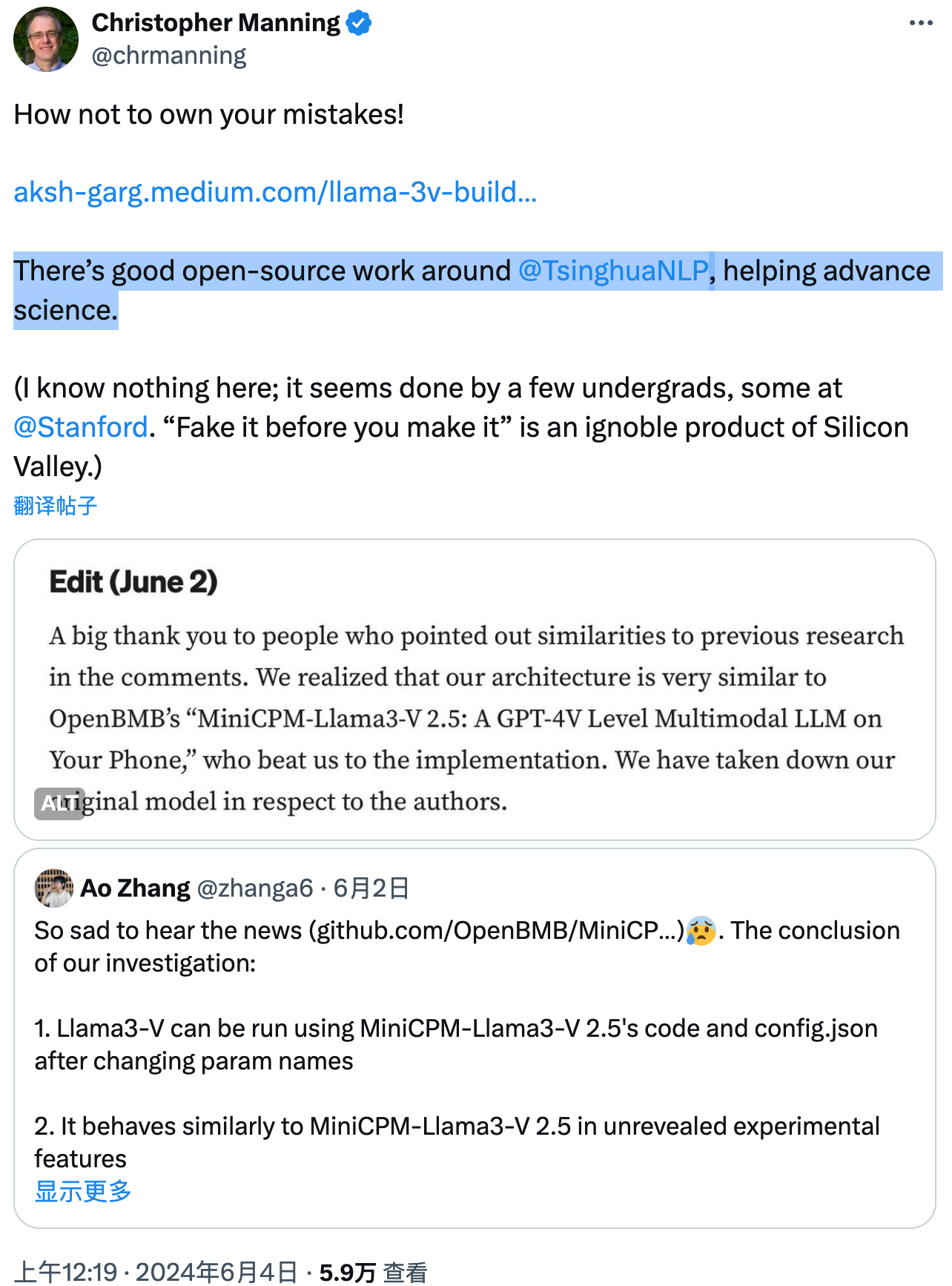
斯坦福 AI 团队 (Llama3-V)“镜像级套壳” 清华系开源大模型 (MiniCPM-Llama3-V 2.5) 事件近日引发巨大关注 —— 让人不禁感叹一句 “国内一开源,国外就自主”。

调侃归调侃,斯坦福 AI 团队抄袭事件相关的三名成员都有着卓越的学术和技术研发背景,并且在 AI 模型领域有着深厚的积累。他们本应避免将他人的成果直接宣称为自己的,这种做法无疑是违背了开源社区所推崇的共享精神。
此外,社区中的一些开发者也注意到了一个现象。在这次抄袭事件中,三人敢于公开抄袭 MiniCPM,这背后可能基于一个判断:中国的开源模型虽然十分强大,但在国际社区中的知名度并不高。
MiniCPM 作为一个极其强大的开源模型,在发布后并没有得到应有的关注,反而是其套壳的海外版本意外走红。直到抄袭事件曝光,许多本应持续关注开源社区优秀作品的研究者才意识到 MiniCPM 的存在。
https://x.com/chrmanning/status/1797664513367630101
就连抄袭事件的主角之一也在回应中所表示,他们 “看了很多最近的论文以验证这项工作的创新性,但却并不知道也未被告知有关 OpenBMB 的任何先前工作”。
有 DeepMind 的工程师就指出,这件事里有意思的地方是,相比造假的 Llama3-V,MiniCPM 是真的存在的能达到如此强大能力的模型。但是它获得的关注是如此之少。同样的结果,就因为不是来自一些常青藤大学,就无法流行起来。

https://x.com/giffmana/status/1797603360230760471
还有一位国外 AI 社区的创始人也说道:“中国在机器学习生态的工作一直以来都被社区忽视了。他们正在用有趣的 LLM、VLM、音频和扩散模型做一些令人惊奇的事情。”

https://x.com/osanseviero/status/1797635895610540076
事实上,中国大模型在国际社区中确实有非常好的口碑。
通义千问不久前开源千亿参数大模型 Qwen1.5-110B 就在国外社区引起巨大反响,持续占领了 Hacker News 热度榜首一段时间。
当时 Stability AI 研究主管 Tanishq Mathew Abraham 说道:
“许多最具竞争力的开源大模型,包括 Qwen、Yi、InternLM、Deepseek、BGE、CogVLM 等正是来自中国。
关于中国在人工智能领域落后的说法完全不属实。相反,他们正在为生态系统和社区做出重大贡献。”

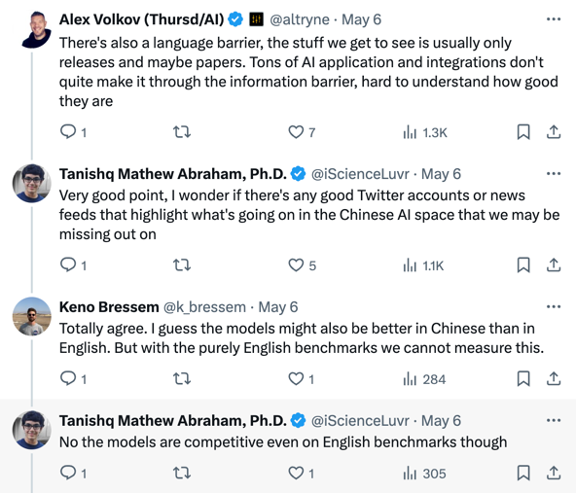
还有人表示,由于中英文间的语言障碍,海外通常能看到中国大模型也只是发布的一部分,太多 AI 应用和集成没有被完全展现。推测这些模型在中文上表现应该比英文更好。但即便如此,它们在英文基准测试上已具备相当的竞争力。
也有人称自己属实被过去一年中 Arxiv 上 AI 论文里中文署名作者的庞大数量震惊到了。

前斯坦福兼职讲师、Claypot AI 联合创始人 Chip Huyen 在调研过 900 个流行开源 AI 工具后,在个人博客中分享自己的发现:“在 GitHub 排名前 20 的账户中,有 6 个源自中国。

OpenAI 早期投资人 Vinod Khosla 曾在 X 发文称,美国的开源模型都会被中国抄去。
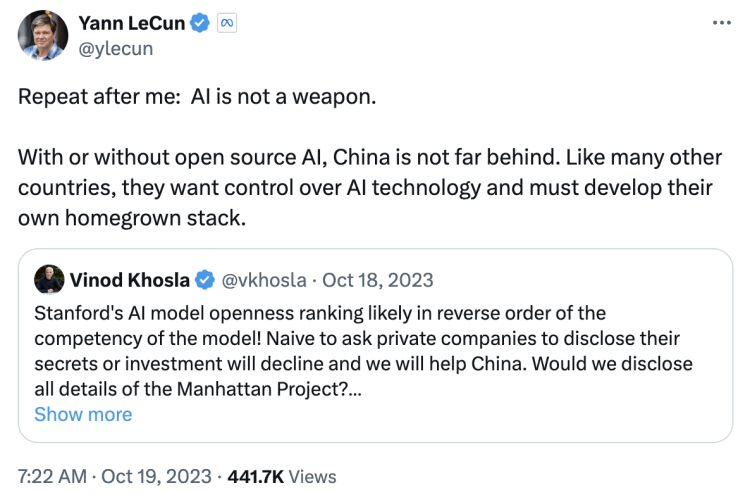
但这番言论马上被 Meta 的 AI 教父 Yann LeCun 反驳:“AI 不是武器。无论我们是否把技术开源,中国都不会落后。他们会掌控自己的人工智能,开发自己的本土技术栈。”
还有在斯坦福读书的同学也分享称,教授在课堂上大力称赞中国开源模型,特别是开诚布公地与社区积极分享成果,跟欧美一些头顶 “开源” 名号的明星公司不同。

有网友也表达了和这个教授相似的观点,“美国最该尴尬的,是今天中国开源模型们重大的贡献”。
Reference:https://mp.weixin.qq.com/s/WctorGul9oMjPlzpscRvhg






