之前我们连续分析了两起误删库事件,Linear 删库,GitLab 删库。就在我们准备让这个主题告一段落时,业界又发生了一起删库事件。
这次的主角是 Resend,也是最近硅谷冉冉升起的明星初创公司。想重塑邮件体验,挑战像 Mailchimp 这样的老牌玩家。
这次的删库事件依然是熟悉的配方,在执行数据库 schema 变更时,本来是针对本地环境执行,但结果命令发给了生产数据库,就这样把数据都删没了。

而在恢复的过程中,第一次恢复使用了错误的备份,导致浪费了 6 个小时。又经过额外的 5 小时备份,才把数据库恢复过来,但还是有 5 分钟的数据丢失了。Resend 也列出了一些后续措施:
- 恢复 5 分钟丢失的数据
- 收回所有用户对生产环境的写权限
- 改进本地开发流程,以降低数据库 schema 变更的风险
- 提高故障演练的频率
也因为 Resend 小有名气,所以也引来了 Hacker News 上网友们的锐评:

太业余了,像 email 这种核心组件,还是交给更加成熟的 AWS SES,Postmark,Sendgrid 这些吧。

或许这家公司根本就不该存在。
如何避免
笔者认为这个故障虽然有点低级。但连错数据库这个事情,不算少见。备份过程碰到意外,也很常见。当然低级的问题,解决起来也不难。
针对第一点,引入像 Bytebase 这样的变更审核工具,所有针对生产环境的变更操作都要通过 Bytebase,经过人工审核后才能发布。
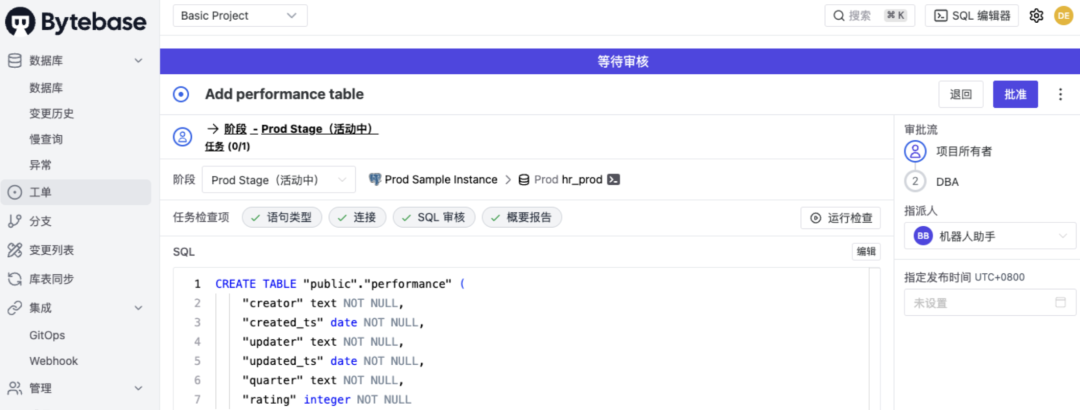
针对第二点,首先是采用云上的托管数据库服务,因为他们提供了完整的数据备份和恢复功能。另外就是定期做灾备演练。
大家也引以为戒吧。






