
新智元报道
编辑:alan
对于 LLM 来说,人类语言可能不是最好的交流媒介,正如《星战》中的机器人有自己的一套语言,近日,来自微软的研究人员改进了智能体间的交互方式,使模型的通信速度翻倍且不损失精度。
在《星球大战》中,机器人 R2-D2 和其他机器人使用特殊的语言进行交流。
这种语言主要由蜂鸣声和口哨声组成,被称为「二进制语」(Binary)或「机器人语」(Droidspeak)。

Droidspeak 是专门为机器人之间的交流设计的,只有机器人能够完全理解其精确含义。
电影中,C-3PO 是唯一能够完全理解 R2-D2 语言的角色,而天行者等人类则是通过长期与 R2-D2 相处,逐渐能够猜测出它所表达的意思。

机器人之间的「专用」通信显然更加高效,那对于 LLM 来说,是否也应该如此?
近日,来自微软、芝加哥大学的研究人员推出了「Droidspeak」,让 AI 智能体之间可以用自己的语言进行交流:

论文地址:https://arxiv.org/pdf/2411.02820
结果表明,在不损失性能的情况下,Droidspeak 使模型的通信速度提高了 2.78 倍。
所以,尽管人类用自然语言训练出了 LLM,但用自然语言输出和交流,只是 AI 对于人类的一种「迁就」。
Droidspeak
下面是喜闻乐见的读论文环节。
事先甩个锅,说「发明全新 LLM 语言」或有标题党之嫌,概括文章的思想,四个字足矣:缓存复用。
再具体一些:在很多智能体系统中,不同的 Agents 其实是同源的,大家从同一个 base model 微调而来,参数的差距并不大。
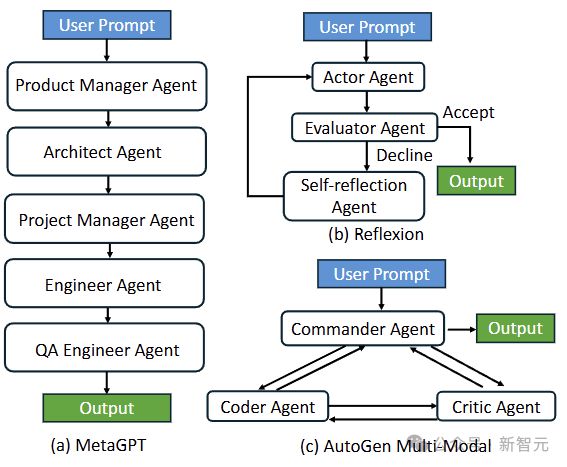
那么,相同的输入(经过差不多的 weight)产生的计算结果也应该差不多。
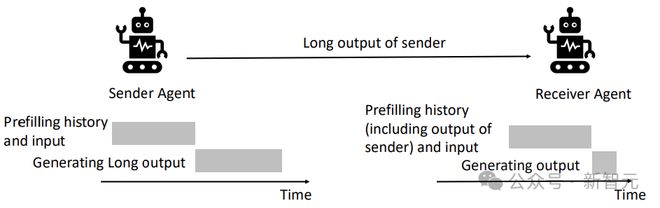
在智能体系统中,前一个 Agent(sender)的输出,会作为后一个 Agent(receiver)输入的一部分。
而这部分需要 prefill 的计算,在之前其实已经做过了,那对于 receiver 来说,是不是能直接把 sender 的计算结果拿过来?
——直接传递模型中间的计算结果(缓存),而不需要转换成人类能够理解的自然语言,这就是「Droidspeak」的含义。

如果您是相关领域研究者,看到这里基本就可以退出了,节约了您宝贵的时间。
(但是小编走不了,毕竟稿费是按字数算的......)
智能体面临的挑战
高端的食材往往只需要最朴素的烹饪方式,而简单的 idea 往往得来并不简单。
根据小学二年级学过的知识,LLM 的推理可分为预填充(prefill)和解码(decode)两个阶段:
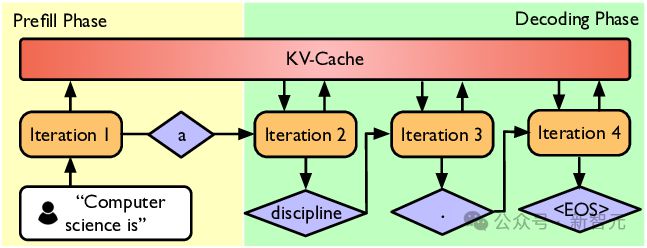
prefill 是 LLM 拿你提出的问题(词向量序列),一股脑放进模型计算,填充所有层的 kv cache;
而 decode 是用最后一个词作为 query,开始一个一个词往外蹦。
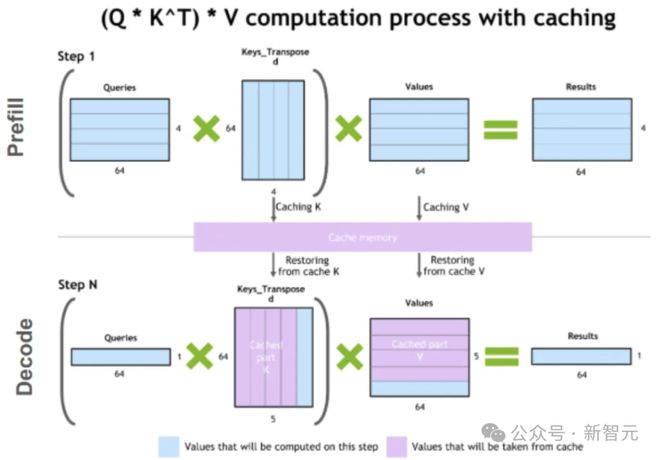
从计算的角度来看,预填充阶段是矩阵乘矩阵,为计算密集型;解码阶段是向量乘矩阵,相对来说访存变多。
当我们长时间运行上下文密集的对话时,prefill 的占比会越来越高,包括计算和通信的开销。
所以在需要频繁交互的智能体系统中,prefill 会成为瓶颈。
比如,在 HotpotQA 数据集中,Llama-3-70B-Instruct 的平均预填充延迟为 2.16 秒,而解码时间只有 0.21 秒;
在 MapCoder 这种级联智能体系统中,前一个 Agent 的输出最多可达到 38,000 个 token,从而导致极高的预填充延迟。
亲子关系
之前有工作探究过,利用 kv cache 来减少同一个模型的预填充延迟,这件事在智能体系统中貌似也能成立。
先测试一下亲子之间的相似度。
实验使用 base model 作为发送方,微调版本作为接收方,选择了下面四组模型。
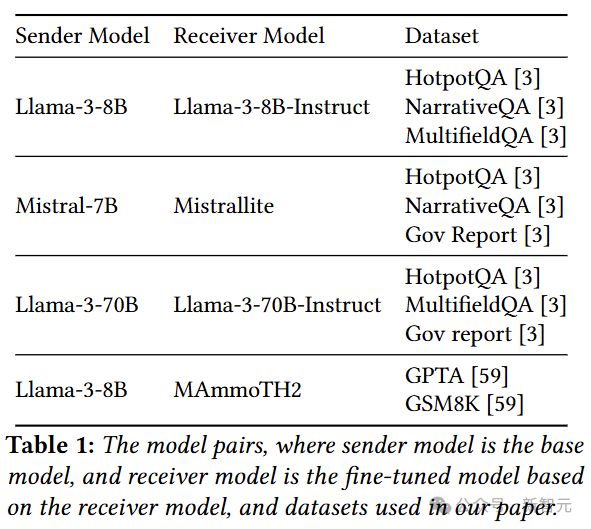
单从模型参数来看,绝对是亲生的,相似度差别都是小数点后三位的水平:
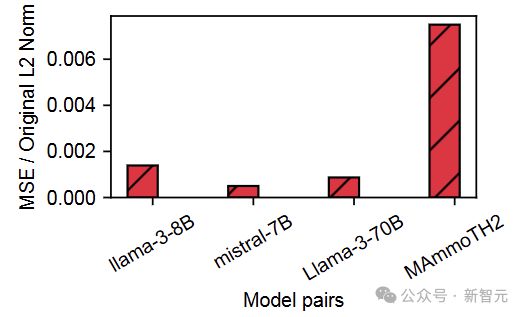
那么对于相同输入,中间的计算结果有多大差别?
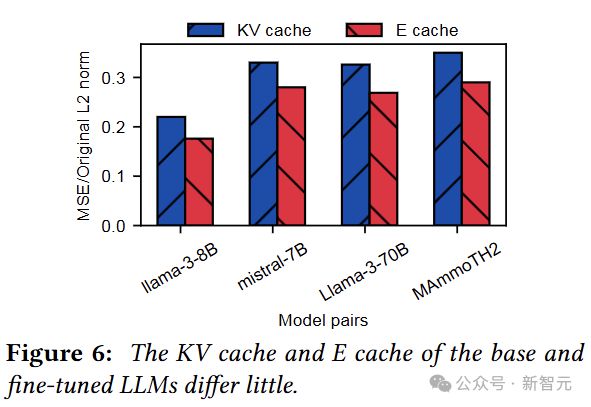
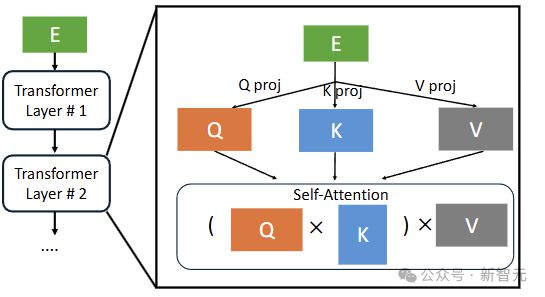
这里的 E cache 指的是每层的输入,即E通过投影矩阵计算出 QKV。
相比于权重,每对模型的 E cache 和 KV cache 差别大了一点点,但也还好,那能不能直接复用呢?
方法探索
在最初的实验构建中,要求微调版本在测试基准上的表现比基础模型好得多,以便测试出复用缓存带来的影响。
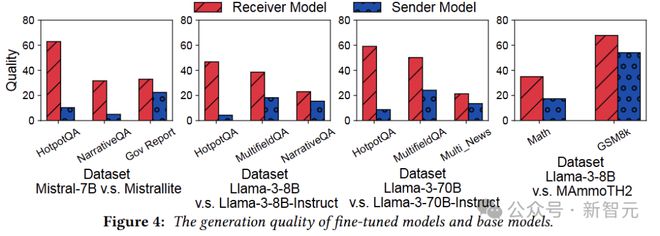
在此基础上,如果只是简单的复用全部的 kv cache,效果稍显惨不忍睹,Fine-tuned Model 的性能直接被打回原形:
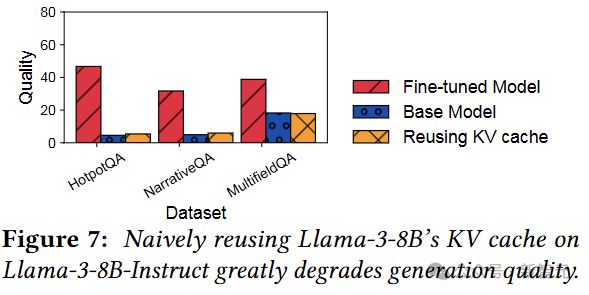
看上去需要更加细致的操作,所以逐层分析一下 E cache 和 KV cache 的差别(注意是与 base model 的差别)。
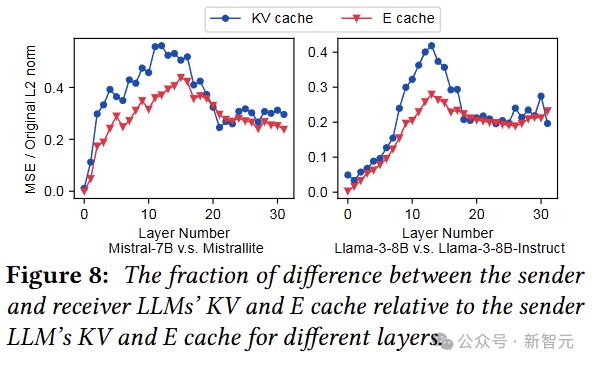
因为缓存的差异因层而异,所以优化的应用也要按层来,这里首先考虑重用 KV cache 的连续层(直到最后一层)。
下图表明了重用 KV cache 带来的精度影响,效果很不错,但优化的自由度很低。

小编推测,这个「自由度低」的意思是:复用 KV cache 时,本层的输入(E cache)就不需要了,没有输入就没法算Q,就没法算下一层,所以后面也只能复用 KV cache(直到最后一层)。
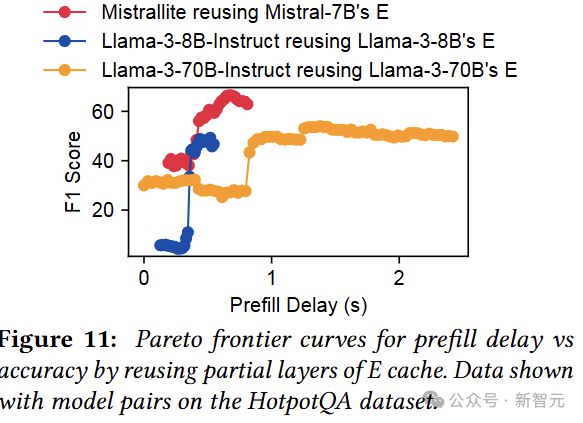
所以,作者接下来就测试复用 E cache 的情况,因为有输入可以继续往下算,所以复用 E cache 时可以选择任意的起点和终点。
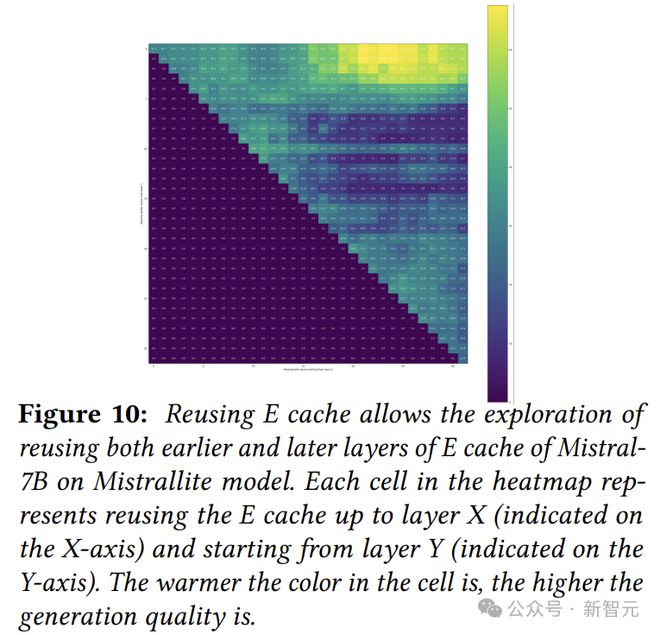
如下图所示,每个点代表在一定程度的预填充延迟下的最佳精度。
我们可以看到,重用 E cache 在保持生成质量的同时,将预填充延迟降低了 1.8 倍。
最终方案
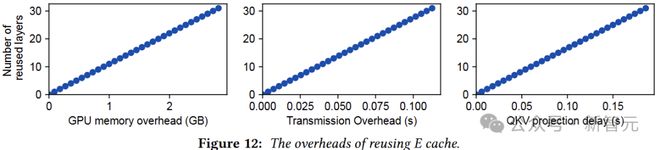
作者表示,尽管重用 E cache 在层方面提供了极大的灵活性,但它会在 GPU 内存、传输和计算方面产生开销。
考虑发送方和接收方放置在两个 GPU 节点上,并通过 Infiniband 链路互连:
在发送方,E cache 需要先存储在 GPU 内存中(内存开销),发送 E cache 到接收方会产生额外的传输延迟;
在接收端,还需要额外的 QKV 投影操作,将 E cache 转换为 KV cache,这会导致额外的计算延迟。这三种类型的 delay 随着重用层的数量呈线性增长,如图 12 所示。
与之相对,重用 KV cache 没啥额外开销,只是缺乏灵活性。
所以,两种方法合体。
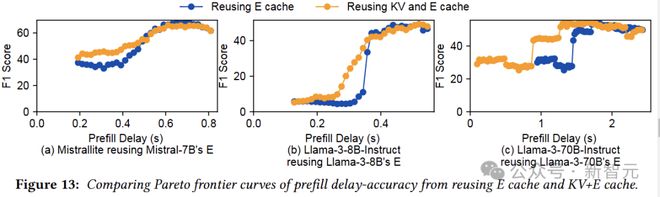
图 13 在预填充延迟和准确性权衡方面,比较了单独重用 E cache 与重用 KV+E cache。
对于实验的三对模型,重用 KV+E cache 在延迟和准确性方面效果良好,且不会增加发送方的 GPU 内存开销或接收方的计算开销。
最后是端到端的整体架构:
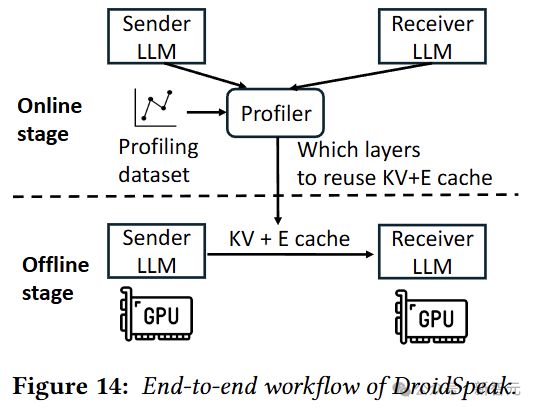
如图 14 所示,离线阶段,DroidSpeak 首先在示例分析数据集上分析每对要重用的层(复用配置);
在线阶段,当发送方与接收方 LLM 通信时,会根据复用配置将 KV 和E缓存发送给接收方。
然后,接收方会为那些不重用 KV 缓存的层重新计算新的 KV 缓存。
下图展示了 DroidSpeak 相对于 baseline 的改进:
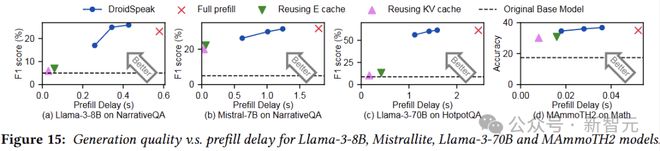
我们可以看到,与完全预填充相比,DroidSpeak 的预填充延迟减少了 1.69 到 2.77 倍,而不会影响生成质量(重用所有E缓存或 KV 缓存时,生成质量会大大降低)。
水平虚线表示基础模型的生成质量,DroidSpeak 的质量损失与基础模型和微调模型之间的差异相比微不足道。
参考资料:






