出品|网易科技《态度》栏目
作者|袁宁
编辑|丁广胜
10 月 21 日,被智源冠以“今年最重要”的模型——原生多模态世界模型 Emu3 终于发布。
仅基于下一个 token 预测,Emu3 就实现了多模态的统一理解与生成。也就是说,无论是图像、文本还是视频模态的内容,都可以在 Emu3 一个系统中完成理解和生成——
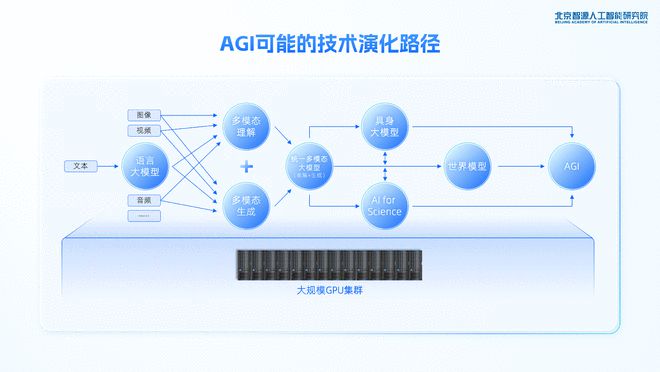
智源走通了一条用统一架构探索多模态的方法,给出了下一代多模态大模型的训练范式。
“科研没有一帆风顺,面对挫折挑战以及技术创新的不确定性,Emu3 研发团队攻克了一个又一个技术难关,做到了第一次先于国际社会发布,率先验证了新的大一统原生多模态技术路线。”智源研究院院长王仲远难掩其兴奋。
对比实际效果,根据智源的评测,在图像生成、视觉语言理解、视频生成任务中,Emu3 的表现超过了 SDXL、LLaVA-1.6、OpenSora 等开源模型。
目前,智源已将 Emu3 的关键技术和模型开源。
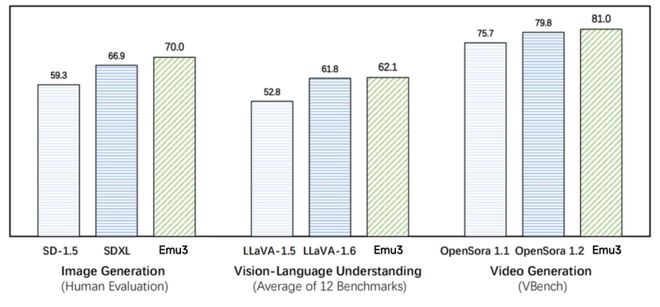
图注:在图像生成任务中,人类评估得分 Emu3 高于 SD-1.5 与 SDXL。在视觉语言理解任务中,12 项基准测试的平均得分,Emu3 领先于 LlaVA-1.6 与 LlaVA-1.5。在视频生成任务中,VBench 基准测试得分,Emu3 优于 OpenSora 1.2。
此前,ChatGPT 的横空出世,验证了“下一个 token 预测”在大语言模型领域的可行性,但其在多模态模型中的适用性仍未表明。
在 Emu3 发布之前,行业内多模态生成模型大多采用扩散模型(diffusion)或 DiT 架构,例如 OpenAI 的 Sora 以及国内的可灵、即梦等。
这类模型将多模态生成与理解任务分别处理:生成任务通过扩散模型实现,而理解任务则以语言模型为核心,映射视觉信号至语言模型,所以是一种组合式的模型。
而智源发布的 Emu3,则是证明了“下一个 token 预测”在多模态模型中的可行性,实现了从 0 到 1 的技术突破。
这个可以被称为多模态大模型的“GPT-3 时刻”,表示这一技术路线可能开创多模态大模型的新训练范式:“Attention is all you need 开启了 Transformer 技术路线,那么,Next-token is all you need 可能会成为多模态大模型的新路径。”王仲远在与网易科技等媒体的沟通会上这样说道。
“现在,多模态大模型还在不断探索能力上限。智源探索出了 Emu3 这样一条技术路线,那么接下来需要展示,也期待在多模态领域的 ChatGPT 的时刻。”
图注:Emu3 在海外社媒中的反应
虽然目前关于通向 AGI 的道路仍是非共识,但像人类一样,能够理解并模拟物理世界的“世界模型”,已被行业内大多数视为通向 AGI 的关键路径之一。
OpenAI 前首席科学家、联合创始人 Ilya Sutskever 曾多次表示,只要能够非常好的预测下一个 token,就能帮助人类达到通用人工智能(AGI)。
站在 Emu3 发布节点,环顾四周:用于训练的文本数据逐渐枯竭,数据墙林立;硬件水平受限下,算力能力短时间很难突破;被奉为行业底层逻辑的 Scaling law,也被更多人质疑是否会在模型变大的过程中而失效。
然而,文本数据之外,图像、视频、音频乃至真实世界的数据是千倍于文本的巨量潜在资源。
怎么将更加海量的数据有效集成到大模型中进行训练?大语言模型的基础设施能否在多模态领域复用?Scaling law 到底有没有失效?一个原生的多模态大模型对行业意味着什么?通向 AGI 的道路,智源的下一步又会如何走?
瞄向“大问题”,坚持做原始创新的智源,用 Emu3 给出了他们的答案。
以下为智源研究院院长王仲远采访的部分内容(有删减):
谈 0 到 1 的突破:Emu3 是多模态大模型的 GPT3 时刻
媒体:Emu3 研发初衷和目标分别是什么?
王仲远:一方面,智源研究院坚持做原始创新,做高校做不了,企业不愿意做的研发。Emu3 是我们认为在整个大模型发展技术路线上必须要攻克的技术方向:原生多模态,统一理解和生成。另一方面,为多模态大模型的训练范式上指明方向,这是我们的初衷。Emu3 的意义很有可能会在一两年之后,大家会有更强烈的感知。
媒体:从 6 月份到现在,在 Emu3 的研发过程中做了哪些工作?
王仲远:对比 6 月,图像生成、视频生成能力都有了大幅的提升。
Emu3 的效果已经超越了很多开源模型,但还没有达到每一个方向上的最优。确实单向上现在很多闭源模型的能力非常强,Emu3 还没有超越闭源模型的能力。这是跟资源投入、训练时间有关。
但我们为什么如此有信心?因为现在的 Emu3 模型的能力比 6 月份又有了大幅的提升。Scaling law 在语言模型上有没有失效已经开始有些争论,但是在多模态大模型上还远没有打开。
在过去的小半年的时间,我们通过攻克一个又一个的技术难题,累积了不少核心技术、核心能力。在这期间,团队也遇到了不少的挫折,不断在绝望和希望之间挣扎。这就是科学探索的魅力,如果一帆风顺,就不是真正意义上的科学探索和创新。
媒体:Emu3 和市场上的现有的多模态大模型有什么区别?
王仲远:现有的多模态大模型没有类似 Emu3 的技术路线。Emu3 是对已有的多模态大模型技术路线的颠覆。但是这个颠覆并不是突然出来的,而是研究界、学术界、产业界一直都有探索的,只是智源率先做出来了。
媒体:Emu3 的发布有哪些重要意义?
王仲远:Emu3 的重要的意义是让语言模型的技术路线和多模态的技术路线不是一个分叉的关系,而是一个统一的关系。因为我们使用了跟大语言模型非常接近和类似的架构是 Autoregressive 做出了统一多模态大模型,这样可以极大地避免资源浪费。
媒体:Emu3 是如何实现图像、视频和文字的统一输入和输出的?
王仲远:Emu3 将文本、图像、视频各种模态的信息通过统一的 tokenizer 映射到一个离散空间,通过 Autoregressive 的方式进行统一训练。相当于发明了一种文字、图像、视频统一的“新语言”,这种语言能够在一个统一的空间里表达。
媒体:Emu3 的技术新范式和过去的范式有什么区别?
王仲远:第一,多模态肯定是大模型发展的下一个重要方向。现在的多模态,或者是基于 diffusion 架构来做生成,或者是组合式模型,即把语言模型与 CLIP 结合的范式。Emu3 所探索的是把生成和理解统一,把文字、图像、视频从原生上,从最开始训练的时候就统一,并且具备扩展性,而且使用的是 Autoregressive 的方式。这种类似于语言大模型的训练架构,能够解决大一统的问题。
第二,能够复用现有的硬件基础设施。同时我们也证明了 Scaling law,Emu3 比前两代的版本有了巨大的效果提升。这验证了这样的训练方式和框架,很有可能是下一代多模态大模型的训练范式。
之前的悟道系列,我们还在追赶大语言模型的 GPT3、 GPT 4 的阶段,但是到多模态,我们第一次先于国际社会发布,率先验证了新的大一统的原生多模态技术路线。
谈 Emu3 架构:One for world, world in one
媒体:Emu3 在哪些方面能体现出来便利?
王仲远:不需要去使用多种模型了,只需要一个模型解决所有的事情,One for world, world in one。
媒体:Emu3 的可用性如何?需要的硬件设备是怎样的?
王仲远:Emu3 对于硬件的要求跟大语言模型一样,这是非常重要的贡献之一。Emu3 使用大语言模型的一些硬件就能实现多模态大模型的训练和推理。
当然现阶段我们没有做特别多的工程化开发,智源将统一的 SFT 模型在开源社区发布,这样专业人士能体验到,并且能够做进一步的训练或者调优和各种能力的阐释。
大模型工业化,真正变成产品,是一个完整的体系,依赖底层的硬件,现在的底层硬件,GPU 的芯片,基本围绕像 Transformer 这样的架构进行优化。Diffusion 架构需要的硬件优化可能更多,每一个硬件的迭代周期至少要 18 个月到两年的时间。
走通基于 autoregressive 统一多模态的技术路线之后,可极大复用现有的基础设施,技术演化有可能会加速。Emu 3 证明 autoregressive 的技术路线至少是可行的,后面是进一步深耕,包括工程化。我们特别呼吁产业生态能够一起训练 Emu3 下一代应用系列的模型。
媒体:模型参数量减少,幻觉会不会更严重?
王仲远:首先简单介绍 Emu3 和 Emu 2 的技术区别。Emu2 视觉用的还是 embedding 的方式,Emu3 变成了离散的 token。
Emu1,Emu 2 是概念验证加探索迭代。当时用了预训好的语言模型和扩散的 decoder,快速验证统一的生成式是否能走通,智源是国际上最早做的探索。
因为不需要训练语言模型,基于已有的,成本会比较低。Emu3 我们是完全从头训练,是为视频图像文本原生多模态设计的。
媒体:Emu3 对于例如 DiT 的这种技术路线,或者前几代的一些技术路线,是降维打击还是完全替代?
王仲远:过去几十年深度学习发展专用模型,在特定的产品应用中有其独特之处。例如,人脸识别,即使大模型做到现在这个程度,也没有直接替换人脸识别的专用模型。在图像、视频特定的一些场景,DiT 架构有独特的优势。
但是 Emu3 大一统模型更重要的是更通用、泛化的能力以及理解和生成统一的能力上的独特优势。我们不期待立刻能够替换掉所有的 DiT 技术路线。
OpenAI 做 GPT1、GPT2 的时候,业界认为用 Bert 即可,bert 可以解决很多问题,可以做得更好,直到 ChatGPT 才统治了整个语言的问题。但是,现在 bert 还是有独特的价值。2006 年提出深度学习,2012 年深度学习爆发之后的很长一段时间,企业依然在用传统的 SVM 模型。
所以,替代的周期会比较长,但是技术的先进性是可以很容易做出判断的。
媒体:Emu3 视频好像最多 5 秒 24 的 FPS,这与其他预测模型的区别?
王仲远:下一个 token 天然的好处是本身就可以续写,看到前面的 token 预测后面的 token,可以无限续下去。
只是如果在一个场景续写,看到的长视频都是一个场景,意义不大。现在整体的续写能力还没有突破长的有情节的视频生成。
Emu3 这套框架的独特优势就是因果性,可以基于前面发生的事情预测后面发生的事情,而不是基于一堆噪声去想象。Emu3 现在可以 5 秒一直续写。
媒体:Emu3 的局限性是什么?
王仲远:卷积神经网络在视觉用的非常广泛,DiT 是过去这一两年新提出来的技术路线,效果确实比之前模型要好。DiT 技术路线已经走通了,从确定性的角度来讲,企业会更愿意复现这样的技术路线。基于 autoregressive 是更下一代的技术路线。
今天 Emu3 的发布,更多的证明在 autoregressive 这条技术路线上的突破。业内很多的企业、研究机构在关注这条技术路线的突破,本质上也是摸索下一代技术路线到底应该怎么走。智源有历史使命和职责去探索一条技术路线,期待能够为整个行业指明方向。
比如 Open Sora 是一个开源的集合很多能力复现的 diffusion transformer,取得了还不错的性能,但是离商业化还有一定差距。随着参数量、数据质量提升,训练效率提升,能达到什么样的水平?有比 Sora 更让大家想象不到的能力?是不是能打开更长的富有情节的推理能力?Emu3 是一个原生的大一统多模态,跟之前的多模态方法以及单一理解或者生成模型的能力不是一个类型。现在学术界为什么这么感兴趣?因为打开了一个新通道。
Emu3 探索出来的原生统一多模态大模型的一个新的技术范式,所需的资源并不比大语言模型小。但是 Emu3 的技术路线,能够极大可能复用现有的大语言模型训练的基础设施,比如,GPU 集群,训练框架不需要做特别大的修改,那么有望加速整个多模态大模型的迭代和最终产业应用。
谈未来方向:期待多模态领域的 ChatGPT 时刻
媒体:Emu3 为什么选择自回归的技术路线?
王仲远:我们一直强调智源的机构定位,要做企业不愿意做,高校做不了的原始创新。
大语言模型,市场已经复现了。所以在语言模型上智源更多的是解决共性的问题。例如,解决大语言模型共性问题的 BGE 模型,今年 10 月登顶了 hugging face 的全球下载量榜单的第一名。
智源要做下一代探索,做未来三至五年才会被行业认可的技术路线判断。在多模态大的研究方向上,一直没有探索出真正的基础模型。当下的多模态理解,多模态生成,比较像之前的深度学习的方法,针对特定的产品、特定任务,这对于 Scaling Law 或者 AGI 来讲,产业界现有的方法是不够的。
之前 Emu 系列做了不少基础工作,智源也在大语言模型上有很多积累。Emu 3 用的训练数据很大一部分来自于悟道 Aquila 大语言模型系列的训练数据,以及 Emu1 和 Emu2 训练的图像、视频数据。今年年初智源研究院也和一些机构,签署了战略合作协议。
过往智源在大语言模型上为行业带来了很多的技术思潮和方向。那么在多模态方向上,智源也需要为整个行业指明一个方向。
媒体:Emu3 下一步的规划和需要提升的能力是什么?
王仲远:例如,做更长的时间视频预测。Emu3 的技术路线理论上可以一直预测,生成下去。输入的窗口如何变大,输出如何变长,这些大语言模型已经正在走过很多的路径,对于多模态大模型有参考意义,这些问题我们会去探究。
媒体:对于通向 AGI 的路径怎么看?
王仲远:关于怎么达到 AGI 行业现在没有共识。关于语言模型能不能达到 AGI,现在有很多的争论,OpenAI 的 o1 确实证明了大语言模型加强化学习能够进一步的提升模型的智能化的水平,但它到底能不能通往 AGI 仍然有争论。
刚才提到像 Lecun,他就认为大语言模型不足以通向 AGI。我们认为 AGI 是要真正像人类一样,不只是思考推理,还必须是要多模态的。多模态是 AGI 的必经之路,尤其是人工智能进入物理世界,进入各行各业的必行之路。
媒体:智源未来三到五年之内的重点是什么?
王仲远:继续研发原生多模态世界模型 Emu 系列,解决更大规模的数据、算力以及训练。
统一多模态基座大模型是人工智能进入到物理世界非常重要的基座。多模态具身大脑也是研究院正在做的研究。
今年我们也看到了诺贝尔的物理学奖给了 Hinton 教授,化学奖是给了 DeepMind 团队。AI for Science 也是智源非常关注的重要研究方向。
媒体:从 c 端传播的角度来说,APP 肯定是最好的方式,未来,有没有计划和一些其他合作伙伴推出一些 c 端 APP?
王仲远:当前市场上的语言模型 APP 已经开始基于百亿模型在使用,这个前提是有了千亿、万亿模型,达到更高的性能,百亿模型效果随之更好。
我想再一次强调 Emu3 架构的优越性,将来多模态大模型都能够非常容易使用,这是 Emu3 模型的意义。
现在,多模态大模型还在不断探索能力上限。智源探索出了 Emu3 这样一条技术路线,那么接下来需要展示,也期待在多模态领域的“ChatGPT” 的时刻。






