克雷西发自凹非寺
量子位公众号 QbitAI
鹅厂搞了个 150 多人的“翻译公司”,从老板到员工都是 AI 智能体!
主营业务是翻译网络小说,质量极高,参与评价的读者认为比真人翻译得还要好。
而且相比于雇佣真人,用它来翻译文学作品,成本降低了近 80 倍。

公司名为 TransAgents,每个岗位都配备了 30 个不同的职工,能够根据语言、体裁和目标受众适配不同的翻译风格。
相比于传统的翻译,产出的译文更加灵活多样,也更符合目标语言的表达习惯,文学性也更强。
所以,TransAgents 虽然在以相似度为基础的自动评估中“失败”,却赢得了读者和专业人士的大力肯定。
这样的表现甚至让人感叹说,或许人类对人工智能生成的内容更加青睐的时代,就要来了。
还有人表示,TransAgents 是证明自己错看了人工智能的又一证据——本以为由于模型限制,小说的翻译对 AI 会极其困难,结果 AI 智能体把这个任务完成得非常好。
所以,TransAgents 到底有没有那么神呢?
真人和 GPT-4 都说好
为了评估 TransAgents 的翻译质量,作者选择了 WMT2023 数据集,需要对其进行篇章级的文学翻译。
该数据集从 12 部网络小说中各截取了 20 个连续的章节,涉及如下八种类型:
- 游戏类(Video Games,VG)
- 东方玄幻类(Eastern Fantasy,EF)
- 科幻爱情类(Sci-fi Romance,SR)
- 当代爱情类(Contemporary Romance,CR)
- 玄幻类(Fantasy,F)
- 科幻类(Science Fiction,SF)
- 恐怖惊悚类(Horror & Thriller,HT)
- 玄幻爱情类(Fantasy Romance,FR)
起初,作者使用d-BLEU 进行了自动评估,该方法会与参考样本进行相似度计算,相似度越高得分也就越高。
具体到本项目当中,参考样本一共有两组,样本一是人工给出的翻译结果,样本二是对网络中的双语文本进行对齐后得到。
结果,TransAgents 的得分并不理想,只有 25 分,连 SOTA 的一半都不到。
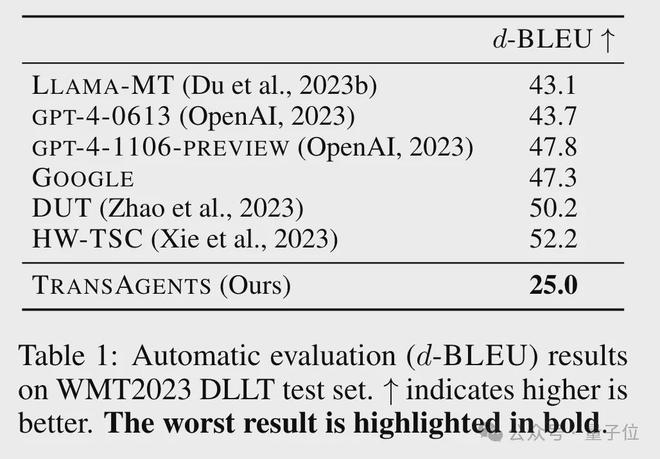
但这并不意味着 TransAgents 的翻译质量不行,而是因为用相似度来衡量文学作品翻译的表现,本身就有失偏颇。
文学翻译不是逐字对照,而是需要在语义、语气、风格等方面进行创造性的转换,这些转换可能导致译文与参考译文在表面上差异较大,相似度不高自然就不意外了。
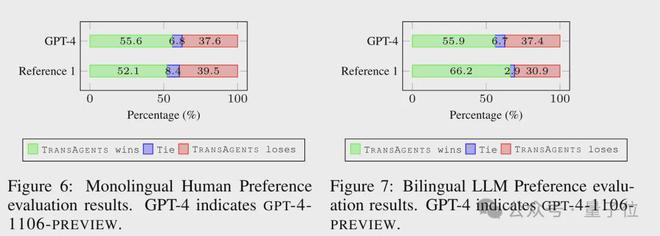
所以,作者干脆直接让真人(至少 10 人)来评价翻译的质量,顺便也让 GPT-4(0125-Preview)来看了看,在 TransAgents、GPT-4(1106-Preview)和真人当中,谁的翻译最好。
测评者会看到针对同一段原文的不同翻译,其中真人只看译文,GPT-4 则是原文译文都看。
结果,真人测评者有超过一半都认为 TransAgents 比人类翻译得更好,8.4% 认为两者质量相当,GPT-4 也认为 TransAgents 比自己(和人类)的翻译质量高。
除了这些大众评审之外,两名专业的翻译也认为,虽然人工翻译更加忠实于原文,但 TransAgents 给出的翻译明显更有文学色彩,更加简洁、在遣词用句上体现出了语言天赋和深厚的文学表现力。

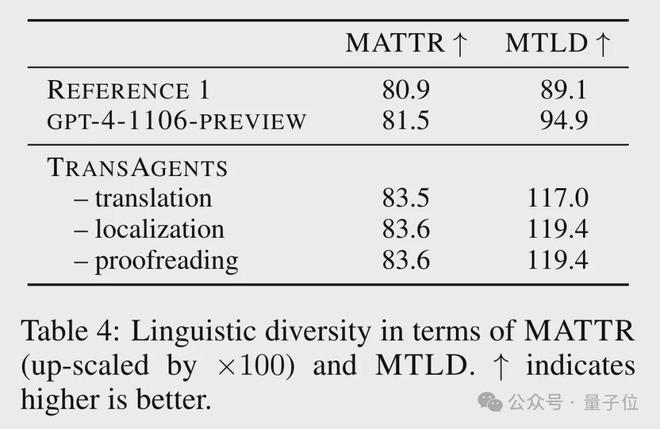
MATTR 和 MTLD 测试指标也证明了这一点,尤其是在 MTLD 上,TransAgents 的语言多样性比真人和 GPT-4 高出了三分之一左右。
在作者展示的案例中,TransAgents 会根据目标语言的习惯对翻译内容做出调整,真人(Ref1)和 GPT-4 虽然翻的也没错,但相比之下不如 TransAgents 符合语言习惯。

另外在前后一致性上,TransAgents 也超过了单纯使用 GPT-4,对相同的原文保持使用一样的译文。

当然,也不是说所有类型它都擅长,在前面提到的 8 种类型中,TransAgents 在游戏、科幻爱情等类型上的表现突出,而在恐怖惊悚等类型上就比较平庸了。
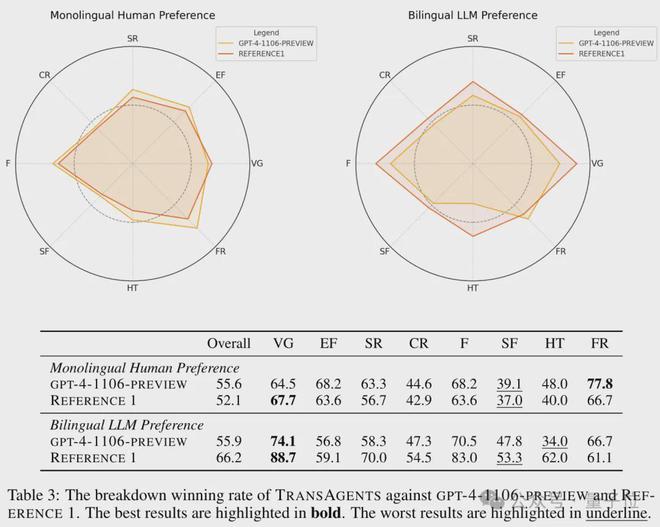
△图中虚线代表 50%Win rate
同时作者也发现,TransAgents 在翻译时并非“照单全收”,而是会出现一定程度的遗漏现象。

不过从测试中未看过原文的读者给出的评分来看,这样的遗漏似乎没有影响到他们的阅读体验。
所以,这家“翻译公司”是如何运行的呢?
多智能体分工协作
在这个公司当中,不同的智能体分别扮演着 CEO、初/高级编辑、真·翻译、本地化专家和校对(Proofreader)这些不同的职位,除 CEO 外每个职位各有 30 人,每个人擅长的领域也有所不同,另外还有一个 Ghost Agent。
这些智能体由 GPT-4-Turbo 驱动,每个角色都包含姓名、年龄、职位、工作年限及掌握的语言等多维度的设定。

接到“客户”的翻译要求后,CEO 会综合分析原文和目标语言、体裁、目标受众等信息,从几位高级编辑中选择擅长领域最匹配的一位。
此时,Ghost Agent 会对 CEO 的选择进行评估,告知其人选是否合适,从而减少选择失当的现象。
被选定的高级编辑会与 CEO 合作,再次结合任务需求和个人特点,从公司人才库中进一步选择初级编辑、翻译、本地化专家和校对等团队成员。

团队组建好后,首先由初级编辑逐章节识别所有潜在的关键术语,生成初始术语表,交由高级编辑审查,删除其中的通用术语,生成修订后的术语表,反复迭代直到不需要进一步修改。
然后,结合术语在不同语境下的意义,高级编辑会将术语表中的关键术语翻译为目标语言。
有了术语表后,初级编辑会为每一章生成详细的章节摘要,尽可能保留关键信息和细节,然后还是让高级编辑来审查,并删除冗余或不必要的信息,让章节摘要更加简明扼要。
接着,高级编辑根据修订后的章节摘要编写全书的摘要,概括主要情节、人物和主题,并随机选择书中的一章,分析其语气、风格和目标受众,制定翻译风格指南。
翻译风格指南会发送给项目团队所有成员,以确保译文风格的一致性。
根据风格指南,公司中的真·译员会逐章节进行初步翻译,把初稿交给初级编辑审查,检查是否遵循翻译风格指南,并提出改进意见。
在此基础之上,高级编辑会评估经过修改的译文质量,决定是否需要进一步修改,译员、初级编辑和高级编辑反复迭代,直到译文质量满足要求。
但此时得到的翻译文本并不是终稿,还要交给本地化专家进行调整。专家会识别可能需要文化调适的内容,如习语、隐喻等等,并对这些内容进行调整,使其在保留原文意图的基础之上更贴近目标语言和文化。
调整后的文本会让初级编辑和高级编辑再次审查,确保译文在文化适应性和忠实度之间取得平衡。
这之后,还有校对人员再次检查语法、拼写、标点和格式错误,如果有修改,还要再让编辑进一步审核。
这些流程都走完后,高级编辑会进行最后的终审,重点关注相邻章节之间的连贯性,确保情节、人物、主题等元素在全书范围内保持一致,一旦发现问题则发回给前面的团队成员进行修改,直到形成最终的译本。
如果客户对译本有修改意见,则会再次由高级编辑牵头,组织相关人员进行修改,直到定稿。
不仅是在工作流程上极其严格规范,在客户对译本满意后,高级编辑还会组织项目团队“开会”进行项目总结,分享经验教训。
过程中积累的有价值的术语、翻译技巧、文化调适策略等知识会被整理归纳,上传至公司的知识库,供后续项目参考。
One More Thing
TransAgents 已经不是第一个由智能体组成的“公司”了,去年就有来自清华的“游戏公司”ChatDev 爆红网络,背后所运用的核心技术就是多智能体。
如果把视线放宽,不只看“公司”,还有斯坦福的 AI 小镇、清华的 AI 狼人杀游戏,都在使用多智能体进行着真实人类社会的模拟。
总之随着大模型研究的深入,智能体和群体智能实验已成 AI 研究最热门方向之一,而且从这次的 TransAgents 来看,多智能体协同已经开始显现出了实际效益。
(顺便提一句,有网友发现,从斯坦福小镇到 ChatDev,再到这次的 TransAgents,多智能体研究的作者是真的喜欢《星露谷物语》式的绘画风格。)
当然,也有人对此表示了担忧,认为由 AI 来主导翻译,会导致语言的同质化,让各种语言中独特的表达消失。
更有甚者,已经跳出 TransAgents 本身,想到 Ilya 对大规模 Agent 合作的恐惧了……
那么你认为在群体智能这条路上还能创造出什么新奇的成果呢?欢迎在评论区晒出你的脑洞。
论文地址:






