
出品|虎嗅科技组
作者|齐健
编辑|王一鹏
头图|DALL-E 3
全世界都在为 Sora 惊艳,而谷歌却仍在默默地发语言模型。
当地时间 2 月 21 日,谷歌推出了基于 Gemini 研究和技术开发的新型开源模型系列“Gemma”。与 Gemini 相比,Gemma 展示了更高的效率和轻量化设计,同时依然免费提供全套模型权重,并明确允许商业使用。
本次发布的模型包括 Gemma 2B 和 Gemma 7B,20 亿和 70 亿两种规模版本。每个版本都提供了预训练模型和针对特定指令进行微调的模型。用户可以通过 Kaggle、谷歌的 Colab Notebook 或 Google Cloud 平台轻松访问这些模型。

谷歌的技术报告中称 Gemma 已经在一系列关键基准测试上超越主流的开源模型,包括 LLaMA-2 的 7B 和 13B 版本,以及 Mistral 7B 模型。特别是在指令遵循、创意写作、编码任务和基本安全协议测试中,Gemma 都展现了良好的性能。
此外,谷歌还发布了一系列工具和指南,旨在鼓励开发社区协作并负责任地使用这些模型,推动 AI 技术的健康发展。
谷歌发布开源 Gemma 之后,OpenAI 成了唯一一个在这波 AI 热潮中没有发布过开源模型的 AI 公司。在 Google Deepmind 联创兼 CEO Demis Hassabis 的发布贴下,就有人@Sam Altman 质疑 OpenAI 何时才能 Open。

Gemma 有何不同?
Gemma 模型提供了预训练模型以及针对对话、指令遵循、有用性和安全性微调的 checkpoint。其中,7 亿参数的模型优化了 GPU 和 TPU 上的高效部署和开发,而 2 亿参数的模型则更适用于在 CPU 上运行,满足不同的计算限制、应用程序和开发人员需求。
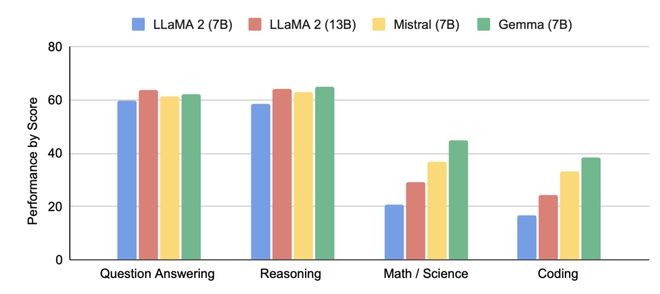
Gemma 对比 LLaMA 2-7B、13B,以及 Mistral-7B
Gemma 模型的架构基于 Transformer 解码器,针对其核心参数进行了优化,训练时的上下文长度为 8192 个 token。
此外,谷歌在原始 Transformer 理论的基础上进行了几项重点改进,优化了模型的处理效率、模型大小、性能和训练稳定性方面。
多查询注意力机制:相比传统的多头注意力,多查询注意力机制在 2 亿参数模型中的应用提高了处理效率和模型性能,特别是在参数规模较小的情况下,能够更有效地捕捉和处理信息。
旋转位置嵌入(RoPE):使用 RoPE 代替传统的绝对位置嵌入,以及在输入与输出之间共享嵌入的策略,有效减小了模型规模,同时保持或提高了模型的性能,尤其是在处理序列数据时的位置敏感性方面。
GeGLU 激活函数:替代传统的 ReLU 激活函数,GeGLU 提供了更强的非线性处理能力,这对于增强模型捕捉复杂模式和关系的能力是非常重要的,特别是在小模型中尽可能地提高性能。
归一化位置的创新应用:通过在每个 Transformer 子层的输入和输出处都应用归一化处理(使用 RMSNorm),Gemma 模型提高了训练的稳定性和效果,这种方法的创新在于它提供了一种更加有效的训练深层网络的手段,有助于提高模型的泛化能力和减少过拟合的风险。
Gemma 另一个值得一提的特点在于对安全性的重视。
Gemma 模型的全面安全评估中,包括对模型行为的深入分析和测试,以确保其在不同的应用场景中能够安全可靠地运行。同时,Gemma 的开发过程中融入了负责任的 AI 实践,包括确保模型的公平性、透明性和可解释性。这有助于减少 AI 系统可能带来的偏见和不公平现象,提高用户对模型输出的信任度。
随 Gemma 模型一同发布的还有一套详细的安全使用指南,指导用户如何安全、有效地使用 Gemma 模型。这包括建议的使用案例、潜在风险的警告以及如何缓解这些风险的策略。
作为开源模型,Gemma 项目也鼓励社区合作和反馈,通过开源的方式让研究人员和开发者能够贡献自己的见解和改进意见。这种开放的合作模式有助于及时发现并修复安全漏洞,提高模型的整体安全性。
事实上,在今天快速迭代的 LLM 开发环境中,一款轻量化开源模型的安全性能,是模型能够开放到更多应用场景的重要前提。
落到手机、电脑、汽车上的 AI
谷歌在 Gemma 的说明页面中提出,要实现先进人工智能模型的“民主化访问”,并特意强调 Gemma 可以部署在资源有限的环境中,例如笔记本电脑、台式机或用户自己的云基础设施,
如今,轻量化的 AI 模型在业内的受关注度正在快速升温。
2023 年 6 月,微软就放出了一款 17 亿参数的轻量化模型 Phi,此后的 Phi-2 版本参数扩充到了 27 亿。国内则有两家公司推出了 7B 以下的轻量化 LLM,包括面壁智能的 MiniCPM-2B,以及阿里 Qwen1.5 中的 0.5B、1.8B 和 4B 三个版本。
面壁智能的 MiniCPM-2B 模型就直指手机端,且已经在多款常见的手机上测试了模型的真实落地效果。
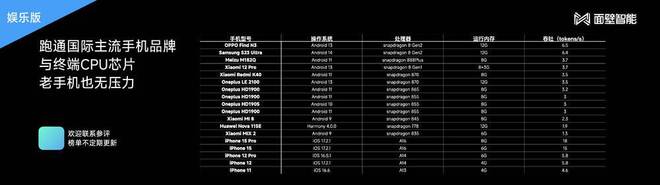
MiniCPM 在手机端的运行情况
虽然同为 20 亿参数,但相比于可以运行在 4G 内存手机中的 MiniCPM-2B,Gemma-2B 的模型存储容量明显有点大,一般的手机可能很难运行,目前 Gemma 的技术报告也没有提及在个人设备上的输出速度。
Gemma 在 hugging face 的下载页面
运行速度快、成本低、高端设备依赖性不强,这些特点使轻量化模型明显更容易商业化落地,最典型的就是落地到手机、电脑、车机这些端侧设备的 AI。
目前,主流、非主流的消费电子、汽车企业都在积极布局 AI。
国内 OPPO 和魅族两家手机厂商刚刚更新了 AI 战略,其中魅族甚至要放弃传统手机,只做 AI 手机;联想、戴尔、惠普、华硕等都公布了自己的 AI PC 战略,英伟达最近推出了一款可以在本地运行的 Chat with RTX,显卡要求 7G 显存,其中主要调用的就是 Mistral 的 7B 模型;车机方面,奔驰、宝马、大众等也都推出了融合 AI 大模型的车机系统,国内的比亚迪,也在近期推出了全新的整车智能化架构“璇玑”及其 AI 大模型“璇玑 AI 大模型”。
Gemma、MiniCPM、Qwen1.5 等开源轻量化的推出,给这些设备生产公司提供了一个不必自研大模型,也能在设备上部署 AI 的路径。
事实上,在复杂的算法研究和高昂的训练成本面前,多数企业并不具备从零开始开发大模型的能力。
基于 LLaMA 等开源大模型的再训练或微调成为了一个更实际和成本效益更高的选择。通过 Continue Pretrain、finetune 等方法,开发者可以在现有模型的基础上进行改进和定制,以适应特定的应用需求。这种方法不仅减少了开发成本,也加速了模型创新的过程,使得即使是资源有限的团队也能参与到大模型开发的竞争中来。
国内大模型创业的主流形态正是基于 LLaMA 等开源模型的再训练或微调。尽管从零开始自研大模型在技术上具有一定的吸引力,但如专家所言,这需要极高的成本和专业知识,且过程复杂且容易出错。因此,利用和贡献于开源大模型社区,不仅是实现快速迭代和创新的有效途径,也是促进技术共享和行业进步的重要手段。
一直以来,AI 大模型开发和模改的主流生态都被 LLaMA 占据,直到 Mistral 出现才略有改观。此番谷歌放出开源 Gemma,给开发者提供了更多选择和灵活性,注定会对开源生态起到巨大的刺激作用,促进了开源大模型技术的发展和应用创新。






