
新智元报道
编辑:桃子
许久未更新大模型的英伟达推出了 150 亿参数的 Nemotron-4,目标是打造一个能在单个 A100/H100 可跑的通用大模型。
最近,英伟达团队推出了全新的模型 Nemotron-4,150 亿参数,在 8T token 上完成了训练。
值得一提的是,Nemotron-4 在英语、多语言和编码任务方面令人印象深刻。

论文地址:https://arxiv.org/abs/2402.16819
在 7 个评估基准上,与同等参数规模的模型相比,Nemotron-4 15B 表现出色。
甚至,其性能超过了 4 倍大的模型,以及专用于多语言任务的模型。
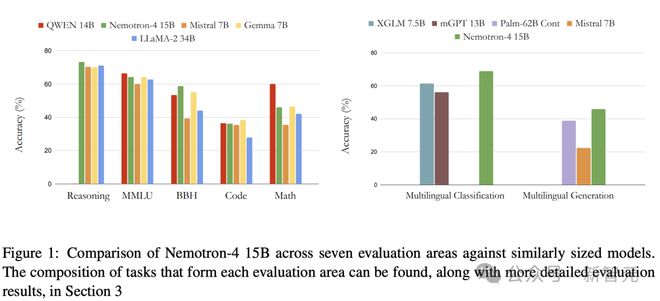
如今 LLM 已经非常多了,英伟达新发布的语言模型,有何不同?
打造最强通用 LLM,单个 A100/H100 可跑
最近发表的 LLM 研究受到了 Chinchilla 模型「缩放定律」的启发——给定固定计算预算,数据和模型大小一同优化。
而过去,研究主要针对模型大小进行缩放。
研究表明,给定两个数据分布类似的 IsoFLOP GPT 模型,一个是在 1.4 万亿 token 上的 65 亿参数模型,另一个是 3000 亿 token 上的 2800 亿参数模型。
显然,65B 的模型在下游任务上的准确性更高。
从推理的角度来看,将计算分配给更多数据的训练,而不是增加模型大小特别有吸引力,可以减少延迟和服务模型所需的计算量。
因此,语言建模训练工作的主要焦点已转向从 CommonCrawl 等公共资源中,收集高质量的数万亿 token 数据集。
对此,英伟达研究人员提出了 Nemotron-4 15B,来延续这一趋势。
具体来说,Nemotron-4 15B 是在 8 万亿个 token,包括英语、多语种、编码文本的基础上进行训练。
英伟达称,Nemotron-4 15B 的开发目的:成为能在单个英伟达 A100 或 H100 GPU 上运行的最佳「通用大模型」。
架构介绍
Nemotron-4 采用了标准的纯解码器 Transformer 架构,并带有因果注意掩码。
核心的超参数,如表 1 所示。

Nemotron-4 有 32 亿个嵌入参数和 125 亿个非嵌入参数。
研究人员使用旋转位置编码(RoPE)、SentencePiece 分词器、MLP 层的平方 ReLU 激活、无偏置项(bias terms)、零丢失率,以及无限制的输入输出嵌入。
通过分组查询关注(GQA),可实现更快的推理和更低的内存占用。
数据
研究人员在包含 8 万亿个 token 的预训练数据集上训练 Nemotron-4 15B。
分为三种不同类型的数据:英语自然语言数据(70%)、多语言自然语言数据(15%)和源代码数据(15%)。

英语语料库由来自各种来源和领域的精选文档组成,包括网络文档、新闻文章、科学论文、书籍等。
代码和多语言数据包括一组多样化的自然语言和编程语言。
研究人员发现,从这些语言中适当地采样 token 是在这些领域获得高准确度的关键。
此外,研究人员分别在图 3 和图 4 中共享预训练数据集中用于代码和多语言标记的分布。
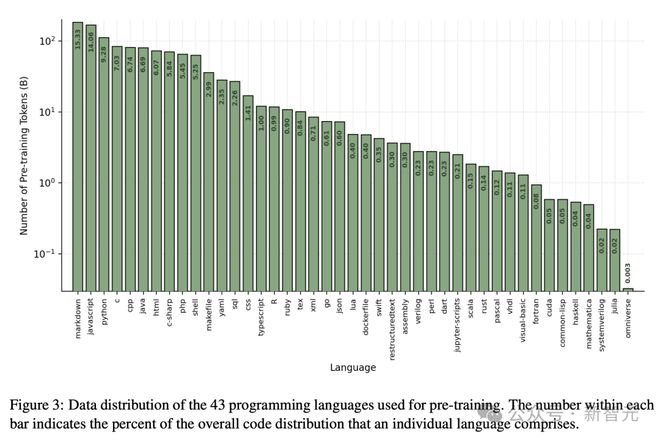
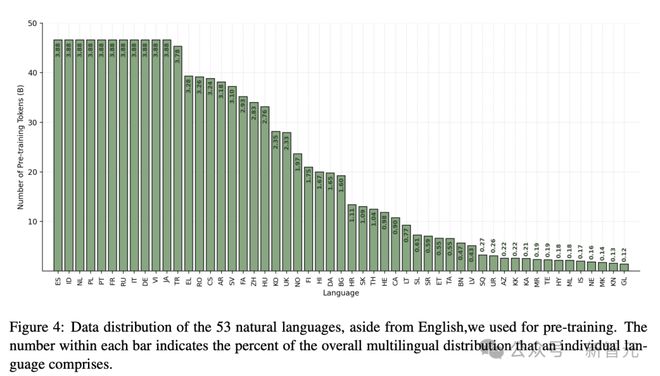
预训练
Nemotron-4 使用 384 个 DGX H100 节点进行训练。每个节点包含 8 个基于英伟达 Hopper 架构的 H100 80GB SXM5 GPU。
在执行无稀疏性的 16 位浮点(bfloat16)算术时,每个 H100 GPU 的峰值吞吐量为 989 teraFLOP/s。
每个节点内,GPU 通过 NVLink 和 NVSwitch(nvl)连接;GPU 到 GPU 的带宽为 900 GB/s(每个方向 450 GB/s)。
每个节点都有 8 个 NVIDIA Mellanox 400 Gbps HDR InfiniBand 主机通道适配器(HCA),用于节点间通信。
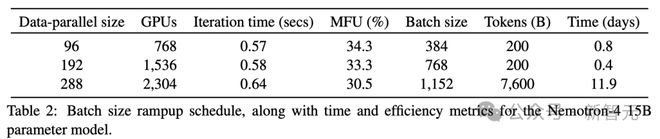
研究人员使用 8 路张量并行和数据并行的组合来训练模型,还使用了分布式优化器,将优化器状态分片到数据并行副本上。随着批大小的增加,数据并行度从 96 增加到 384。
表 2 总结了批大小提升的 3 个阶段,包括每次迭代时间和模型 FLOP/s利用率(MFU)。MFU 量化了 GPU 在模型训练中的利用效率。训练大约在 13 天内完成。
再训练
与最近的研究类似,研究人员发现在模型训练结束时,切换数据分布和学习率衰减时间表,可以极大地提高模型质量。
具体来说,在对整个 8T 预训练数据集进行训练之后,使用相同的损失目标,并对与预训练 token 相比的较少的 token 进行持续训练。
在这一额外的继续训练阶段,利用两种不同的数据分布。
第一个分布是,从持续训练期间大部分 token 采样。它利用在预训练期间已经引入的 token,但其分布将更大的采样权重放在更高质量来源上。
第二个分布,引入了少量基准式对齐示例,以更好地让模型在下游评估中回答此类问题,同时还增加来自模型性能较低区域的数据源的权重。
实验结果
研究人员在涵盖各种任务和领域的下游评估领域评了 Nemotron-4 15B。
常识推理
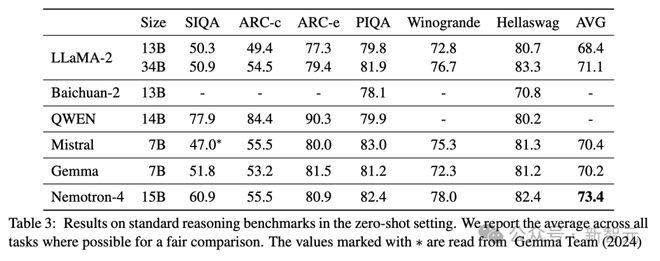
作者使用 LM-Evaluation Harness 在所有上述任务中评估 Nemotron-4 15B。
表 3 显示了 Nemotron-4 15B 在这组不同的任务中实现了最强的平均性能。
热门的综合基准
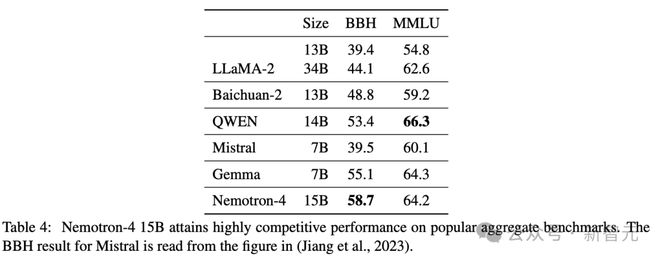
从表 4 可以看出,Nemotron-4 15B 在现有模型中获得了 BBH 的最佳分数,增长了近7%。
此外,Nemotron-4 在 BBH 基准测试中明显优于 LLaMA-2 70B 模型,其中 LLaMA-2 70B 的得分为 51.2,Nemotron-4 的得分为 58.7。
Nemotron-4 15B 另外还获得了极具竞争力的 MMLU 分数。
数学和代码
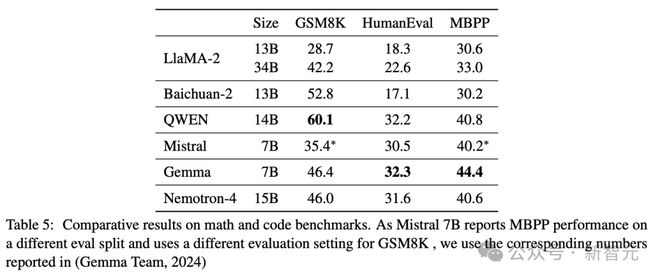
表 5 重点介绍了 Nemotron-4 15B 在数学和代码任务上的性能。
具体来说,在数学推理上,Nemotron-4 15B 表现强劲,得分与 Gemma 7B 相似,但落后于 Baichuan-2 和 QWEN 等模型。
在代码任务中,Nemotron-4 的性能与 QWEN 14B 相当,但略落后于 Gemma 7B。
在这两种类型的任务中,Nemotron-4 15B 的性能均优于 Mistral 7B 和 LlaMA-213B/34B。
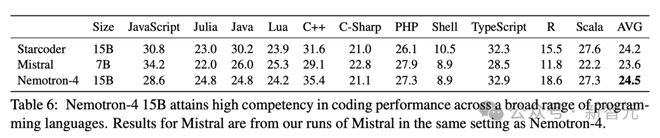
几乎所有类似规模的开放模型都只根据 Python 相关任务的性能来确定其代码能力,而忽略了对其他编程语言能力的评估。
在表 6 中,展示了 Nemotron-4 15B 在 Multiple-E 基准上的结果,涉及 11 种不同的编程语言。
结果发现,Nemotron-4 15B 在各种编程语言中都有很强的编码性能,平均性能优于 Starcoder 和 Mistral 7B。
研究人员特别强调了 Nemotron-4 15B 在 Scala、Julia 和R等低资源编程语言上的卓越性能。
多语言
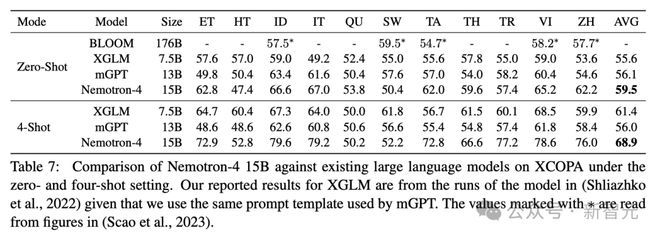
分类
在表 7 中,可以清楚地看到 Nemotron-4 在所有模型中实现了最佳性能,在 4 次设置中实现了近 12% 的改进。
生成
表 8 显示 Nemotron-4 15B 实现了最佳性能。
令人印象深刻的是,Nemotron-4 15B 能够显著改进下一个最佳模型 PaLM 62B-cont。
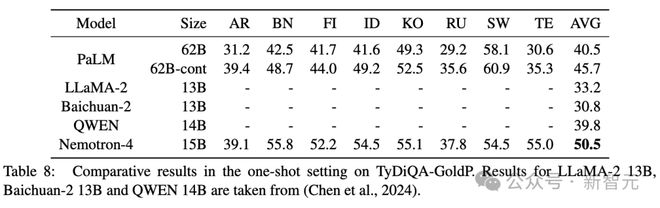
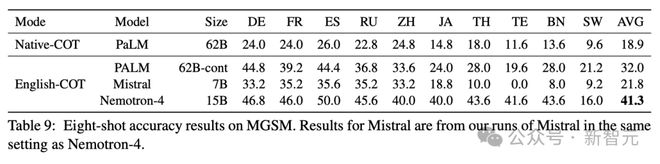
表 9 显示了 MGSM 上的性能,进一步证明了 Nemotron-4 15B 令人印象深刻的多语言能力。
在这项评估数学和多语言能力交集的挑战性任务中,Nemotron-4 15B 在比较模型中实现了最佳性能,并且比最接近的分数提高了近 30%。
机器翻译
如表 10 所示,Nemotron-4 15B 的性能远远优于 LLaMA-2 13B 和 Baichuan-2 13B,性能分别提高了 90.2% 和 44.1%。
Nemotron-4 15B 不仅在中文翻译成英文方面表现出色,而且在中文直接翻译成其他语言方面也能取得令人印象深刻的效果。
这种能力凸显了 Nemotron-4 15B 对广泛的自然语言的深刻理解。

参考资料:






