
当下,语言模型(LM)已经成为解决实际问题和推动技术发展的重要工具之一。
然而,与之相比,视频生成仍然主要局限于媒体娱乐和艺术创作。这种局限性往往使得视频数据的潜力和重要性被低估。
实际上,视频数据可以捕捉到难以用语言表达的物理世界中的重要信息。例如,丰富的视觉信息涵盖了语言无法表达的很多信息,它可以捕捉到物体的运动、形态的变化、环境的变化等现象,可以为人类提供更加直观和全面的认识。
同样,在科学研究、工程设计、医学诊断等领域,视频数据的应用也已经成为解决复杂问题的重要手段之一。
近日,来自 Google DeepMind 的研究科学家 Sherry Yang 及其团队,联合加州大学伯克利分校教授、伯克利机器人学习实验室主任 Pieter Abbeel 和麻省理工学院(MIT)博士 Yilun Du,在一篇题为“Video as the New Language for Real-World Decision Making”的论文中,探索了视频生成技术如何能够像语言模型一样,通过学习上下文信息、规划行为和强化学习等技术,充当规划者、智能体、计算引擎和环境模拟器,在现实世界中发挥更广泛的作用。

他们认为,与语言类似,视频可以作为一个统一的界面,吸收互联网知识并体现不同的任务,并提出一个观点:
视频生成之于物理世界,就如同语言建模之于数字世界。
视频生成,不只为了娱乐
与语言模型类似,视频生成模型通过学习上下文信息、规划行为和强化学习等技术来生成与给定条件相关联的视频序列,可以充当规划者、智能体、计算引擎和环境模拟器的角色,从而模拟和预测物体的运动、环境的变化等现象。
作为规划者,视频生成模型可以通过学习视频序列中的时空信息,生成未来帧的预测,从而规划出一系列可能的动作或行为序列。例如,在机器人学领域,模型可以根据环境中的物体位置和运动趋势,预测机器人的下一步动作,以实现特定的任务或目标。

作为智能体,视频生成模型可以通过强化学习等技术不断优化自身的生成能力,使得生成的视频序列更加逼真和符合预期。通过与环境的交互和反馈,模型可以不断学习和改进,逐渐掌握复杂的环境规律和行为模式,从而更好地应对各种情况和挑战。
同时,视频生成模型还可以充当计算引擎的角色,高效地处理大规模的视频数据,并进行复杂的推理和计算。借助深度学习等技术的强大计算能力,视频生成模型可以快速地生成高质量的视频序列,为实时应用和决策提供支持和保障。
此外,作为环境模拟器,视频生成模型可以模拟和重现各种现实世界场景,帮助人们更好地理解和分析复杂的物理过程和现象。通过生成逼真的视频序列,模型可以为科学研究、工程设计和教育培训等领域提供可视化的工具和资源,加深人们对物理世界的认识和理解。
具体而言,研究团队在生成游戏环境、机器人学、计算流体动力学等领域展示了视频生成模型的应用潜力,为解决实际问题提供了新的可能性。
在生成游戏环境方面,该论文提到了使用基于 Transformer 的架构进行动作条件视频生成,从而模拟复杂的计算机游戏环境,如《我的世界》(Minecraft)。视频生成模型既充当世界模型又充当策略,可以生成与复杂策略相对应的动作和转换。
此外,视频生成模型还可以生成新游戏环境。使用生成式模型,可以进行新游戏内容和关卡的程序化生成的研究。利用未标记的互联网规模的游戏数据,可以学习潜在动作,从而训练一个可控制动作的视频生成模型,使其能够从提示图像生成无穷无尽的多样化交互式环境。
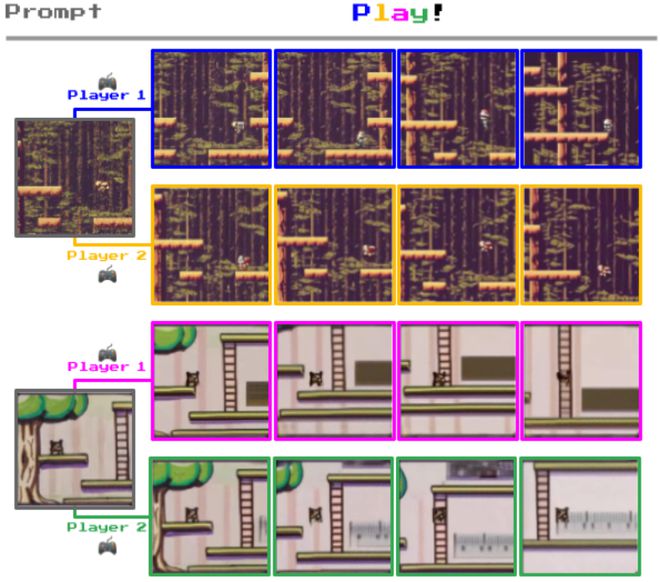
图|生成的交互式游戏环境。把两个合成图像(Bruce et al., 2024)提示传递给模型,模型将它们转换为交互式环境,可以通过采取不同的潜在动作来生成不同的轨迹,如玩家 1 和 2 所示。
在机器人学领域,视频生成模型可以生成具有真实感的机器人运动和操作场景。这为自主机器人、智能控制系统等领域的研究和开发提供了新的方向和思路,有助于提高机器人在复杂环境中的智能水平和应用能力。

图|自动驾驶的生成模拟。借助互联网知识,可以模拟特定地点的不同驾驶条件,如“金门大桥上的雨”(上)、“优胜美地的黎明”(中)和“前往优胜美地的路上下雪”(下)。
在计算流体动力学领域,视频生成模型能够生成逼真的流体运动场景,帮助科学家们模拟和分析复杂的流体行为,例如空气动力学、水动力学等。这为气象学、航空航天工程、水利工程等领域的研究和应用提供了新的工具和资源。

图|条件帧、真实下一帧和生成的下一帧反映了电子显微镜电子束刺激下石墨烯片上硅原子的视觉动态。生成模型能够以高保真度对视觉动态进行建模。
总的来说,实验结果表明,视频生成模型不仅可以用于娱乐和艺术领域,还可以应用于科学研究、工程设计等实际问题的解决。
视频生成,为什么还不够牛?
研究团队表示,尽管视频生成具有巨大的潜力,但在应用中仍然存在一些主要挑战,并概述了这些挑战和潜在的解决方案。
其中,数据集的限制是视频生成领域面临的主要挑战之一。现有的视频数据集往往规模有限、缺乏多样性,无法覆盖各种现实世界场景和情况。这导致训练出的模型在面对新领域或复杂场景时表现不佳,缺乏泛化能力和鲁棒性。同时,缺乏带有标签的视频数据,如 MineDojo 数据集中的游戏动作标签缺失,会导致模型训练困难。
未来的研究需要扩大数据集规模和多样性,包括收集更多的视频数据和丰富的标注信息,以及利用增强学习等技术生成合成数据,提高模型的泛化能力和鲁棒性。
另外,模型的异质性也会限制视频生成领域的发展。当前,自回归模型、扩散模型和掩蔽模型等各种不同类型的模型被用于解决不同的问题,导致模型异质性较高。这使得不同模型之间的性能和效果难以比较和统一评估,增加了模型选择和优化的难度。
扩散模型:采样速度较慢,对超参数敏感,且长视频序列生成不明确;
可改进采样速度、调整超参数和改善训练方法等。
自回归模型:
计算量大,可能出现漂移效应;
可改进解码方法,减少漂移效应,提高生成效率和准确性。
掩模模型:
引入采样偏差和独立采样步骤内的独立性假设;
可尝试结合不同模型的优势,如自回归和掩模模型,提高生成效果和速度。
此外,在视频生成过程中,还存在幻觉问题,比如对象随机出现或消失、动态不合理等现象。这可能是由于模型对不同物体的关注程度不均,或者对于动态变化的处理不够准确所致。
当用户输入的信息与特定场景不相符时,例如,向桌面机器人输入“洗手”,也可能会产生错误的结果。尽管如此,我们已经观察到视频生成模型试图通过采用第一人称视角的动作来生成真实视频,来满足这些不切实际的输入,如图所示。

图|视频生成模型的输入图像是带有机器人手的桌面。语言指令是“洗手”。该视频模型能够生成以自我为中心的运动,从桌面移至厨房水槽,以尝试真实地完成语言教学。
未来可以通过提高模型对不同物体的关注度,增加对小物体或边缘情况的处理能力,从而减少幻觉问题的出现。应用诸如带有外部反馈的强化学习等方法也可以减少视频生成模型中的幻觉。强化学习等技术也可以有同样的作用,通过对模型生成的视频进行评估和反馈,指导模型更好地理解和模拟现实世界场景。
最后,模型虽然在训练集上表现良好,但在测试集或实际应用中的泛化能力有限,无法适应新的场景和任务。这可能是由于数据分布不一致、模型过度拟合等原因所致。可通过空间超分辨率等技术来提高模型的泛化能力和适应性。
尽管如此,在论文的最后,研究团队写道:
尽管面临着诸如产生幻觉和泛化能力有限等挑战,视频生成模型仍有可能发展成为智能体、规划者、环境模拟器以及计算引擎,并最终成为在物理世界中进行思考和行动的人工大脑。






