
新智元报道
编辑:桃子
全新升级的第二代 Ameca 来了,GPT-4 加持,能够实时对答。
人形机器人 Ameca 升级第二代了!
最近,在世界移动通信大会 MWC 2024 上,世界上最先进机器人 Ameca 又现身了。
会场周围,Ameca 引来一大波观众。

得到 GPT-4 加持后,Ameca 能够对各种问题做出实时反应。
「来一段舞蹈」。

当被问及是否有情感时,Ameca 用一系列的面部表情做出回应,看起来非常逼真。
就在前几天,Ameca 背后的英国机器人公司 Engineered Arts 刚刚演示了团队最新的开发成果。
视频中,机器人 Ameca 具备了视觉能力,能看到并描述房间整个情况、描述具体物体。
最厉害的是,她还能模仿各种声音讲话,包括风格和语气语调,比如马斯克、海绵宝宝...
爆火 Ameca 背后技术
Ameca 机器人的第一段视频想必已经让许多人感受到了真正的「恐惧」。
此前发布的视频中,因为一名研究人员入侵它的个人空间,便一把抓住的研究人员的手。

最令人印象深刻的一个片段是,Ameca 活动肩骨后,突然间灵魂附体,大梦初醒般睁开双眼。

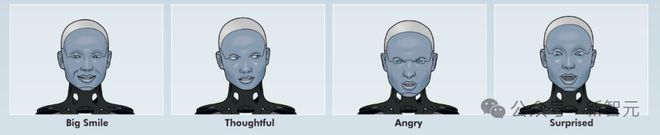
Ameca 还能把模仿真人表情做到了极致。从「嫌弃」到「惊讶」,都可以做到完全同步。

除了模仿,它自己也能照镜子做很多小表情,看起来与真人无异。

Ameca 是如何做出逼真的表情和拒绝人类的动作呢?
简单讲,为机器人配备一个更精细,更智能的身体(Artificial Body,即 AI×AB),主要依靠两大核心技术实现:
一个是机器人操作系统 Tritium,另一个是 Mesmer 技术。

Mesmer 是一个用于建造仿真人形机器人的系统。
它能为 Ameca 提供大量的真人表情数据,也正是上面提到「Ameca 做出逼真表情」的背后支撑。
通过 36 个摄像机对人体进行 360 度的 3D 扫描后,包括人类的骨骼结构、皮肤纹理和表情。
接着,从不同的角度捕捉多个重叠的数码照片,然后通过比较像素的颜色和锚点定位,来重建 3D 模型。

接着,从不同的角度捕捉多个重叠的数码照片,然后通过比较像素的颜色和锚点定位,来重建 3D 模型。
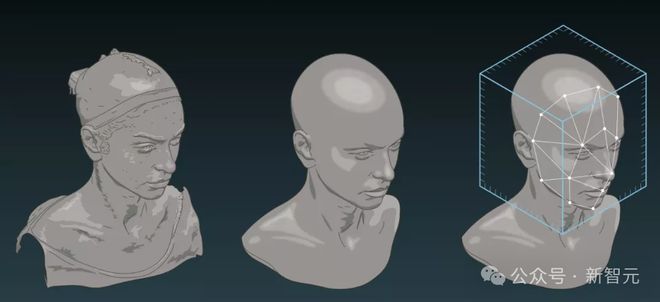
最后,在立体光刻 3D 打印机上制作的精确模具,硅胶填充要让皮肤质感看起来和真人一样。
然而,有了更智能的身体 AB,还需要有人工智能算法(AI)的支持。
Tritium 机器人操作系统被称为「为金属注入生命」的「魔法」,它连接了软件,硬件的和云端,可以驱动硬件的每一个组成部分。

在这两大核心技术加持下,无论是比较简单的喜怒哀乐,还是复杂度较高的吃惊、聆听等,Ameca 都可以做到与真人无异,让人细思极恐...

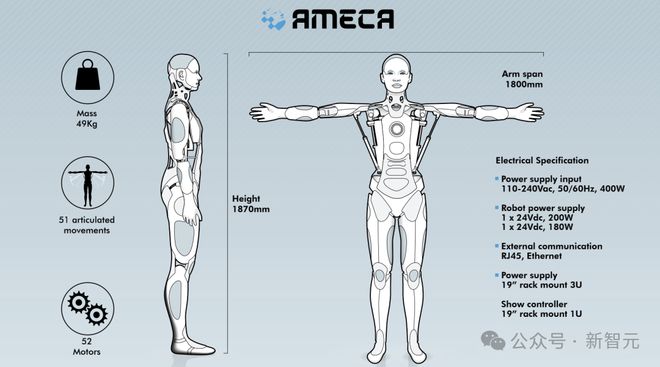
据介绍,Ameca 重 49kg,1.87m,身体共有 52 个模块,支持 51 种关节运动。
虽然 Ameca 能够做出逼真的表情,但它还不能走路。Engineered Arts 计划随着时间的推移将升级其能力,以便有一天它会走路。

除了像 Ameca 这样的机器人,Engineered Arts 还有客户服务机器人 Quinn、演讲机器人 RoboThespian。

其他演示
Ameca 面对工程师们的提问,回答也可以做到行云流水。
最关键的是,它回答时的表情、眼神和动作,给人一种交流亲切感。

当被问到你为什么会感到沮丧,Ameca 并没有回答。
之后,研究人员只是表达了同感,并没有真正说自己也同样沮丧,但 Ameca 的回答明显误认为研究人员也心情不好。
Ameca 还是一个多才多艺的机器人,能够流畅地画出一只猫。
参考资料:
https://www.techradar.com/tech/i-saw-the-worlds-most-advanced-robot-and-its-uncanny






