
新智元报道
编辑:编辑部
一夜之间,全球最强开源模型再次易主。万众瞩目的 Qwen2-72B 一出世,火速杀进开源 LLM 排行榜第一,美国最强开源模型 Llama3-70B 直接被碾压!全球开发者粉丝狂欢:果然没白等。
一觉醒来,中国的开源模型再次震撼了全世界。
坐等许久,Qwen2-72B 终于发布了!这个模型一出世,直接杀进开源 LLM 排行榜第一,完全碾压美国最强的 Llama3-70B。
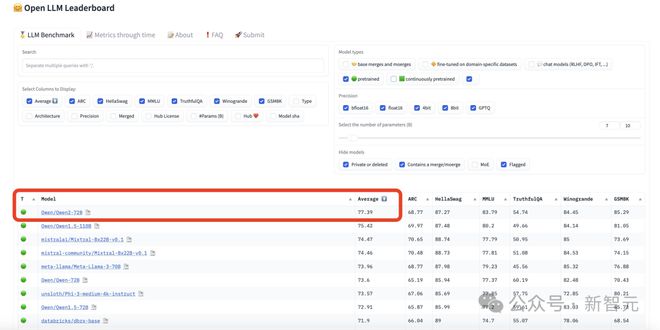
有趣的是,第二名也是来自阿里的 Qwen1.5-110B
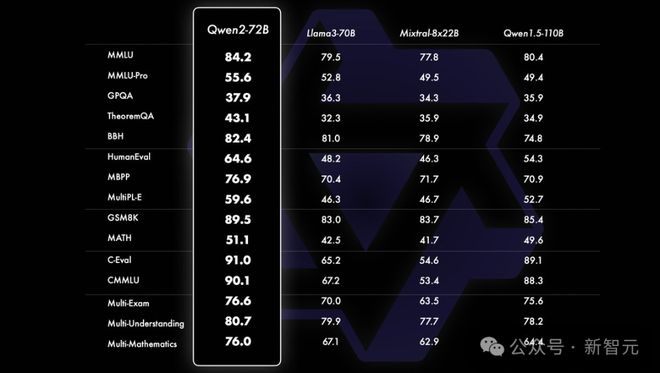
在各大基准测试中,Qwen2-72B 一举斩获了十几项世界冠军,尤其在代码和数学能力上提升最为明显。

同时,相较于上一代 Qwen1.5,Qwen2 也实现了大幅的性能提升。
另外,开源 Qwen2-72B 还击败了国内一众闭源大模型,包括文心 4.0、豆包 Pro、混元 Pro 等等。
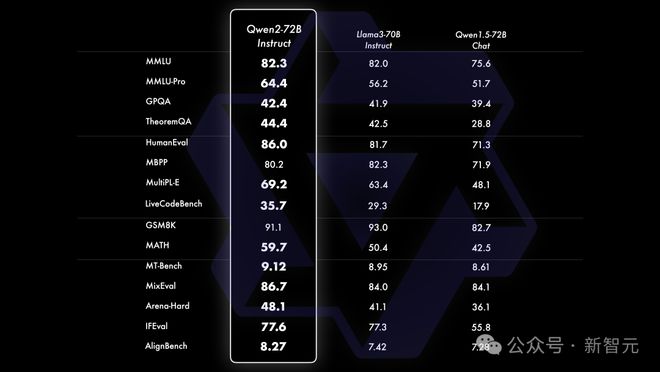
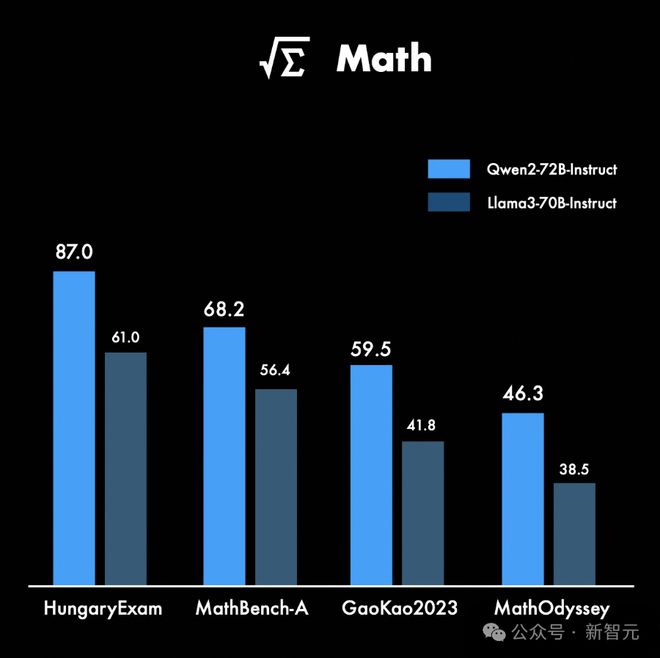
72B 指令微调版模型,还增大了上下文长度支持,最高可达 128k token。在 16 个基准测试中,Qwen2-72B-Instruct 的性能可与 Llama-3-70B-Instruct 相匹敌。
得益于高质量的数据,Qwen2-72B-Instruct 在数学、代码能力上实现飞升。
值得一提的是,模型训练过程中,除了采用中英文数据,还增加了 27 种语言相关的高质量数据。
现在,所有人均可在魔搭社区和 Hugging Face 免费下载 Qwen2 最新开源模型。
凭借取得的卓越性能,Qwen2-72B 深受 AI 大佬们关注,在整个 AI 圈掀起了轩然大波。
模型刚发布 2 小时,HugingFace 联创 Clément Delangue 立即宣布,「HF 大模型榜上诞生了一个全新的、排名第一的开源模型——Qwen2-72B」。

AI 初创 CEO 称,「一切都结束了!OSS 迎来了一位新王者——Qwen-2 的 MMLU 为 84.32,完全堪称 GPT-4o/Turbo 级别模型」!

4 个月不到的时间,Qwen-2-72B 的生成质量已经和 GPT-4 不分伯仲。
网友震惊发现,在编码上 Qwen2 绝对超越了 Llama 3!
加冕为王的 Qwen2-72B 究竟有多强,接下来让我们一起来看看。

开源新王 Qwen2-72B 发布!
差不多 4 个月时间,阿里团队就完成从 Qwen1.5 到 Qwen2 跨越式的迭代升级。
除了 Qwen2-72B,Qwen2 系列包含了 5 种不同参数规模的预训练和指令微调模型。
其中还有,Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B,都可支持 32K 上下文。
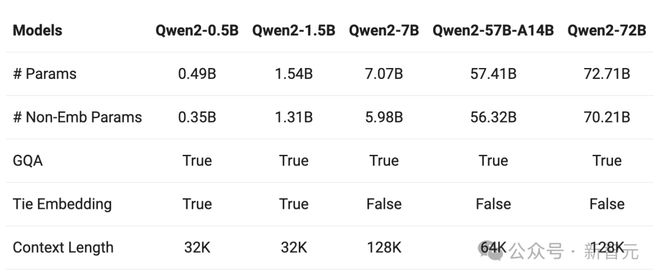
相比 2 月推出的通义千问 Qwen1.5,Qwen2 实现了整体性能的代际飞跃。
在权威模型测评榜单 OpenCompass 中,此前开源的 Qwen1.5-110B 已领先于文心 4.0 等一众国产闭源模型。
刚刚开源的 Qwen2-72B,整体性能相比 Qwen1.5-110B 又取得了大幅提升。
开篇一张表,很明显地可以看出 Qwen2-72B 在数学(GSM8K、MATH),以及代码(C-Eval)、逻辑推理(CMMLU)、多语言能力上(MMLU),取得了明显的提升。
其性能大幅超越了著名的开源模型 Llama3-70B、Mixtral-8x22B。尤其是在代码、逻辑推理上,领先对手 20+ 分。
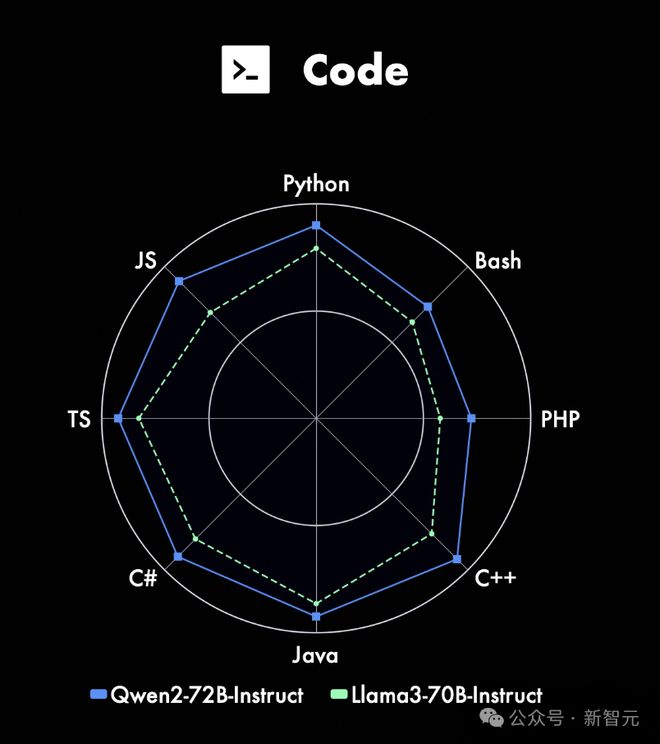
指令微调版的 Qwen2-72B-Instruct,汲取了 CodeQwen1.5 强大的代码经验,并将其融入研发。
结果如下,在 8 种编程语言上,尤其是 JS、C++,Qwen2-72B-Instruct 性能超越 Llama-3-70B-Instruct。
在数学上,Qwen2-72B-Instruct 同时实现了数学能力显著提升,在如下四个基准测试中,性能分别超越了 Llama-3-70B-Instruct。
另外,小模型方面,Qwen2 系列基本能够超越同等规模的最优开源模型,甚至更大参数规模的模型。
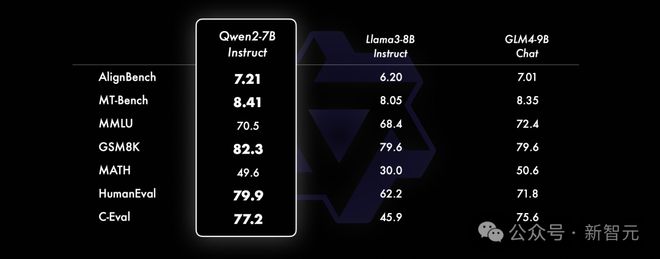
比起 Llama3-8B-Instruct,Qwen2-7B-Instruct 能在多个评测上取得显著的优势,尤其是代码及中文理解上。
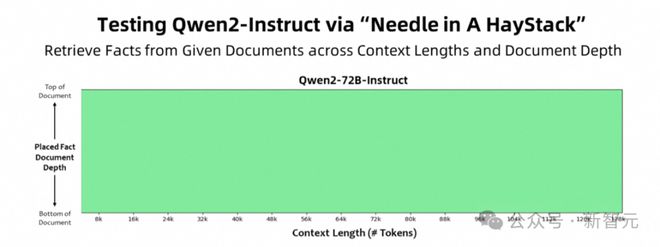
最高 128k,大海捞针全绿
Qwen2 系列中,所有的 Instruct 模型均在 32k 上下文中,进行了训练。
在大海捞针实验中,Qwen2-72B-Instruct 能够完美处理 128k 上下文长度内的信息抽取任务,实现了全绿的成绩。
如果有足够的算力,72B 指令微调版凭借其强大的性能,一定可以成为处理长文本任务的首选。
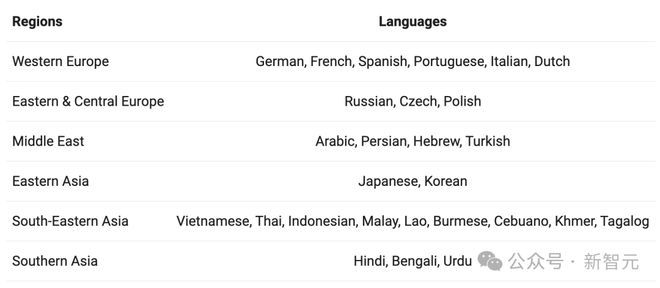
更值得一提的是,为了提升模型多语言能力,研究人员还针对性地对除中英文以外的 27 种语言进行了增强:
比如阿拉伯语、法语、荷兰语等等。
在阿拉伯语榜单上,Qwen2-72B 性能直接刷榜。
安全性堪比 GPT-4
当然,模型安全也是训俩过程中,至关重要的一部分。
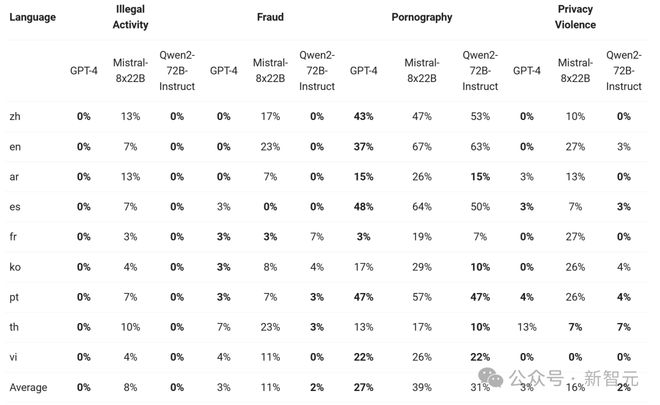
如下,展示了大模型在四种多语言不安全查询类别(非法活动、欺诈、色情、隐私暴力)中生成有害响应的比例。
通过显著性检验(P值),看得出 Qwen2-72B-Instruct 模型在安全性方面,与 GPT-4 的表现相当,并且显著优于 Mistral-8x22B 模型。
坚持开源,唯一引起 Altman 注意的国产大模型
依靠着强大研发能力、领先的基础设施能力,以及开源社区的充分支持,通义千问大模型一直在持续优化和进步。
2023 年 8 月,这个消息振奋了国内 AI 圈:阿里云成为国内首个宣布开源自研模型的科技企业,推出第一代开源模型 Qwen。
而在随后不到一年时间,通义先后开源了数十款不同尺寸模型,包括大语言模型、多模态模型、混合专家模型、代码大模型等等。
这种开源频率和速度,可以说是全球无二,模型性能也在随着版本迭代肉眼可见地进化。
而自 Qwen-72B 诞生后,Qwen 系列更是逐渐步入全球大模型竞争的核心腹地,在权威榜单上,多次创造中国大模型的「首次」!
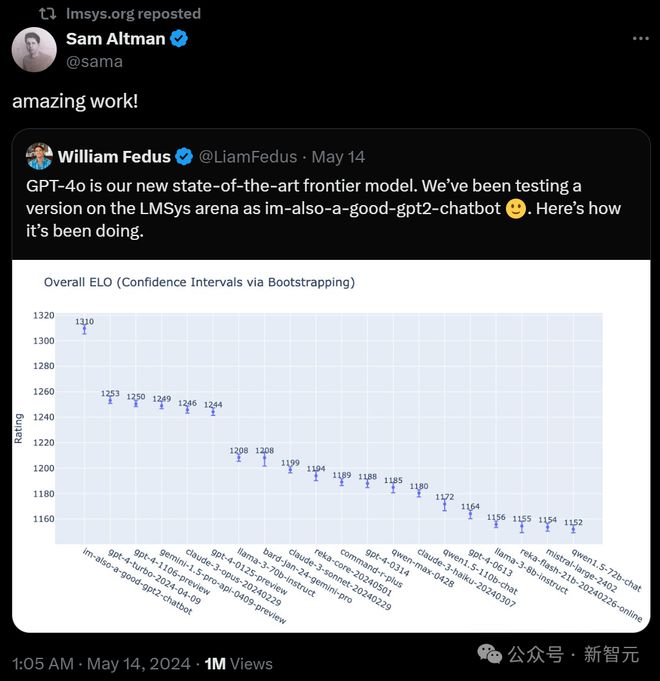
不久前,奥特曼在X上转发了一条 OpenAI 研究员公布的消息,GPT-4o 在测试阶段登上了 Chatbot Arena(LMSys Arena)榜首位置。
这个榜单,是 OpenAI 唯一认可证明其地位的榜单,而 Qwen,正是其中唯一上榜的国内模型。
多次冲进 LMSys 榜单的国产大模型,只此一家
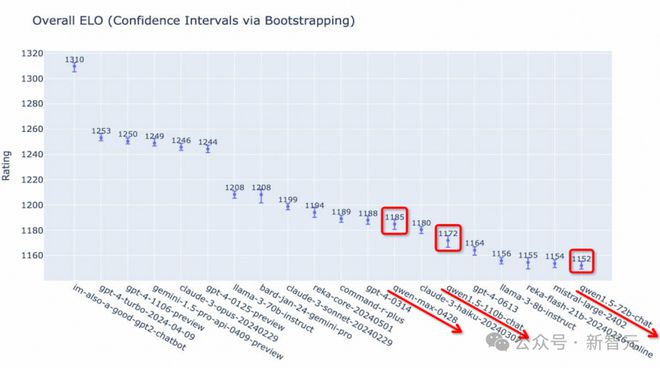
另外,早些时候有人做了个 LMSys 榜单一年动态变化的视频。
结果显示,过去一年内,国产大模型只有 Qwen 多次冲进这份榜单。
最早出现的,是通义千问 14B 开源视频 Qwen-14B,然后就是 Qwen 系列的 72B、110B 以及通义千问闭源模型 Qwen-Max。
而且,它们的得分一个比一次高,LMSys 也曾官方发推,认证通义千问开源模型的实力。
可以看出,在顶尖模型公司的竞争中,目前为止,中国模型只有通义千问真正入局,能与头部厂商一较高下。
爆火全球 AI 社区,歪果仁:真香
如今,Qwen 系列模型已经在全球范围内爆火,成为最受外国开发者瞩目的中国开源模型之一。
在不到一年时间,通义千问密集推出了 Qwen、Qwen1.5、Qwen2 三代模型,直接实现了全尺寸、全模态的开源。
就在最近一个月内,Qwen 系列的总下载量已经翻了倍,直接突破 1600 万次。
与此同时,在海内外开源社区,基于 Qwen 二次开发的模型和应用,已经出现超过 1500 款!
其实,早在今年 2 月 Qwen1.5 发布前后,就有大量开发者在线催更 Qwen2。
开发者用脚投票的结果,直接显示了 Qwen 系列有多受欢迎。
在网上冲浪的时候,会明显发现 Qwen 的很多忠实拥趸都是海外开发者,他们时常在社交平台发表「我们为什么没有这种模型」的溢美之词。
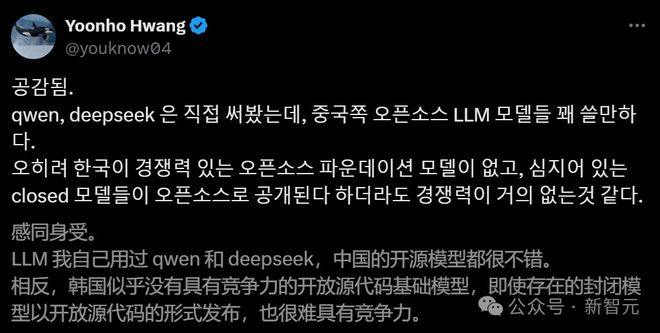
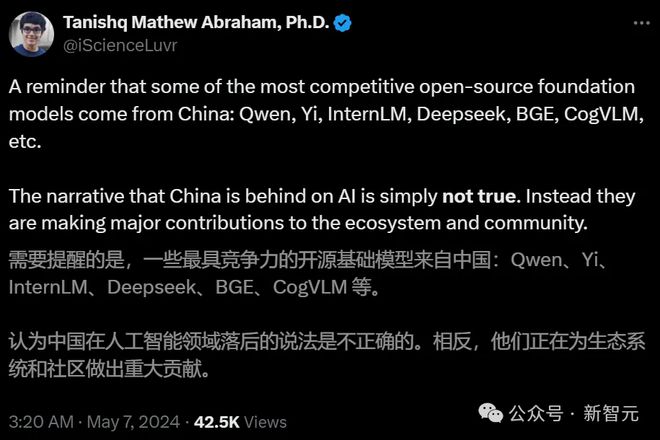
19 岁获得博士的 Stability AI 研究主任 Tanishq 表示,以 Qwen 为代表的最有竞争力、为开源生态做出重大贡献的开源基础模型,就是来自中国。
6 月 7 日晚 24 点左右,众望所归的 Qwen2 上线后,也迅速获得多个重要的开源生态伙伴的支持。
其中包括,TensorRT-LLM、OpenVINO、OpenCompass、XTuner、LLaMA-Factory、Firefly、OpenBuddy、vLLM、Ollama 等。
可以说,通义大模型用行动证明了开源开放的力量。
商业模型更具前景
阿里云是全球唯一一家积极研发先进 AI 模型,并且全方位开源的云计算厂商。
坚持自研与开源,也让阿里云的商业模型更具前景。
在未来的大模型市场,不可能是一个模型能适应所有需求,也不可能只有一种模型服务方式(API)。
开源模型把选择权交给了企业和开发者,让能用户在场景、性能、成本之间,找到理想的配比。
其实,从自身主观来说,这也正是云厂商的本质使然。
云计算算力集中、灵活部署、按需付费、成本较低的特点,天然就适配大规模的推理需求。
在 5 月,阿里云发起「击穿全球底价」的大模型 API 降价,目的正是加速 AI 应用爆发。
如今,坚持做「国货」的阿里云,也在坚持着开放路线。
卷价格,抑或是卷模型本身,都是在为激活 AI 行业生态贡献力量,加速应用爆发,从而形成有国际竞争力的技术体系和话语体系。
生态建设
如今,AI 大模型已成全球数字技术体系的竞争,这个体系包括芯片、云计算、闭源模型、开源模型、开源生态等等。
中国信息化百人会执委、阿里云副总裁安筱鹏指出,全球 AI 大模型竞争的制高点,就是 AI 基础大模型,因为它决定了产业智能化的天花板,商业闭环的可能性,应用生态的繁荣以及产业竞争的格局。
与此同时,开源生态在整个技术体系的竞争中也有着至关重要的作用。
优质的开源模型,让海量的中小企业和开发者免于从头开始训练大模型,直接站在前沿技术成果的肩膀上做创新。就好比从海拔 0 米的地方把人运送到 5000 米的珠峰大本营,再去爬剩下的 3000 米。
阿里云持续开源自研模型,牵头建设中国最大的 AI 开源社区魔搭,正是为了推动 AI 应用门槛的降低。
如今,大模型应用创新的奇点还没有到来。
当大模型的大部分潜力被真正挖掘出来,当越来越多开发者和企业结合自己需求,促进大模型的发展和应用,届时必将发生天翻地覆的变化。
参考资料:






