设施的三大板块视为三块积木,那么接下来,亚马逊云科技在模型层和应用层方面添加了第四块积木——推理(Inference)。
推理是生成式 AI 工作流的核心,它指的是将已经训练好的模型应用到新数据上,进行预测、生成或推断。
Matt 在会上强调:
推理在 AI 模型的应用中变得尤为重要,尤其是在处理像大型语言模型等复杂模型时,推理要求极高的计算能力和低延迟响应。
而 Amazon Bedrock 作为亚马逊云科技在模型层的一项 AI 平台服务,先是与我们上述的基础设施在推理上保持了同步。
换言之,Inferentia 和 Trainium 芯片提供的推理的硬件优化,用户可以通过 Amazon Bedrock 便捷访问这些资源。
而至于 Amazon Bedrock 本身,这次也迎来多项能力的升级。
首先就是模型蒸馏(Model Distillation),能够自动化创建针对特定用例的蒸馏模型。

主要是通过从大型基础模型(教师模型)生成响应,并使用这些响应来微调较小的基础模型(学生模型),从而实现知识转移,提高小模型的精确度,同时降低延迟和成本。

其次是多智能体协作(multi-agent collaboration)。
在需要多个智能体处理复杂任务的场景中,管理这些智能体变得具有挑战性,尤其是随着任务复杂性的增加。
使用开源解决方案的开发者可能会发现自己需要手动实现智能体编排、会话处理、内存管理等复杂操作。
这也正是亚马逊云科技在 Amazon Bedrock 上推出多智能体协作的出发点。具体特点如下:
- 快速设置:无需复杂编码,几分钟内创建、部署和管理协同工作的 AI 智能体。
- 可组合性:将现有智能体作为子智能体集成到更大的智能体系统中,使它们能够无缝协作以应对复杂的工作流程。
- 高效的智能体间通信:监督智能体可以使用一致的接口与子智能体进行交互,支持并行通信以更高效地完成任务。
- 优化的协作模式:在监督模式和监督加路由模式之间选择。在路由模式下,监督智能体将直接将简单请求路由到相关的子智能体,绕过完整的编排。

最后,也是更为重要的一点,便是防止大型语言模型幻觉导致的事实错误的功能——自动推理检查(Automated Reasoning checks),这是 Amazon Bedrock Guardrails 中新增的一项功能。

这种新的防护措施,旨在通过数学验证来确保 LLMs 生成的响应的准确性,并防止幻觉导致的事实错误。
自动推理检查使用基于数学和逻辑的算法验证和推理过程来验证模型生成的信息,确保输出与已知事实一致,而不是基于虚构或不一致的数据。
与机器学习(ML)不同,自动推理提供了关于系统行为的数学保证。
据悉,亚马逊云科技已经在存储、网络、虚拟化、身份和密码学等关键服务领域使用自动推理,例如,自动推理用于正式验证密码实现的正确性,提高性能和开发速度。

在性能方面,Bedrock 还推出了低延迟优化推理,由此,用户可以在使用最先进的大模型基础上,还享受卓越的推理性能。
值得一提的是,Llama 405B 和 Llama 70B 低延迟优化版本,在亚马逊云科技上展现出超越其他云提供商的出色表现。

还有应用层和其它更新
针对开发者和企业,亚马逊云科技在应用层上的代表作便是 Amazon Q 了。
针对越来越多的企业寻求从本地数据中心迁移到云的痛点,亚马逊云科技在 Amazon Q Developer 上推出了多项新功能。
其中较为引人注目的就是Transformation for Windows .NET Applications,这项功能使得企业能够更快速地将 .NET 应用程序迁移到 AWS,同时还能够显著降低迁移成本。

Amazon Q 为 .NET 应用程序提供了自动化迁移工具,能够识别应用程序中可能存在的不兼容问题,生成迁移计划,并且自动调整源代码,确保平滑过渡到云端。这种自动化迁移大幅提高了工作效率,减少了人为干预。
通过将应用程序从 Windows 迁移到 Linux,企业能够节省高昂的 Windows 许可费用,降低 TCO(总拥有成本)。
Matt 指出,使用 Amazon Q 的企业能够节省多达 40% 的许可成本。
而且迁移速度比传统手动迁移快了四倍,大大减少了系统迁移的停机时间和风险。
除了 Windows 应用的迁移,亚马逊云科技还推出了 Amazon Q Developer Transformation for VMware Workloads功能,专为运行在 VMware 上的企业工作负载设计。
通过这一工具,亚马逊云科技可以帮助企业将本地的 VMware 环境迁移到云平台。

应用层之外,还有诸如将 AI 和分析做结合的产品——Amazon SageMaker。
它作为一个可以帮企业加速 AI 应用的开发、训练和部署的数据科学平台,今天也正式步入了“下一代”。
新一代 SageMaker 的核心是SageMaker Unified Studio。
这是一个单一的数据和 AI 开发环境,它整合了 Amazon Athena、Amazon EMR、AWS Glue、Amazon Redshift、Amazon Managed Workflows for Apache Airflow (MWAA)以及现有的 SageMaker Studio 中的工具和功能。
其次是Amazon SageMaker Lakehouse,可以统一 Amazon S3 数据湖、Amazon Redshift 数据仓库和第三方及联合数据源。

亚马逊云科技的“AI 步法”
在看完本届 re:Invent 所有内容和实力之后,亚马逊云科技在生成式 AI 时代的发展路径其实也就比较清晰了——
从客户的真实业务需求出发。
上文种种内容的更新,都是基于“客户的服务出现了什么问题”,包括计算、存储、数据库上的瓶颈,包括客户在模型上的选择,再包括应用上的迁移服务等等。

洞悉了背后的实用主义逻辑,也就不难理解,亚马逊云科技为何选择在这个时间节点上发布一系列多模态大模型,还是因为客户有需要。
这种需要,具体而言,就是客户在模型上的选择,毕竟“没有一个模型可以一统天下”,每个模型都有自己所擅长的领域。
但亚马逊云科技所做的,是利用自己在基础设施、工具/模型和应用三个层面的深耕和实力,给客户多提供了一个“快、好、省”的选项。

回顾亚马逊云科技的起步,似乎这一点从未变过。
正如 Matt 在大会上回忆的那样:
亚马逊云科技在 2006 年推出时,初创公司是第一批用户,他们总是非常积极地采用新技术,并且能够提供有价值的反馈。

而这种反馈也进一步推动了亚马逊云科技的发展,也有助于理解如何更好地支持创业精神。
因此,Matt 在大会中还宣布了一个重磅消息:
将在 2025 年为全球的初创公司提供 10 亿美元的资金支持!
One More Thing
本届 re:Invent 共计6 万人参与,来感受一下这个热情、这个 feel~

参考链接:
[1]https://www.aboutamazon.com/news/aws/amazon-nova-artificial-intelligence-bedrock-aws
[2]https://aws.amazon.com/blogs/aws/amazon-ec2-trn2-instances-and-trn2-ultraservers-for-aiml-training-and-inference-is-now-available/
[3]https://aws.amazon.com/blogs/aws/new-amazon-s3-tables-storage-optimized-for-analytics-workloads/






