
新智元报道
编辑:alan
近日,西交微软北大联合提出信息密集型训练大法,使用纯数据驱动的方式,矫正 LLM 训练过程产生的偏见,在一定程度上治疗了大语言模型丢失中间信息的问题。
辛辛苦苦给大语言模型输入了一大堆提示,它却只记住了开头和结尾?
这个现象叫做 LLM 的中间迷失(Lost in the Middle),是大模型当前仍面临的最大挑战之一。
毕竟,LLM 现在的上下文长度已经冲到了百万级别,而难以处理中间的信息,会使得 LLM 在评估大量数据时不再可靠。

Midjourney 对于 Lost in the Middle 的理解
其实,我们人类也有类似「中间迷失」的毛病,心理学上叫「Primacy/recency effect」,感兴趣的读者可以参见:
https://www.sciencedirect.com/topics/psychology/recency-effect
「我怕零点的钟声太响......后面忘了」
不过就在不久前,来自西交、微软和北大的研究人员,开发了一种纯粹的数据驱动解决方案,来治疗 LLM 丢失中间信息的症状:

论文地址:https://arxiv.org/pdf/2404.16811
研究人员认为,Lost in the Middle 的原因是训练数据中的无意偏差。
因为 LLM 的预训练侧重于根据最近的一些 token 预测下一个 token,而在微调过程中,真正的指令又往往位于上下文开始的位置。
这在不知不觉中引入了一种立场偏见,让 LLM 认为重要信息总是位于上下文的开头和结尾。
基于这样的见解,研究人员提出了信息密集型(INformation-INtensive,IN2)训练方法,来建立数据之间的桥梁。

既然是训练过程造成的偏见,那么就用训练数据来解决。
IN2 训练使用合成问答数据,向模型显式指出重要信息可以位于上下文中的任何位置。
整个上下文长度(4K-32K 个 token),被分为许多 128 个 token 的片段,而答案所对应的信息位于随机位置的片段中。
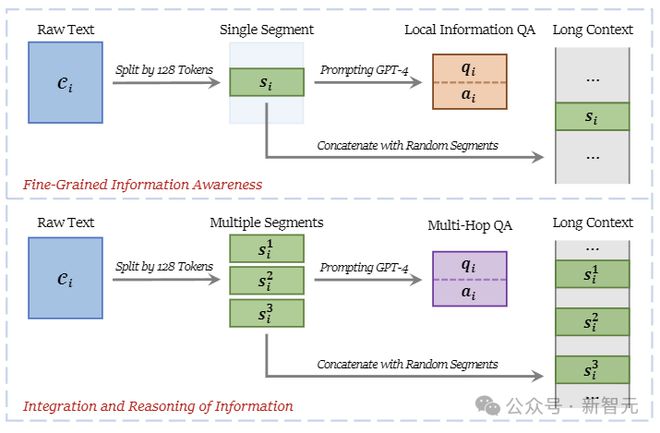
研究人员使用了两种类型的训练问题:一种是要求在一个片段中提供细节,另一种是需要整合和推断来自多个片段的信息。
IN2 训练到底效果如何?使用明星模型 Mistral-7B 来试试。
将 IN2 训练应用于 Mistral-7B,得到了新模型 FILM-7B(FILl-in-the-Middle),然后测试为长上下文设计的三个新的提取任务。
测试任务涵盖不同的上下文类型(文档、代码、结构化数据)和搜索模式(向前、向后、双向)。
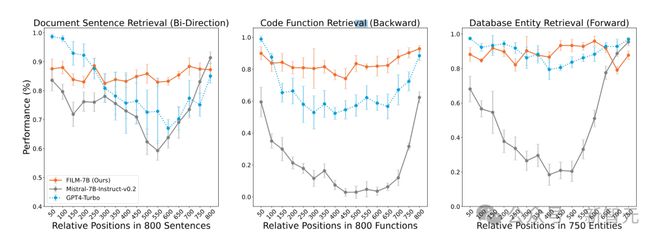
结果表明,IN2 显著降低了原始 Mistral 模型的「中间丢失」问题。更厉害的是,作为只有 7B 的模型,FILM 的性能在很多情况下甚至超越了 GPT-4 Turbo。
在保持自己执行短上下文任务能力的同时,FILM-7B 在各种长上下文任务中也表现出色,例如总结长文本,回答有关长文档的问题,以及对多个文档的推理。
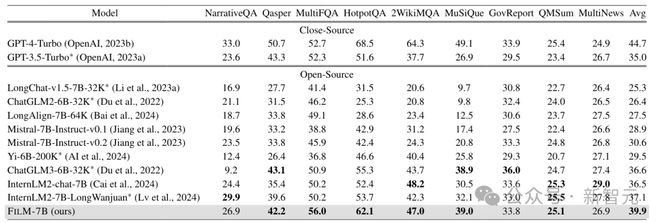
上表是不同模型在现实的长上下文任务中的表现。与本体 Mistral-7B 相比,INformation-INtensive (IN2) 训练带来的提升很明显,FILM-7B 的综合成绩仅次于 GPT-4 Turbo。
不过有一说一,Lost in the Middle 的问题并没有完全解决,而且在长上下文存在问题的情况下,GPT-4 Turbo 也仍然是上下文基准中最强的模型。
Lost in the Middle
LLM 丢失中间信息的问题最早由斯坦福、UC 伯克利和 Samaya AI 的研究人员在去年发现。

论文地址:https://arxiv.org/pdf/2307.03172
当面对较长的信息流时,人类倾向于记住开头和结尾,中间的内容更容易被忽视。
没想到 LLM 也学会了这个套路:对于从输入中检索信息的任务,当信息位于输入的开头或结尾时,模型的表现最好。
但是,当相关信息位于输入的中间时,性能会显著下降。尤其是在回答需要从多个文档中提取信息的问题时,性能下降尤为明显。
——真是干啥啥不行,偷懒第一名。
模型必须同时处理的输入越多,其性能往往越差。——而在实际得应用场景中,往往就是需要 LLM 同时均匀地处理大量信息。
另外,研究结果还表明,大型语言模型使用额外信息的效率是有限的,具有特别详细指令的「大型提示」可能弊大于利。
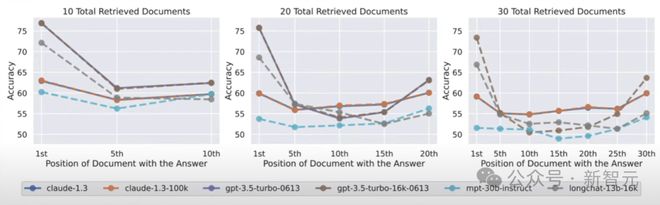
对于许多长上下文 LLM,中间信息丢失的现象普遍存在。上表测试了当时市面上流行的各种款式 LLM,包括 GPT-4,一共是七种。
可以看出,不论是开源还是闭源模型的强者,测试结果都显示出明显的U形曲线,说明都是在两头效果好,而中间就拉跨了。
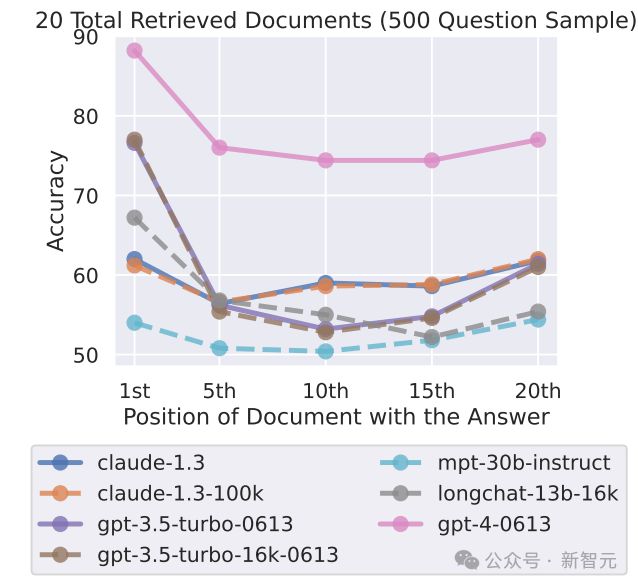
即使强如 GPT-4,也难逃被「掰弯」的命运。
这也不禁让人质疑:你们这些卷超长上下文的模型到底有没有用啊?不但吃得多,中间信息也记不住。
信息密集型训练大法
为了明确教导模型,在长上下文中的任何位置都可以包含关键信息。研究人员构建了一个长上下文问答训练数据集 D = {L,q,a},其中问题q的答案a,来自长上下文L中的随机位置。
下图展示了整个数据构建过程。具体来说,训练数据D基于通用自然语言语料库C。给定一个原始文本,首先使用 LLM(GPT-4-Turbo)生成一个问答对 (q,a),然后合成一个长上下文 L,其中包括来自C的其他随机抽样文本的必要信息。
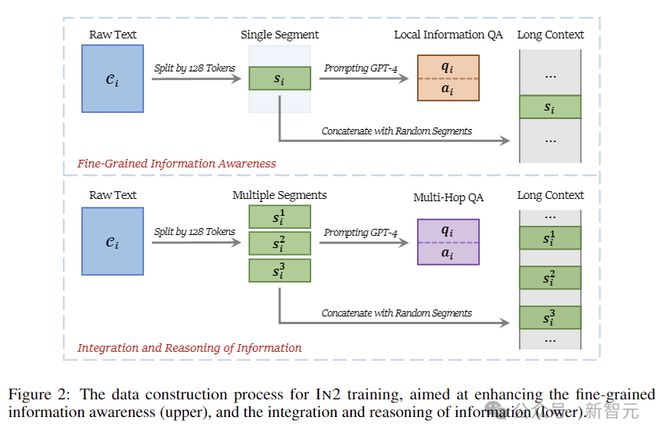
上图包含两种类型的问答对:(1)对长上下文中细粒度信息的掌握;(2)对长上下文中不同位置出现的信息进行整合和推理。
细粒度信息感知
将包含 128 个 token 的段视为上下文的最小信息单元。给定一个原始文本C,首先从中随机提取一个 128 个 token 的段s,然后生成q、a和 L:
信息整合和推理
除了利用每个片段之外,研究人员还考虑为两个或多个片段中包含的信息生成问答对。
按照上面最小信息单元的设置,同样将全文拆分为一组 128 个 token 的段 [s],然后相应地生成 q、a和L:
使用 LLM 生成多跳问答对,保证每个问题对应的答案至少需要两个段内的信息。
训练
整个训练数据集包含:1.1M 用于细粒度信息感知的长上下文数据(∼63%)、300K 用于信息整合和推理的长上下文数据(∼17%)、150K 短上下文问答数据(∼9%)和 200K 通用指令调整数据(∼11%)。
使用上面构建的训练数据,研究人员对 Mistral-7B-Instruct-v0.2 执行 IN2 训练:将长上下文和问题作为指令,并使用答案部分的损失来更新模型。
超参数:将全局批处理大小设置为 128,使用余弦学习率衰减,最大值为 1e-6。
模型训练在 16 个 80G A100 GPU 上进行,采用由 pytorch FSDP 实现的完整分片策略和 cpu 卸载策略,整个训练过程耗时大约 18 天。
VAL 探测
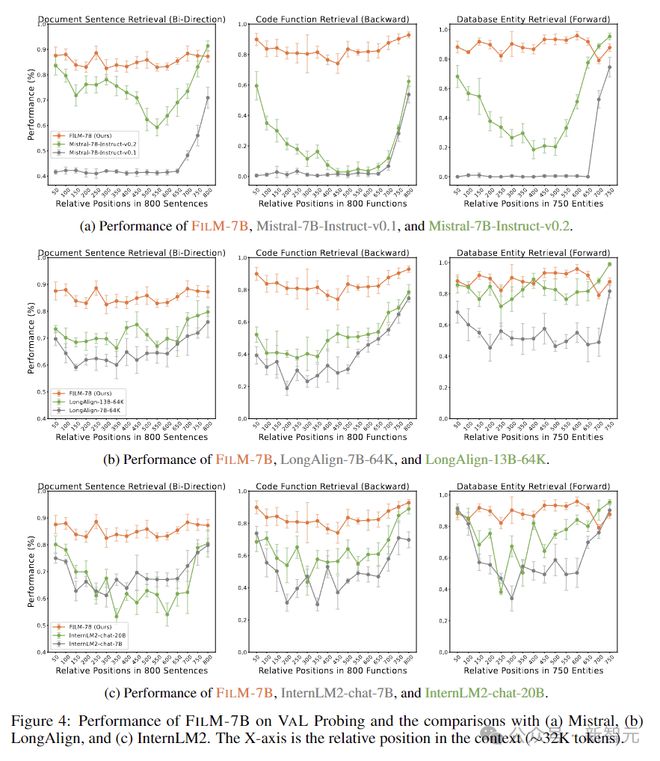
研究人员提出了 VAL 探测方法,作为评估语言模型上下文性能的更合适的方法,涵盖了不同的上下文风格和检索模式,以进行更彻底的评估。
下图表示 VAL 探测中的三个任务。检索模式由检索关键字与要检索的信息之间的相对位置决定。

这里考虑了三种上下文样式(文档、代码和结构化数据上下文)和三种检索模式(前向、后向和双向检索)。
VAL 探测中的每个上下文都包含约 32K 个 token,每个任务包含约 3K 个示例。
文档句子检索(双向):上下文由许多自然语言句子组成,目的是检索包含给定片段的单个句子。这些句子是从 arXiv 上的论文摘要中抽取的。
此任务遵循双向检索模式,因为预期的检索结果包含上下文中给定片段之前和之后的单词。评估指标是单词级别的召回率分数。
代码函数检索(向后):上下文由 Python 函数组成,目的是检索函数定义中给定代码行的函数名称。原始代码函数是从 StarCoder 数据集中采样的,并为每个函数随机选择三行定义。
此任务遵循向后检索模式,因为函数名称始终位于定义之前。评估指标是匹配精度。
数据库实体检索(向前):上下文包含结构化实体列表,每个实体都有三个字段:ID、label 和 description,目的是检索给定 ID 的标签和说明。这些实体是从维基百科数据中采样的。
此任务遵循正向检索模式,因为标签和说明跟随 ID。以宽松的匹配准确性作为衡量标准:如果响应中的标签或描述完全匹配,则给出 1 分,否则为 0 分。
参考资料:






