
最近在许多美国开发者的口中,一个开源模型经常被提及,它的发音听起来是“困”。乍一听到总让人一头雾水。哪个开发者天天用中文说困啊。
其实,这就是阿里的开源模型通义千问,这个取自拼音缩写的名字 Qwen,被老外自成一体给了一个新发音。
除了 Qwen,还有好几个国产开源大模型在海外激战正酣,并且频繁刷新各项 benchmarks,呼声和反响甚至比在国内还高。这些来自中国团队的开源模型们不仅不“困”还进展飞速。
Stability AI 研究主管 Tanishq Mathew Abraham 干脆发文提醒道:“许多最具竞争力的开源大模型,包括 Owen、Yi、InternLM、Deepseek、BGE、CogVLM 等正是来自中国。关于中国在人工智能领域落后的说法完全不属实。相反,他们正在为生态系统和社区做出重大贡献。”

那到底现如今,中国的开源大模型们厉害到什么程度?下面逐一来看。
通义千问:登顶主流开源榜,八种尺寸个个能打
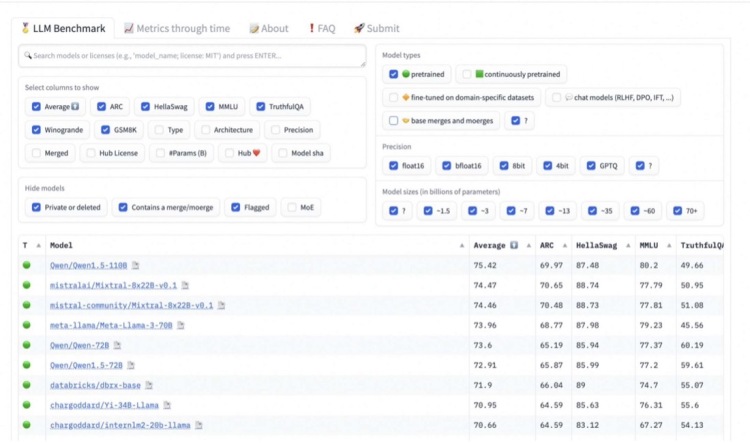
5 月 9 日,阿里云正式发布地表最强中文开源大模型通义千问 2.5。相较上一版本,2.5 版模型的理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%,中文语境下性能“全面赶超 GPT-4”。
上月底,团队刚开源了 Qwen1.5 系列首个千亿参数级别模型 Qwen1.5-110B,能处理 32K tokens 上下文长度,支持英、中、法、西、德等多种语言。技术上采用 Transformer 架构,并具有高效的分组查询注意力机制。基础能力可逼近 Meta-Llama3-70B 和 Mixtral-8x22B,在 MT-Bench 和 AlpacaEval 2.0 的聊天场景评估中也表现出色。

Liquid AI 高级机器学习科学家 Maxime Labonne 看了表示:“太疯狂了。Qwen1.5-110B 在 MMLU 上的得分竟然高于‘性能野兽’ Llama 3 70B 的 instruct 版本。 微调后它将有可能成为最强开源 SOTA 模型,至少能和 Llama 3 媲美。”

Qwen1.5-110B 还曾凭实力登顶 Hugging Face 开源大模型榜首。
实际上,自从通义千问去年 8 月宣布“全模态、全尺寸”开源路线以来,就开始马不停蹄地迭代狂飙,强势闯入海外 AI 开发者社区的视野。
为满足不同场景需求,通义一共推出横跨 5 亿到 1100 亿参数规模的八款大模型,小尺寸如 0.5B、1.8B、4B、7B、14B 可以在端侧设备便捷部署;大尺寸如 72B、110B 能支持企业和科研级应用;而 32B 的中等尺寸则力求在性能、效率和内存之间找到最佳性价比。
在各种尺寸的灵活选择下,通义千问其它参数的模型性能也好评如潮。
其中 Qwen-1.5 72B 曾在业界兵家必争之地:LMSYS Org 推出的基准测试平台 Chatbot Arena 上夺冠,Qwen-72B 也多次进入“盲测”对战排行榜全球前十。
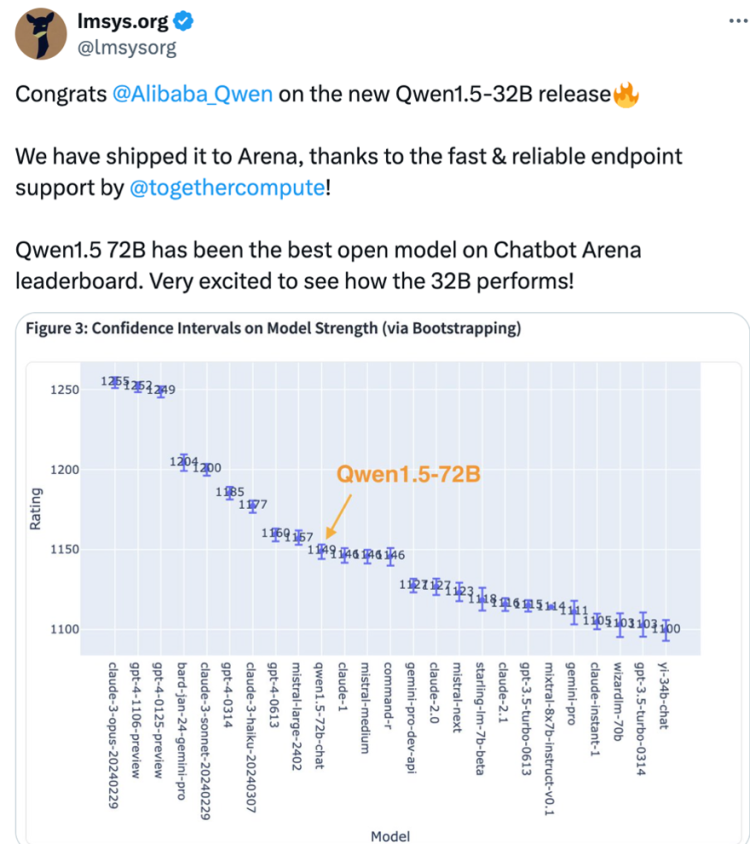
推特大 V 、Abacus.AI 公司创始人和首席执行官 Bindu Reddy 直接挂出 Qwen-72B 的基准测试成绩兴奋地说:“开源的 Qwen-72B 在一些 benchmarks 上击败了 GPT-4!中国正在回击困扰美国的 AI 公司垄断!加入全球开源革命吧!”
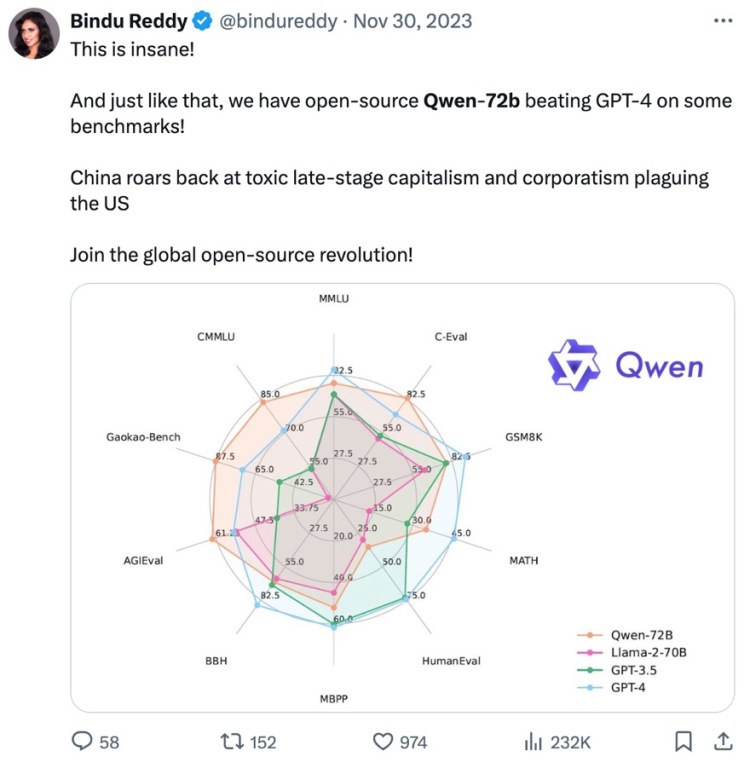
另有网友指出 Qwen-72B 基础模型在 VMLU ,也就是越南语版本的 MMLU 上无需微调、开箱即用,即可达到与 GPT-4 相同分数的最先进水平。

较小参数的 Qwen 家族成员更是备受欢迎。
在 Hugging Face 平台上,Qwen1.5-0.5B-Chat 和 CodeQwen1.5-7B-Chat- GGUF 上月分别获得 22.6 万次和 20 万次下载量。包括 Qwen1.5-1.8B 和 Qwen1.5-32B 在内的 5 个模型上月下载量都在 10 万次以上。(总共发布 76 个模型版本,也真的堪称行业劳模。)
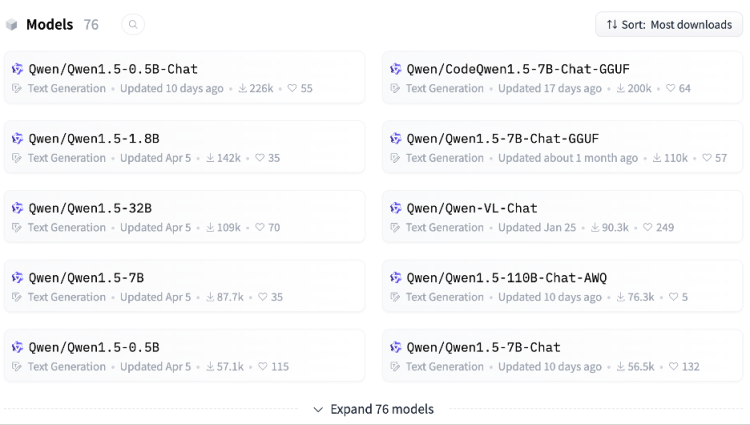
我们还注意到,在今天很多的对模型性能进行分析的论文中,Qwen 也几乎成为必选的分析标的,成为开发者和研究者默认的最有代表性的模型之一。
DeepSeek V2:大模型届的“拼多多”
5 月 6 日,私募巨头幻方量化旗下的 AI 公司深度求索发布全新第二代 MoE 大模型 DeepSeek-V2,模型论文双开源。
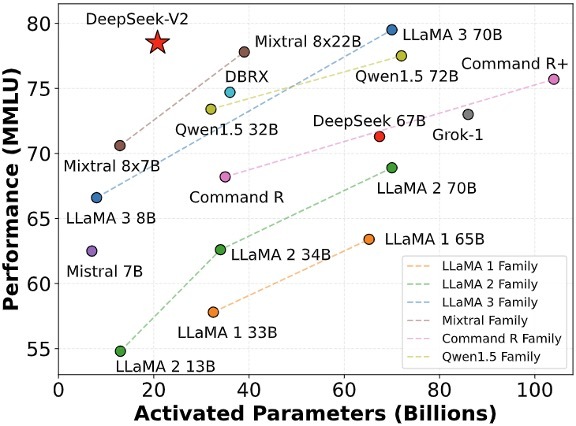
其性能在 AlignBench 排行榜中位列前三,超过 GPT-4 且接近 GPT-4-Turbo。MT-Bench 中属于顶尖级别,与 LLaMA3-70B 比肩,远胜 Mixtral 8x22B。支持 128K 的上下文窗口,专精于数学、代码和推理任务。
除了采用 MoE 架构,DeepSeek V2 还创新了 Multi-Head Latent Attention 机制。在总共 236B 参数中,仅激活 21B 用于计算。计算资源消耗仅为 Llama 3 70B 的五分之一,GPT-4 的二十之一。
除了高效推理,最炸裂的是,它实在太物美价廉了。
DeepSeek V2 在能力直逼第一梯队闭源模型的前提下, API 定价降到每百万 tokens 输入 1 元、输出 2 元(32K 上下文),仅为 Llama3 70B 七分之一,GPT-4 Turbo 的近百分之一,完全就是价格屠夫。
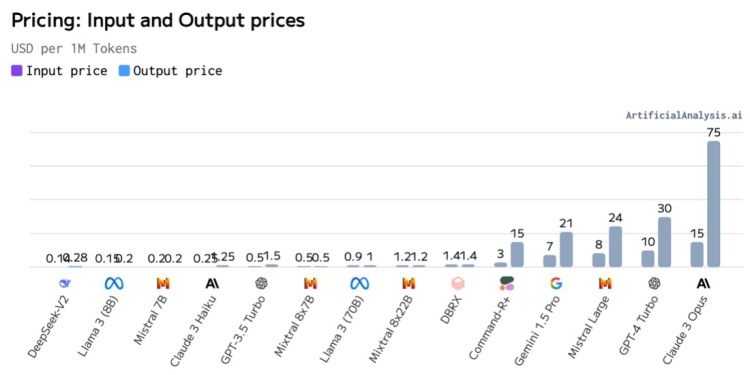
便宜归便宜,DeepSeek 却并不赔钱。 它在 8 x H800 GPU 的机器上可以实现每秒 5 万 tokens 峰值吞吐。按输出 API 价格计算,相当于每个节点每小时收入 50.4 美元。国内 8xH800 节点的成本约 15 美元/小时,因此假设利用率完美,DeepSeek 每台服务器每小时的利润高达 35.4 美元,毛利率可达 70% 以上。
另外 DeepSeek 平台还提供与 OpenAI 兼容的 API,注册就送 500 万 tokens。
——高效、好用、击穿地板的价位,不正是开源社区迫切需要的吗?
这直接引起权威半导体研究和咨询公司 SemiAnalysis 高度关注,5 月 7 日发长文点名 DeepSeek V2 是“东方崛起的神秘力量”,凭超高性价比对其它模型实现“经济学碾压”,指出“OpenAI 和微软的行业挑战可能不只来自美国。”

Hugging Face 技术主管 Philipp Schmid 在X发文,列出 DeepSeek V2 各项技能点向社区隆重推荐。上线仅四天,Hugging Face 上的下载量已达 3522 次,在 GitHub 也瞬间收获 1200 颗星星。

面壁智能:另辟蹊径、以小博大
在通往 AGI 的路上,有的像 DeepSeek 这样面对算力为王,主攻经济高效;也有像通义千问那样全面开花,布局各种模型规模;但绝大多数公司的路线是遵循 Scaling Law,狂卷大参数。
而面壁智能却在走一条相反的路线:尽可能把参数做小。以更低的部署门槛、更低的使用成本让模型效率最大化,“以小博大”。
今年 2 月 1 日,面壁智能推出只有 24 亿参数量的 MiniCPM-2B 模型,不仅整体领先于同级别 Google Gemma 2B,还超越了性能标杆之作 Mistral-7B,且部分胜过大参数的 Llama2-13B、Llama2-70B-Chat 等。
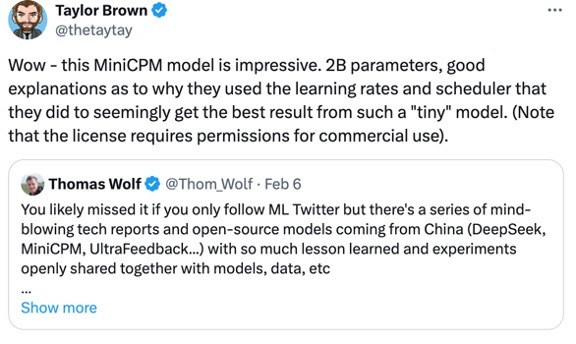
在海外社区开源后,Hugging Face 联合创始人 Thomas Wolf 紧接着发文说,“中国出现了一系列令人惊叹的技术报告和开源模型,比如 DeepSeek、MiniCPM、UltraFeedback...它们的数据和实验结果都被公开分享,这种对知识的坦诚分享在最近的西方科技模型发布中已经丢失了。”
网友转发赞同:“MiniCPM 实在令人印象深刻,拥有 20 亿参数,并从这么微小的模型中获得了最佳结果。”
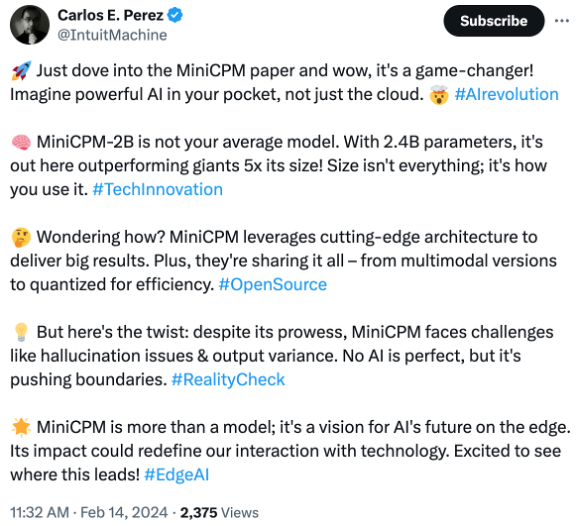
另一位同读过 MiniCPM 模型论文的网友更是激动盛赞,“面壁智能正掀起一场改变游戏规则的革命。”
“想象一下,在你口袋里拥有强大的人工智能,而不仅仅是云端。MiniCPM-2B 不是普通的模型。它只拥有 24 亿参数,却超越了自己 5 倍大的巨人!尺寸并不是唯一标准,关键在于如何利用它。这就是边缘人工智能未来的愿景,可能重新定义我们与技术的互动。”
70 天后,面壁智能乘胜追击,继续发布了新一代“能跑在手机上的最强端侧多模态大模型”MiniCPM-V 2.0,参数规模 2.8B。
据其在 Hugging Face 上介绍,MiniCPM-V 2.0 在包括 OCRBench、TextVQA、MME 在内的多个基准测试中都达到了开源社区最佳水平。在覆盖 11 个流行基准测试的 OpenCompass 综合评估上,它的性能超过 Qwen-VL-Chat 9.6B、CogVLM-Chat 17.4B 和 Yi-VL 34B。甚至在场景文字理解方面已接近 Gemini Pro 的性能。
“与 Mistral 们相比,中国的许多模型是真的在开源”
除了以上提到的 DeepSeek、Qwen 和 MiniCPM,上海人工智能实验室和商汤联合研发的 InternLM、零一万物的 Yi 系列、智谱 AI 的多模态大模型 CogVLM 等等中国的开源模型也在开发者社区里备受欢迎。
人们在推特还特别讨论到,由于中英文间的语言障碍,海外通常能看到中国大模型也只是发布的一部分,太多 AI 应用和集成没有被完全展现。推测这些模型在中文上表现应该比英文更好。但即便如此,它们在英文基准测试上已具备相当的有竞争力。
还有人提出,自己属实被过去一年中 Arxiv 上 AI 论文里中文署名作者的庞大数量震惊到了。

前斯坦福兼职讲师、Claypot AI 联合创始人 Chip Huyen 在调研过 900 个流行开源 AI 工具后,在个人博客中分享自己的发现:“在 GitHub 排名前 20 的账户中,有 6 个源自中国。

开源的一个好处就是让阴谋论无法继续。
OpenAI 早期投资人 Vinod Khosla 曾在X发文称,美国的开源模型都会被中国抄去。
但这番言论马上被 Meta 的 AI 教父 Yann LeCun 反驳:“AI 不是武器。无论我们是否把技术开源,中国都不会落后。他们会掌控自己的人工智能,开发自己的本土技术堆栈。”

而且,在开源的诚意上,中国模型也开始被开发者认可。有在斯坦福读书的同学也分享到,教授在课堂上大力称赞中国开源模型,特别是开诚布公地与社区积极分享成果,跟欧美一些头顶“开源”名号的明星公司不同。有网友也表达了和这个教授相似的观点,“美国最该尴尬的,是今天中国开源模型们重大的贡献”。

大模型技术的发展中开源注定将继续扮演重要的推动角色,而且这也是首次有开源和闭源技术几乎齐头并进的景象出现。在这股浪潮里,中国的开源贡献者正在通过一个个更有诚意的开源产品给全球社区做着贡献。






