
新智元报道
编辑:LRS
DIAMOND 是一种新型的强化学习智能体,在一个由扩散模型构建的虚拟世界中进行训练,能够以更高效率学习和掌握各种任务。在 Atari 100k 基准测试中,DIAMOND 的平均得分超越了人类玩家,证明了其在模拟复杂环境中处理细节和进行决策的能力。
环境生成模型(generative models of environments),也可以叫世界模型(world model),在「通用智能体规划」和「推理环境」中的关键组成部分,相比传统强化学习采样效率更高。
但世界模型主要操作一系列离散潜在变量(discrete latent variables)以模拟环境动态,但这种压缩紧凑的离散表征有可能会忽略那些在强化学习中很重要的视觉细节。
日内瓦大学、爱丁堡大学的研究人员提出了一个在扩散世界模型中训练的强化学习智能体 DIAMOND(DIffusion As a Model Of eNvironment Dreams),文中分析了使扩散模型适应于世界建模(world modeling)所需的设计要素,并展示了如何通过改善视觉细节来提高智能体的性能。

论文链接:https://arxiv.org/pdf/2405.12399
代码链接:https://github.com/eloialonso/diamond
项目链接:https://diamond-wm.github.io
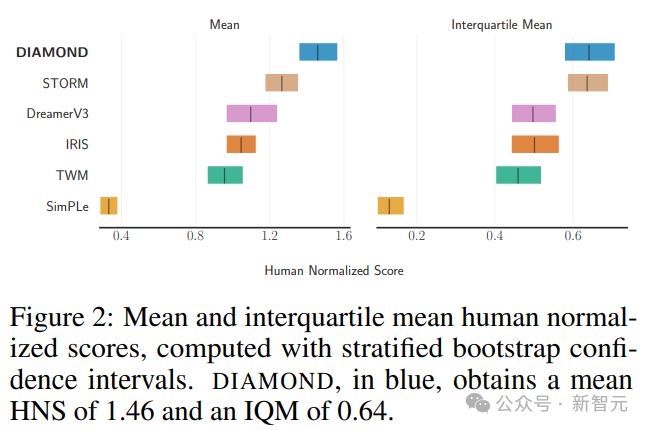
DIAMOND 在 Atari 100k 基准测试中达到了 1.46 的平均人类标准化分数(mean human
normalized score),也是完全在世界模型内训练智能体的最佳成绩。

此外,在图像空间中操作还有一个好处是,扩散世界模型能够成为环境的即插即用替代品,更方便地深入分析世界模型和智能体行为。
在项目主页,研究人员还展示了智能体玩 CS: GO 的画面,先收集了 87 小时人类玩家的视频;然后用两阶段管道(two-stage pipeline:)以低分辨率执行动态预测,降低训练成本;将扩散模型从 Atari 的 4.4M 参数扩展(scaling)到 CS: GO 的 381M;最后对上采样器使用随机采样(stochastic sampling)来提高视觉生成质量。

模型在 RTX 4090 上训练了 12 天,并且可以在 RTX 3090 上以约 10 FPS 的速度运行。
不过该方法在模拟世界模型时,在部分场景下仍然会失效。

强化学习和世界模型
我们可以把环境看作是一个复杂的系统,智能体在这个系统中通过执行动作来探索并接收反馈(奖励)。
智能体不能直接知道环境的具体状态,只能通过图像观测来理解环境,最终的目标是教会智能体一个策略,使其能够根据所看到的图像来决定最佳的行动方式,以获得最大的长期奖励。
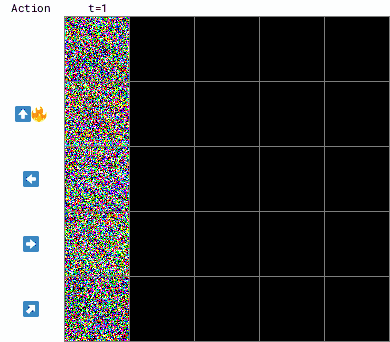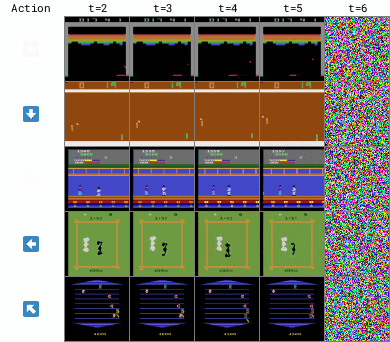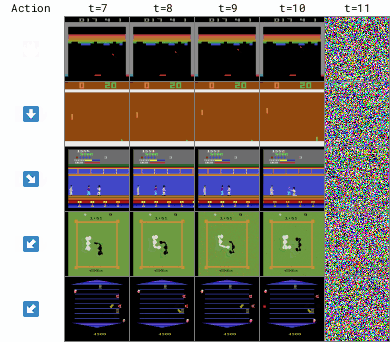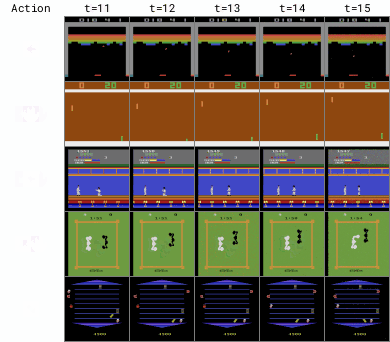
为此,研究人员构建了一个世界模型来模拟环境的行为,让智能体在模拟环境中进行训练,这样可以更高效地利用数据,提高学习速度。
整个训练过程包括收集真实世界中的数据,用这些数据来训练世界模型,然后让智能体在世界模型中进行训练,类似于在一个虚拟的环境中进行练习一样,也可以称之为「想象中的训练」(imagination)。
基于评分的扩散模型
扩散模型是一类受非平衡热力学启发的生成模型,通过逆转加噪过程来生成样本。
假设有一个由连续时间变量τ索引的扩散过程,其中τ的取值范围是 0 到T,然后有一系列的分布,以及边界条件:在τ=0 时,分布是数据的真实分布,而在τ=T时,分布是一个易于处理的无结构先验分布,比如高斯分布。
为了逆转正向的加噪过程,需要定义漂移系数和扩散系数的函数,以及估计与过程相关的未知得分函数;在实践中,可以使用一个单一的时间依赖得分模型来估计这些得分函数。
不过在任意时间点估计得分函数并不简单,现有的方法使用得分匹配作为目标,可以在不知道潜在得分函数的情况下,从数据样本中训练得分模型。
为了获得边际分布的样本,需要模拟从时间 0 到时间τ的正向过程,然后通过一个高斯扰动核到清洁数据样本,在一步之内解析地到达正向过程的任何时间τ;由于核是可微的,得分匹配简化为一个去噪得分匹配目标(denoising score matching),这时目标变成了一个简单的 L2 重建损失,其中包含了一个时间依赖的重参数化项。
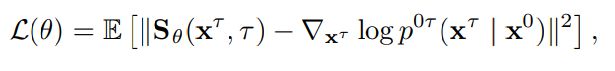
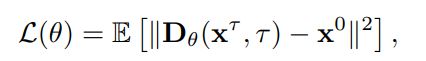
用于世界建模的扩散模型
世界模型需要一个条件生成模型来模拟环境的动态,即给定过去的状态和动作,预测下一个状态的概率分布,可以看作是部分可观察马尔可夫决策过程(POMDP),通过在历史数据上训练一个条件生成模型,来预测环境的下一个状态,虽然理论上可以采用任意常微分方程(ODE)或随机微分方程(SDE)求解器,但在生成新的观察结果时,需要在采样质量和计算成本之间做出权衡。
DIAMOND
DIAMOND 模型有两个重要的参数,一个是漂移系数,决定了系统随时间变化的趋势;另一个是扩散系数,决定了噪声的强度,两个系数共同调节可以使模型更好地模拟真实世界的变化。

模型的核心是预测环境的下一个状态,为了训练该网络,需要提供一系列的数据,包括过去的观察结果和动作,网络的目标是从当前的状态和动作中预测出下一个状态。
在训练过程中,会逐渐向数据中加入噪声,模拟环境的不确定性;然后,网络需要学会从这些带有噪声的数据中恢复出原始的、清晰的下一个状态,整个过程就像是在一堆杂乱无章的信息中找到规律,预测出接下来可能发生的事情。
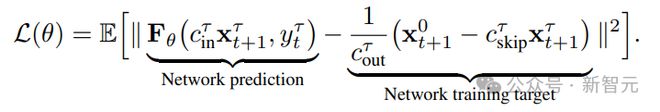
为了帮助网络更好地学习和预测,DIAMOND 使用了一种叫做U-Net 的神经网络结构。这种结构特别适合处理图像数据,因为它可以捕捉到图像中的复杂模式。我们还使用了一种特殊的技术,叫做自适应组归一化,这有助于网络在处理不同噪声水平的数据时保持稳定。
最后使用欧拉方法来生成预测结果,不需要复杂的计算,在大多数情况下都可以提供足够准确的预测。
在想象中强化学习
比如说,我们正在训练一个智能体如何在一个虚拟世界中行动:智能体需要「奖励模型」告诉它做得好不好,需要「终止模型」告诉他什么时候游戏结束。
智能体有两个部分:一个部分告诉它该怎么做(actor),用 REINFORCE 方法来训练;另一个部分告诉它做得怎么样(critic ),用λ-回报的贝尔曼误差的方法来训练。
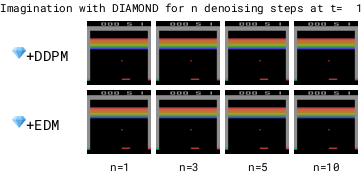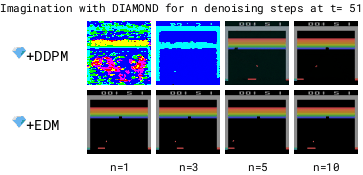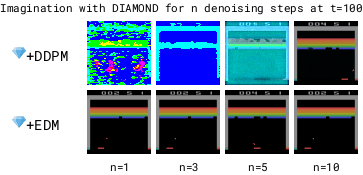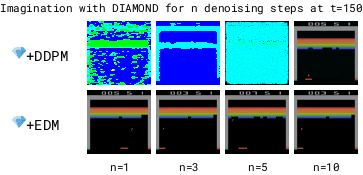
让智能体在一个完全由计算机生成的世界中进行训练,这样就可以在不真实接触环境的情况下学习和成长。
只需要在真实环境中收集一些数据;每次收集完数据后,都会更新智能体的虚拟世界,然后让模型在这个更新后的世界中继续训练;整个过程不断重复,直到智能体学会如何在虚拟世界中更好地行动。
Atari 100k 基准结果
Atari 100k 包括了 26 个不同的电子游戏,每个游戏都要求模型具有不同的能力。
在测试中,智能体在开始真正玩游戏之前,只能在游戏中尝试 100,000 次动作,大概相当于人类玩 2 个小时的游戏时间,而其他无限尝试的游戏智能体通常会尝试 5 亿次动作,多了 500 倍。
为了更容易与人类玩家的表现进行比较,使用人类归一化得分(HNS)指标,结果显示,DIAMOND 的表现非常出色,在 11 个游戏中超过了人类玩家的表现,基本实现了超越人类的水平,平均得分为 1.46,在所有世界模型训练的智能体中是最高的。
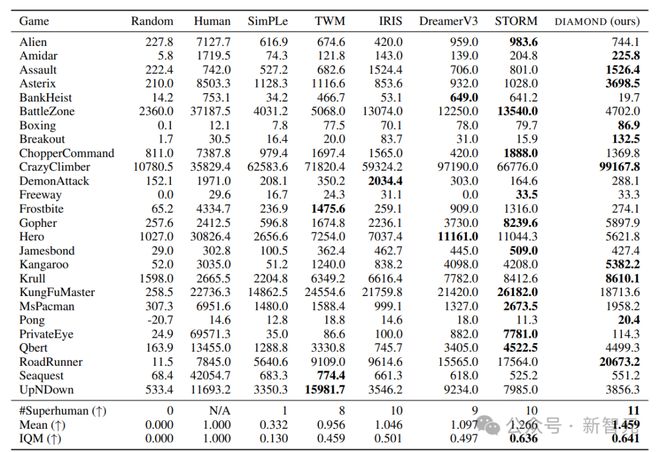
DIAMOND 在某些游戏中的表现尤其好,要求智能体能够捕捉到细节,比如《阿斯特里克斯》、《打砖块》和《公路赛跑者》。
参考资料:
https://x.com/op7418/status/1845152731901853970
https://the-decoder.com/ai-model-simulates-counter-strike-with-10-fps-on-a-single-rtx-3090/






