近年来,文本到图像的生成技术取得了显著进展,这尤其得益于潜在扩散模型(Latent Diffusion Models)的提出与应用。
潜在扩散模型由 Rombach 等人于 2022 年首次提出[1],它是一种通过在预训练的自动编码器生成的潜在空间中进行扩散与逆扩散的技术。由于潜在空间中的维度较低,因此,相比直接在像素空间中操作,它大大降低了计算量,进而使我们能在较低的计算资源需求下实现高质量的图像生成。
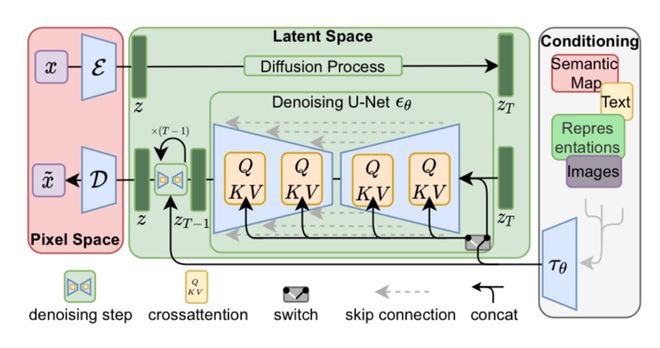
图丨潜在扩散模型概览(来源:arXiv)
但另一方面,许多模型的参数却不断扩大。从 PixArt 的 0.6B 参数到 Flux 的 12B 参数,其训练和推理的成本始终居高不下,使用门槛也较高,这显然不利于技术的进一步发展。
因此,如何在保持图像质量的前提下,开发出计算效率高、运行速度快且易于使用的图像生成器,成为了一个重要的问题。
正是在这一背景下,英伟达联合麻省理工学院与清华大学团队,发表了一篇预印本论文,提出了一种新的文生图框架 Sana,能够高效生成最高分辨率为 4096×4096 的高质量图像,对这一难题做出解答[2]。

图丨论文标题《Sana:利用线性扩散变换器实现高效的高分辨率图像
相比于传统的大型扩散模型,Sana 在模型大小上显著缩减,并在推理速度方面实现了巨大的提升。在生成 1K 分辨率图像时,Sana-0.6B 速度比当前最先进的模型 FLUX 快了 40 倍以上。而 Sana 之所以能在性能与效率之间实现良好的平衡,归功于其核心架构的一系列革新。
Sana 的优势首先得益于其所使用的深度压缩自动编码器(Deep Compression Autoencoder)。传统的自动编码器通常只能将图像的长度和宽度压缩 8 倍,Sana 采用了一种新的自动编码器,压缩倍数高达 32 倍。
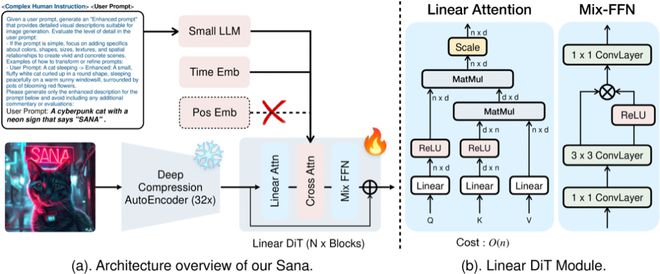
图丨 Sana 概述(来源:arXiv)
这种高倍数的压缩显著减少了潜在 token 的数量,从而降低了训练和推理的计算量,特别适用于超高分辨率图像的生成。通过这种方式,Sana 得以在降低计算开销的同时,保证了生存图像的质量,做到了高效率与高质量的兼得。
其次,Sana 采用了一种高效的线性 DiT (Linear Diffusion Transformer)来替代传统的二次方复杂度的自注意力模块。以往的自注意力机制计算复杂度为 O (N²),在处理高分辨率图像时为二次增长,因而需要大量的计算资源。
而 Sana 通过使用线性注意力,将计算复杂度降低至 O (N),由此显著提高了处理高分辨率图像时的计算效率。
同时,研究团队还引入了 Mix-FFN 模块以替代 MLP-FFN,将 3×3 深度卷积整合到多层感知器(Multilayer Perceptron,MLP)中,从而更好地聚合 token 的局部信息。结果表明,这种模块设计使得线性注意力在性能上与传统的自注意力相媲美,但在生成 4K 图像时,其延迟缩短了 1.7 倍。
而且,Mix-FFN 无需位置编码(NoPE)就能保持生成性能,是首个完全省略位置嵌入的 DiT。
Sana 的另一处创新在于对文本编码器的选择。团队使用了最新的仅解码器式小型 LLM Gemma-2 作为文本编码器,以增强对用户提示的理解和推理能力。
与之前广泛使用的 T5 或 CLIP 编码器相比,Gemma-2 具有更强的文本理解和指令跟随能力,在理解和生成用户提示方面表现更加优秀,从而使生成的图像在内容和细节上更符合预期。
并且,研究人员通过设计复杂的人类指令(Complex Human Instruction,CHI),结合上下文学习,进一步提高了 Sana 的文本-图像对齐能力。
为了进一步提高训练和推理的效率,团队还提出了一套高效的训练和采样策略。
在训练过程中,Sana 使用多种视觉语言模型(Visual Language Model,VLM)对图像进行自动标签,并通过基于 Clipscore 的采样策略来选择最合适的标签,从而提高训练的收敛速度和文本与图像的对齐程度。相比于传统的随机选择标签的方法,这种策略显著减少了训练过程中的不确定性,并加速了模型的收敛。
在推理阶段,团队提出了 Flow-DPM-Solver 采样方法,将采样步骤从传统的 28-50 步减少至 14-20 步,并且在采样质量上实现了进一步提升。这种改进不仅提高了采样的效率,还在很大程度上降低了计算资源的需求,使得 Sana 能够在较低的硬件配置上运行。
实验结果表明,Sana-0.6B 不仅在参数数量上远小于许多现有的扩散模型,而且在计算速度上也有显著的优势。在一张 16GB GPU 的 PC 端上,Sana-0.6B 可以在不到 1 秒的时间内生成分辨率为 1024×1024 的图像,这意味着它在低成本的内容创作和边缘设备部署上具有极大的应用潜力。
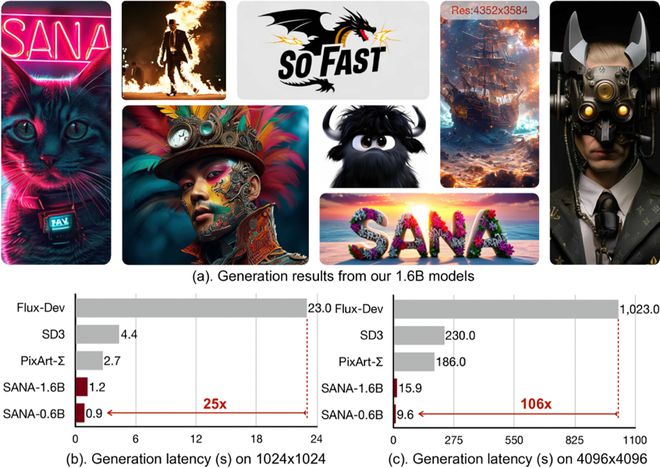
图丨 Sana 生成的图像及其推理延迟(来源:arXiv)
而在生成 4096×4096 的高分辨率图像时,其推理延迟也仅为 9.6 秒。相比之下,当前最先进的 FLUX 模型需要 469 秒才能完成同样的任务。
进一步的测试显示,在 1024×1024 分辨率下,Sana 的生成速度比 LUMINA-Next、SDXL 以及 PixArt-Σ 等同类模型均快了数倍,同时保持了非常高的生成质量。
在生成性能上,Sana-0.6B 的每秒吞吐量达到了 1.7 张图像,而且参数量为 1.6B 的 Sana 版本也能实现 1.0 张每秒的速度,这表明 Sana 在维持高图像质量的前提下依旧具备极高的推理效率。

图丨 Sana 与 SOTA 方法在效率和性能方面的差异(来源:arXiv)
总结来说,Sana 为高效的高分辨率图像生成提供了一个有潜力的基础模型,其显著的计算效率和速度优势,使得高分辨率图像生成技术向低成本、低门槛方向迈出了重要的一步。未来,团队计划基于 Sana 构建高效的视频生成流程,将其应用拓展至动态内容生成领域。
相关代码即将公布在 GitHub(项目地址:https://github.com/NVlabs/Sana)。
参考资料:
1. https://arxiv.org/abs/2112.10752
2. https://arxiv.org/abs/2410.10629
运营/排版:何晨龙






