
新智元报道
编辑:LRT
通过提示查询生成模块和任务感知适配器,大一统框架 VimTS 在不同任务间实现更好的协同作用,显著提升了模型的泛化能力。该方法在多个跨域基准测试中表现优异,尤其在视频级跨域自适应方面,仅使用图像数据就实现了比现有端到端视频识别方法更高的性能。
文本端到端识别是一项从图像或视频序列中提取文本信息的任务,虽然取得了一些进展,但跨领域文本端到端识别仍然是一个难题,面临着图像到图像和图像到视频泛化等跨域自适应的挑战。

图 1 图(a)和图(b)是两种跨域文本端到端识别,包括图像到图像和图像到视频。TT 表示 TotalText,IC15 代表 ICDAR2015,IC13 代表视频 ICDAR2013。
图像级跨域文本端到端识别面临样式、字体、背景等差异挑战,模型需要具备极强的泛化能力。
不同数据集间的格式差异也是跨域文本端到端识别重要的问题,如 Total-Text 和 ICDAR2015 使用词级注释,CTW1500 使用行级注释。视频级跨域文本端到端识别中,由于视频文本中存在着如遮挡、场景变化和文本快速运动等因素,现有静态图像的方法在视频环境通常表现不佳,如图 2 所示。

图 2 将静态文本识别方法应用于视频,即使是那些运动最小的视频,也会导致边界框召回和识别准确性方面的性能不足。T_n表示视频的第n_th 帧。
另外,视频文本端到端识别中非常缺乏数据。一些研究者尝试使用光流估计进行数据合成,但这种方法存在扭曲、标签错误和偏见等挑战,且无开源合成数据供公众使用。
针对上述问题,华中科技大学、华南理工大学及浙江大学的研究人员提出了一种新的方法 VimTS,通过实现不同任务之间更好的协同来增强模型的泛化能力,包括一个提示查询生成模块和一个任务感知适配器,仅使用较少参数便可有效地将原始的单任务模型转换为适合图像和视频场景的多任务模型。

论文链接:https://arxiv.org/pdf/2404.19652
代码地址:https://vimtextspotter.github.io
提示查询生成模块促进不同任务之间的显式交互,而任务感知适配器帮助模型动态地学习适合每个任务的特性。
此外,为了进一步使模型能够以更低的成本学习时间信息,研究人员提出了一个利用内容变形场(CoDeF)算法的合成视频文本数据集(VTD-368k)。
实验结果显示,该方法在六个跨域基准测试(如 TT-to-IC15、CTW1500-to-TT 和 TT-to-CTW1500) 中比最先进的方法平均高出 2.6%
对于视频级跨域自适应,该方法甚至超过了 ICDAR2015 视频和 DSText v2 中之前的端到端视频识别方法,在 MOTA 指标上平均高出 5.5 %,仅使用图像级数据。
通过进一步实验证明,与文中提出的 VimTS 模型相比,现有的大型多模态模型在生成跨域场景文本识别方面存在局限性,Vim 模型需要的参数和数据要少得多。
方法原理简述
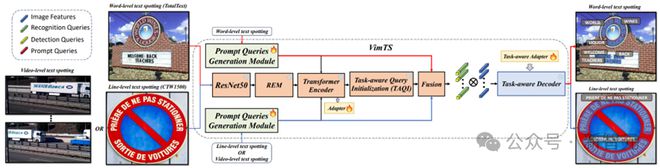
图 3 网络整体框架图
总体结构
VimTS 是一个旨在利用各种任务之间的协同作用的统一框架,以提高文本端到端识别的泛化能力,其整体架构如图 3 所示,使用一组任务感知查询表示各种任务。
首先,通过特征提取过程获得图像特征。
然后,使用 Query Initialization 模块生成任务感知查询,包括检测和识别查询。
随后,这些查询被馈送到任务感知解码器中,以显式捕获判别和交互特性,同时进行文本检测、识别和跟踪。
接着,使用提示查询生成模块(PQGM)和任务感知适配器实现分层任务之间的交互,包括单词级和行级文本端到端识别,以及视频级文本端到端识别。
在训练阶段,大多数参数被冻结。然后,任务感知适配器和 PQGM 学习多任务特性。首先,将要执行的任务提示输入到 PQGM 中。
然后,PQGM 生成提示查询,并将其发送给 Transformer 编码器和任务感知解码器,以指导模型完成相应的任务。
我们的方法不仅适用于图像级的跨域,还可以学习视频级的跨域自适应。
提示查询生成模块
为了提高模型处理多任务的能力,我们引入了提示查询生成模块(PQGM),用于生成指导模型运行的提示查询。该模块的结构如图 4 所示。
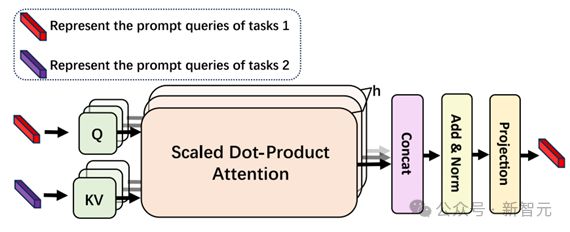
图 4 提示查询生成模块
我们使用可学习的嵌入作为每个任务的提示查询,其维度与 Transformer 隐藏特征的维度相匹配。在将这些提示查询输入模型之前,我们使用注意机制促进不同任务之间的信息交换。随后,我们将提示查询输入模型,以指导其学习特定于任务的特征。使用 PQGM,VimTS 可以同时处理多个任务,并促进它们之间的显式交互,从而促进不同任务之间的协同作用。
在交互之后,我们将提示查询传输到 Transformer 编码器,使其能够学习任务特定的特性。然后,利用这些特性来协助查询初始化,并指导解码器输出相应任务的结果。
为了进一步增强对任务特定特性的学习,我们将提示查询与任务感知查询集成在一起。我们通过向任务感知查询添加提示查询来实现这种融合,从而引导模型更有效地完成相应的任务。
任务感知适配器
受 Adapter 的启发,我们提出了一个任务感知适配器来动态地为不同的任务选择合适的特性。带有 PQGM 的任务感知适配器有效地将原始的单任务模型转换为适合图像和视频场景的多任务模型,所需的额外参数最少。
任务感知适配器采用级联适配器结构,其中一个适配器编码检测信息,另一个适配器编码识别信息。
为了实现这一点,我们首先冻结预训练文本观测者的大多数参数。接下来,我们将适配器集成到神经网络中,例如一个 Transformer 层。
在多任务训练过程中,适配器学习不同任务的特征。值得注意的是,任务感知适配器不仅可以应用于图像级场景,还可以学习时间信息,从而帮助预训练模型过渡到涉及视频文本端到端识别的任务。
总体结构如图 5 所示。
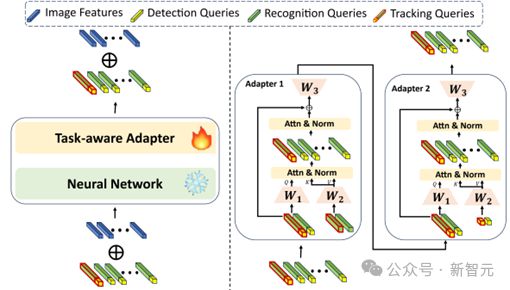
图 5 任务感知适配器结构图
最初,我们使用两个线性层将组查询的维数降为原本的四分之一,从而降低了后续模块的参数。然后,任务感知查询通过注意机制聚合检测信息。
在对检测特征进行聚合后,对图像级文本端到端识别采用注意机制学习不同文本实例之间的关系,对视频级文本端到端识别采用注意机制对时间信息进行建模。
第二个适配器遵循类似的过程,但侧重于聚合识别信息。使用任务感知适配器,可以有效地学习交互和判别特征,所需的额外参数最少。
跟踪查询
受 MOTR 启发,我们采用跟踪查询使模型支持文本跟踪,从而使 VimTS 能够动态适应图像和视频等不同输入。
由于同一文本实例在前后帧之间表现出很强的相关性,我们利用前一帧的检测和识别查询作为跟踪查询,对当前帧中的文本实例进行定位、识别和跟踪。对于新生文本实例,我们继续使用检测和识别查询来定位和识别。
不同的查询在单个解码器中显式地建模不同任务的判别和交互特征,并同时输出检测、识别和跟踪结果。
相比之前的视频文本端到端识别方法,我们的方法通过统一框架和组合查询,在跟踪过程中更有效地利用不同帧的识别信息。这样,我们可以利用前一帧的识别信息来帮助后一帧中的文本实例识别,实现之前方法无法做到的效果。
视频数据合成方法
视频文本识别数据是非常昂贵的。BOVText 报告说,注释2,021 个视频需要 30 名工作人员在三个月的时间内全力以赴。
此外,数据集版权也仅限于视频文本端到端识别数据的大规模构建。因此,采用低成本的合成数据是缓解视频文本识别模型数据需求的有效方法。数据合成的一个解决方案是使用光流估计,但它带来了几个挑战,包括失真、标记错误和对静态对象的偏见。
为了应对这些挑战,我们引入了一种新的方法,该方法利用 CoDeF 来促进实现真实和稳定的文本流传播,以构建合成视频文本数据集。
我们从 NExT-QA, Charades-Ego, Breakfast, A2D, MPI-Cooking, ActorShif 和 Hollywood 手动收集和过滤无文本,开源和无限制的视频。
然后,我们将它们按优先顺序排列,这是由过渡的稳定性,高分辨率和视频中广泛的平面区域的流行所决定的。每个数据集的统计信息显示在表1。
为了实现分布式处理和减少 GPU 内存,我们将视频分成包含 368K 帧的片段进行数据合成。合成数据称为 VTD-368K。

表 1 VTD-368k 的源视频数据集统计。时长表示视频的平均时长。Remaining 表示所选帧的比例
在介绍合成方法以前,我们先简单介绍一下 CoDef。CoDeF 是使用扁平规范图像C和变形场D表示由帧组成的视频V的有效方法。总体过程可以秒速为:
式中, 为隐式模型的拟合过程。通过使用 ControlNet、SAM 或R-ESRGAN 等特定的工具,将规范图像C转换为C',并将此转换与变形场同时集成,可以实现视频风格转换、视频对象跟踪和视频超分辨率。视频V’的重构过程可表述为
式中,C为隐式模型的重构过程,V′为重构后的视频。
我们提出了一种新的合成方法。具体如图 6 所示,我们首先使用 SAM-Track 和 RAFT 分别获得所有帧的光流图和分割图。然后,CoDeF 用于有效地重建视频中的刚性和非刚性对象,同时精心恢复运动细节的微妙复杂性。
经 CoDeF 处理后,输入视频被表示为规范图像C和变形场D
其中,C作为通过 Synthtext 放置文本的基础,而D封装了从观察到每个帧的规范化表示的转换。随后,可以生成嵌入文本地图 Tc,如下所示:

式中,Sc 和 Dc 分别为规范图像的分割图和深度图。然后,将 Tc 作为公式五的输入,与D结合,重构视频文本映射 Tt,使用下式:
训练的隐式可变形模型生成文本几何形状,但不保留其共线性和笔画顺序。为了解决这一问题,在隐式可变形模型重建后引入了投影变换。具体来说,我们收集一组点对(pc, pt)
其中 pc 是规范图像中形成文本几何图形的点,pt 是它们在重构帧中的对应点。然后,我们用 RANSAC 估计投影矩阵H_{c, t}以鲁棒拟合这些点对。
最后,我们应用该投影矩阵来转换文本映射中的每个文本几何形状。
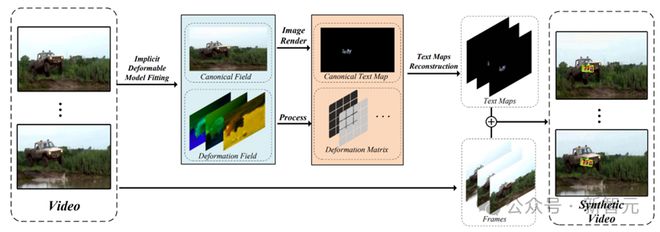
图 6 基于 CoDef 的合成方法总体框架。

图 7 合成数据的样例。
主要实验结果及可视化结果
图片级别跨域端到端识别的实验结果
为了更好的评估我们方法的有效性,我们对 TotalText 和 CTW1500 进行了新的标注。对 TotalText 的测试集重标注行级别文本的标注。对 CTW1500 的测试集重标注单词级别文本的标注。
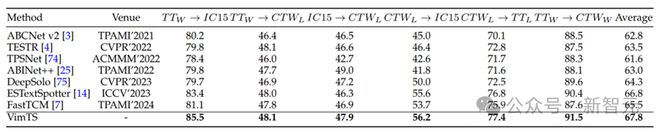
表 2 跨域文本检测的性能。 表示单词级别的 TotalText。 表示行级 TotalText。 表示字级 CTW1500。 表示行级 CTW1500。加粗表示 SOTA。
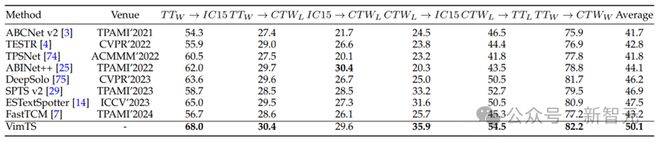
表 3 跨域文本端到端识别的性能。
消融实验

表 4 消融实验结果
在场景文本识别方法上进行了实景自适应测试。表中接结果是端到端识别在“None”字典下的结果。Full-Tuning 表示对模型的所有参数进行调优。PQGM 表示提示查询生成模块。
视频级别跨域端到端识别的实验结果
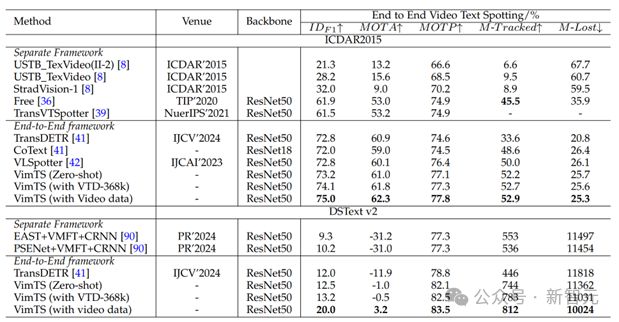
表 5 视频文本识别结果,' M-Tracked '和' M-Lost '分别表示' most Tracked '和' most Lost '。

表 6 在 ICDAR2013 上的视频文本检测结果。
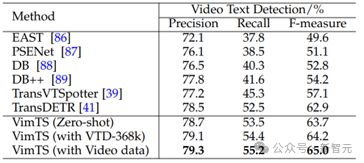
表 7 在 DSText v2 上的视频文本检测结果。
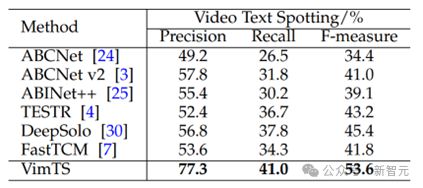
表 8 在 ICDAR2013 上零样本视频端到端识别的结果。所有方法都使用相同的图片级别的训练集,并对视频的每一帧评估端到端识别的结果。
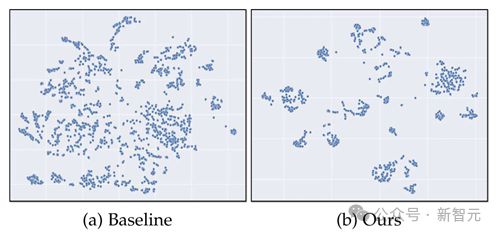
图 8 通过t-SNE 在不同帧中文本实例的分布。
可以看出,在本文提出的方法中,同一文本在不同帧间的特征相似度更高。因此,在我们的方法中,使用前一帧的特征作为当前帧的输入查询,即使只使用图像级训练数据,也可以有效地定位、识别和跟踪相同的文本实例。
可视化

图 9 与其他方法在文字视频上的对比
近年来,大型多模态模型因其强大的泛化能力而备受关注。为了进一步证明我们的方法的有效性,我们在 ICDAR2015 上进行了跨域实验,与大型多模态模型进行了比较。评估过程参考 GPT-4V_OCR[2]。
结果显示在表 9 中。研究结果表明,为特定任务开发场景文本识别方法的重要性。与大型多模态模型的广泛应用相比,这种专门的方法不仅在需要更少的参数方面更有效,而且需要更少的训练数据。
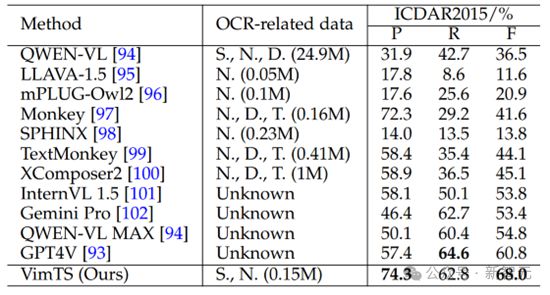
表 9 ICDAR2015 上的跨域文本识别与 mlms 的比较。所有结果都在“None”词典上进行测试。OCR 相关数据表示与 OCR 相关的训练数据。S.、N.、D.和T.分别代表合成、自然、文档和表格数据。
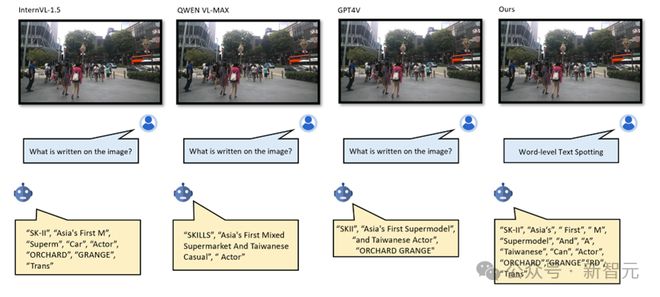
图 10 与多模态大模型的可视化分析
总结
在本文中,我们介绍了 VimTS,它通过发挥不同粒度文本识别任务(包括词级,行级和视频级文本识别)之间的协同作用来提高跨域文本识别性能。VimTS 通过联合优化不同场景下的不同任务来增强模型的泛化能力。
在广泛的跨领域基准测试上进行的广泛实验一致表明,我们的方法比以前的最先进的方法性能要好得多。值得一提的是,我们的方法证明了静态文本图像可以很好地转化为视频文本图像是可行的。
由于与视频图像相比,静态图像需要的注释工作要少得多,因此探索弥合领域差距的方法将是非常有价值的。
此外,我们证明了当前的大型多模态模型在跨域文本识别方面仍然存在局限性,利用更少的参数和更少的数据来提高大型多模态模型在文本识别中的泛化,值得进一步探索。
参考资料:
[1] Ouyang H, Wang Q, Xiao Y, et al. Codef: Content deformation fields for temporally consistent video processing[c]. CVPR, 2024
[2] Shi Y, Peng D, Liao W, et al. Exploring ocr capabilities of gpt-4v (ision): A quantitative and in-depth evaluation[J]. arXiv preprint arXiv:2310.16809, 2023.
原文作者: Yuliang Liu, Mingxin Huang, Hao Yan, Linger Deng, Weijia Wu, Hao Lu, Chunhua Shen, Lianwen Jin, Xiang Bai






