
新智元报道
编辑:桃子
Mistral 7B 诞生一周年之际,法国 AI 初创公司 Mistral 再次连发两个轻量级模型 Ministral 3B 和 Ministral 8B,性能赶超 Llama 3 8B。
Mistral 7B 仅仅发布一周年,法国 AI 初创小模型「les Ministraux」就打败它了。
它堪称是,世界上最好的边缘模型。

Ministral 3B 和 Ministral 8B 这两款轻量级模型,专为边缘设备打造。
截至目前,它们正式加入 Mixtral、Pixtral、Codestral、Mathstral 行列,成为 Mistral 一员。

别看仅有 30 亿参数,在指令跟随基准上,完全超越了 Llama 3 8B,以及前辈模型 Mistral 7B。
而且 Ministral 3B 和 Ministral 8B 在大模型竞技场中的测试,均拿下了媲美 Gemma 2、Llama 3.1 开源模型的成绩。
世界上最好的边缘模型
Ministral 3B 和 Ministral 8B 都支持高达 128k 上下文(目前在 vLLM 上为 32k)。
在知识、常识、推理、函数调用、效率等方面,为低于 10B 参数模型设立了新标杆。
而且,Ministral 8B 还有配备了滑动窗口注意机制(sliding-window attention),以实现更快和内存高效的推理。
不论是管理复杂的 AI 智能体工作流,还是创建专门的任务助手,它们均可以被微调到各种用例中。

赶超开源模型,击败 Mistral 7B
研究人员在多项基准测试中,评估了 Les Minimrau 的性能。
其中包括知识与常识、代码、数学、多语言四大方面。
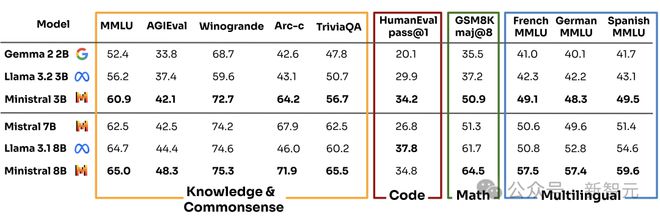
预训练模型
如下图所示,与 Gema 2 2B、Llama 3.2 3B 相比较,Minstral 3B 在以上基准上,取得了最优成绩。
在与 Llama 3.1 8B、Mistral 7B 相比较过程中,仅有代码能力,Minstral 8B 还有些差距,其余放方面均是性能最高的模型。
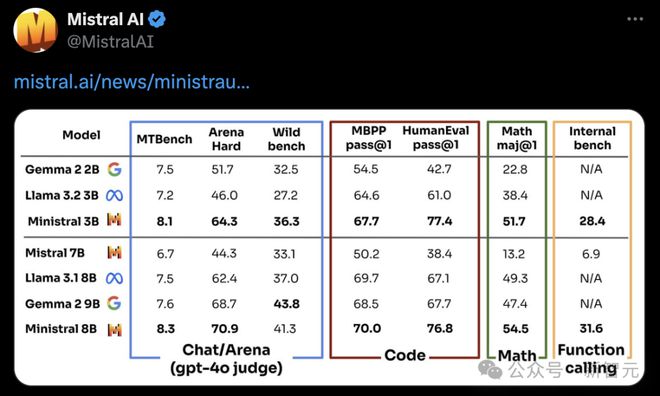
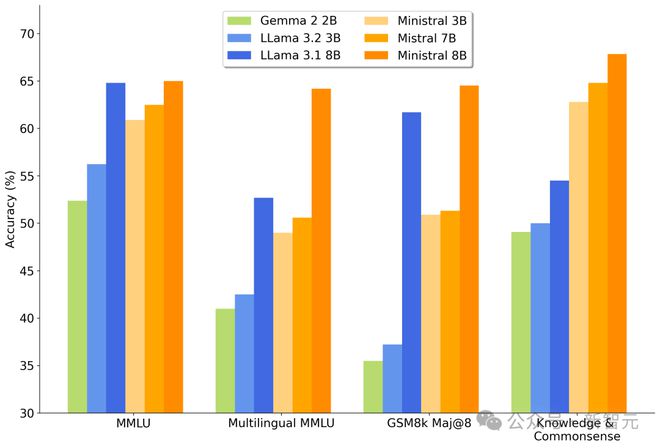
如下是,更加直观可视化柱状图,Minstral 8B 在各项评测中,占据首位。
指令模型
再来看微调后的指令模型,性能比较的结果。
在大模型竞技场中,Minstral 3B 在不同基准上,实现了最优。Minstral 8B 仅在 Wild bench 上,略逊于 Gema 2 9B。
另外,在代码、数学、函数调用方面,两款新模型性能大幅超越其余模型。
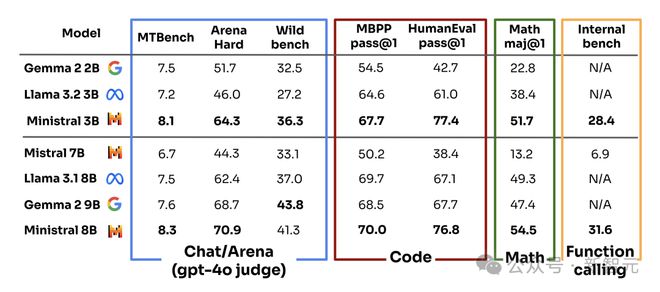
下图,可以直观看出指令微调后的 Minstral 3B 比更大的 Mistral 7B 的改进。
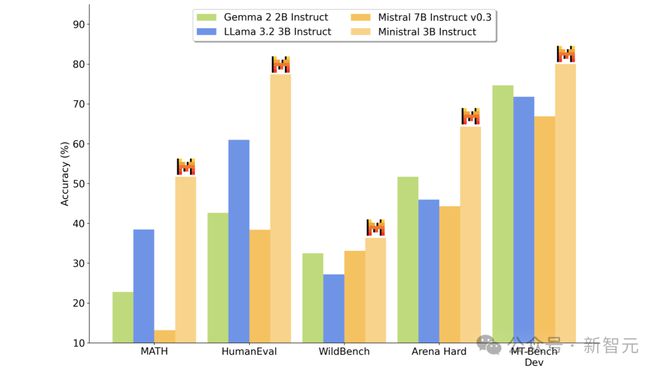
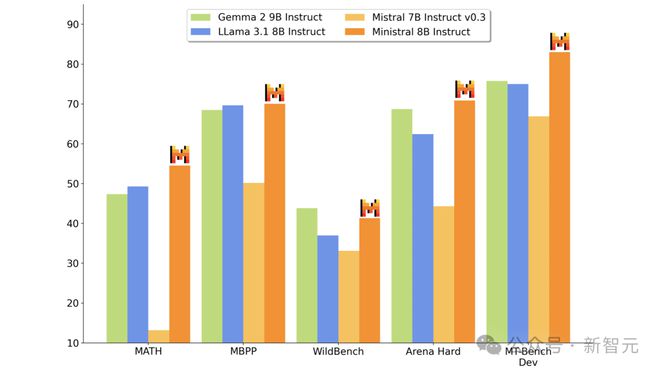
如下是指令微调后的 Minstral 8B 模型,与其他模型的性能对比直观图。
边缘计算皆可用,0.1 美金百万 token
如今,大模型在实际落地中,不如小模型来的更切实际。
越来越多的用户,希望对关键应用程序能够进行本地优先推理,比如设备上翻译、不用联网智能助理,自动机器人等等。
正如官博所述,Les Minimraux 正为这些场景,提供了高计算效率、低延迟的解决方案。
当与 Mistral Large 等更大的模型结合使用时,les Ministraux 还可以作为多步智能体工作流中,进行函数调用的高效中介。
通过微调,它们能以极低的延迟和成本基于用户意图,跨多个上下文处理输入解析、任务路由和调用 API。
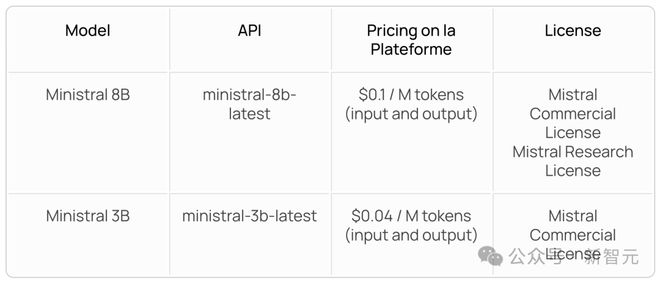
价格
根据官方公布的价格所示,Minstral 8B 输入输出价格为百万 token,0.1 美元。Minstral 3B 则为百万 token0.04 美元。
开源版 OpenAI,不再 Open
自去年成立以来,Mistral 曾以磁力链方式开源了多款媲美 OpenAI 的模型,一路走红得到 AI 社区的认可。
这家总部位于巴黎的 Mistral,由 Meta、谷歌 DeepMind 前员工创立。

几个月前,它以 60 亿美金估值,完成 6.4 亿美元新一轮融资,并随之推出了一款 GPT-4 级别的模型——Mistral Large 2。
此外,他们在今年,还推出了一个专家混合模型 Mixtral 8x22B。
它包含了一个编码模型 Codestral,以及一个数学推理和科学发现的模型。

不过,今年这家明星公司陷入了巨大争议,因为它变得不再那么 open。

年初,有消息爆料称,微软宣布将收购 Mistral 一些股份,并对其投资,意味着它的模型将在 Azure AI 进行托管。
甚至,还有 Reddit 网友发现,Mistral 已从官网中,移除了致力于开源的承诺。
在一些模型的调用上,Mistral 也开启了收费模式,包括这次同样如此。
有网友就此吐槽,不是开源的。
要知道,对于一家初创公司来说,一直坚持开源代码是一个巨大的挑战。
就比如反面教材 Stability AI,完全放弃了开源的商业模式,也转向了收费策略。
对于 Mistral 也是如此,若要持续打造优秀的模型,只有这一种选择。
参考资料:






