
图源:pixabay
撰文丨张天蓉
计算机和通信的基础是比特,比特是物理系统产生的物理量,有时难免会出错而影响所传递信息的可靠性。不过,发展成熟的经典计算技术,已经具有自动纠错的功能,而如今正在起步的量子计算,也将纠错提到议事日程上,并作为其成败的关键因素。那么,计算机到底是如何纠错的?量子纠错比较经典而言,又有哪些特别之处,如何克服?本文探讨一下这些问题。
一、经典纠错由来已久
提高系统的可靠性一般有两种办法:一是对硬件缜密设计和质量控制,尽量减少出错的概率;二是以冗余为代价来换取可靠性,算是软件方面的努力。硬件的控制是有限的,必须利用软件编码来“容许”错误。因此我们主要介绍利用冗余的容错纠错技术。
在计算和通讯中出现错误是很自然的事。上世纪五十年代的早期经典计算机,用电子管或继电器构建的比特,会毫无预兆地发生反转。为此数学家冯·诺伊曼提出利用冗余比特来纠错的容错技术。冗余纠错很容易理解,比如说你电话中告诉别人你的名字,说一次不够就说 3 次“我是张三、张三、张三……”,次数越多,传错听错的概率就越小。冗余纠错的方法便类似于此,最早的冗余纠错是奇偶校验法[1]。
举一个最简单的奇偶校验例子。如果我们需要传递 7 位数字的二进制数,也就是 7 个比特位。这一串 7 个比特值中有 1 有0,均有可能出错。我们考虑 7 个比特位中 1 的个数n:因为传递的信息的随机性,n也许是偶数也许是奇数,见图 1a。然后,我们在 7 个信息比特后面加一个比特,即加一个冗余的比特,或称校验比特。校验比特是设置为 1 还是 0 呢?由如下规律决定:如果原始信息比特中n是奇数,将校验比特设置为1;如果原始信息比特中n是偶数,将校验比特设置为0。也就是说,信息比特加上校验比特共 8 个比特中,1 的总数总是为偶数,见图 1b。

图1:奇偶验证例子
这样的话,接收方收到 8 个比特后,如果其中 1 的总数是奇数,那就一定是出错了!当然,这种方法并不能判定是哪儿出了错,也无法纠正错误,但至少可以扔掉错误信息,让对方重发一次。以上例子说的是奇偶校验中的“偶校验”,也可以类似地将校验比特设置为“奇校验”规则,如图 1c 所示。
由于奇偶校验很简单,所以至今也还被使用。上例中的 7 个比特,只使用了一个校验比特,就已经能检查某些基本错误,如果再增加冗余比特数,便可达到更准确有效的纠错方法。还要说明的一点是:上述例子中所谓的“奇偶”,刚好与通常理解的“奇数偶数”概念相符合,但实际上,计算科学中的奇偶校验,检查的是 parity,与检查奇数偶数有所区别,比如下面的 3 比特纠错。
例如,可以对每个比特都做 3 份拷贝,为什么是 3 呢?因为 2 份不是很合适,只有两份的话,如果检查到两个数字不一样,那是谁错了呢?好像有点扯不清楚。3 个就可以“服从多数”了。比如说,如果检查错误时发现:第 1 个和第 3 个比特相同,但第 1 个和第 2 个、第 2 个和第 3 个都不同,那么最有可能是第 2 个比特翻转了,如图 2 所示。于是计算机就把那个错误的比特再翻回来。冗余数目越多,机器便具有越大的纠错能力。不过,集成电路普及后,晶体管比特出错几率较小,纠错技术在经典计算机中使用不是很多,但对它的研究还是比较深入的,容错控制技术仍然经常被使用,特别是用于环境复杂、出错因素比较多的通讯技术中。
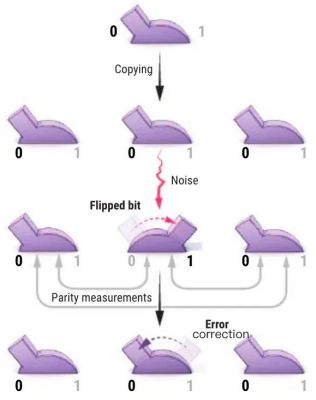
图2:3 个重复比特的纠错方法
二、量子纠错 3 点困难
量子计算机有运算速度快的潜力,但量子比特却十分脆弱,与周围环境发生哪怕极微弱的相互作用也会导致它们发生改变,物理上被称为“退相干”的效应。所以,量子纠错是很重要的课题。
量子纠错可以采用“利用冗余”这个相同的理念,但在具体实施时,量子比特的困难很多[2],有别于经典纠错之处可以主要归结为如下 3 点。
第一点是来自于量子比特与经典比特本质上的不同。量子误差比经典比特误差复杂得多。经典比特只有0、1 两种状态,而量子比特是两种状态组成的所有叠加态。这相当于除了需要判断 0 值或 1 值的变化之外,还需判断态矢量在三维 Bloch 球面上的相位误差,这是一个可以从0°到 360°之间变化的连续变量,不是像(0、1)那种更易于判断正确错误的离散量。
传统计算机进行一个比特的冗余纠错,需要将它复制到其他比特上,然后对所有的比特进行测量以比较它们的数字规律来判定是否出现了错误。然而,量子力学原理使得直接通过复制并测量量子比特并检测错误的方法完全不可行。因为量子力学中有一个不可克隆原理,即不可能构造一个能够完全复制任意量子比特,而不对原始量子位产生干扰的系统。这是量子纠错的第二个困难。
最后,纠错的第 3 个困难是量子系统没法“测量”。任何测量都将导致系统的波函数塌缩(或称为退相干效应)。
基于上述困难,量子纠错的发展过程中,甚至出现越纠越错的情况。不过,科学家们在多年的研究和探索中,也找到一些办法来克服量子纠错的困难。总结起来一句话仍然是“增加冗余的量子比特数”。即用多个物理量子比特,对应 1 个逻辑量子比特。所以,我们在判定量子计算机的能力时,不能仅仅看它的量子比特数,要看它的“逻辑量子比特数”。
三、如何克服量子困难
首先说说从原则上如何克服上述量子纠错的 3 点困难。
第一点困难是由于量子叠加态的连续变换,使得早期时,人们认为这是制造可用量子计算机的根本障碍。人们认为,少数量子位执行的⼀些操作,难以扩展到具有许多量子位阵列、可以长时间运行的计算系统中。
后来,科学家们将量子比特的错误,归于两类错误:X错误和Z错误,X错误指的是量子位0、1 的错误,与经典情况“位翻转”的错误一样,见图3。然而,另一类Z错误是经典计算中没有的,可以看作是布洛赫球面上相位的错误。量子比特的相位是连续变化的,但在量子纠错时,相位的错误被量子化成了“相位翻转”的离散值,用Z错误来表征。因为量子纠错多了一个Z错误,简单的经典三量子位重复码不能够防⽌所有可能出现的量子错误。真正的量⼦纠错需要更多的东⻄。20 世纪 90 年代中期,AT&T贝尔实验室的彼得·秀尔(Peter Shor)描述了⼀种精美的⽅案,把 3 位重复码嵌入另⼀个码。也就是说,将⼀个逻辑量⼦位,用 9 个物理量⼦位进行编码。秀尔的方案可以防止并纠正任何⼀个物理量子位上发生的任意量⼦错误。值得一提的是,这位提出量子纠错的第一人,MIT 的数学教授秀尔,也是提出质因数分解量子算法的人。
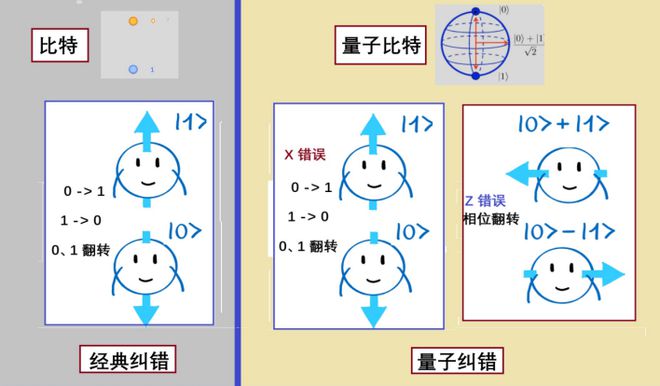
图3:经典纠错和量子纠错
秀尔也提出了办法来克服量子态退相干不可测量的问题,以及量子比特不可克隆的困难,基本思想就是利用量子纠缠,这一个量子世界的独特现象。秀尔让编码⼀个逻辑量⼦位的 9 个物理量⼦位互相纠缠在一起。有关量子纠缠这方面我们不予详细介绍,有兴趣者可参考相关文献[3]。
那么怎样具体进行量子纠错呢?再次回想一下经典纠错,比如说:用“000”和“111”来代表“0”和“1”的方案,如果“000”中有一个比特发生了翻转,我们通过读出这三个比特发现错误,就可以纠正它。当然也有可能两个比特同时发生错误,这时纠错则将导致最终的错误。这样的话,会不会“越纠越错”呢?经典纠错不会,因为根据概率规则,两个错误同时发生的概率是发生一个错误概率的平方,而经典计算出错概率很小,例如假设是万分之一,那么这个小概率的平方只有亿分之一,更多的重复编码,可以把错误率逐步降低倒几乎为0,这就是经典纠错的基本机制。
量子纠错遵循同样的思想。比特位发生翻转的错误,被定义为X错误,符号(相位)发生翻转的错误被定义为Z错误,这两种错误也有可能同时发生,这时将其定义为 XZ 错误。三类错误(X、Z 、XZ),分别对应于量子力学中的泡利矩阵 X、Z 和 Y。纠正X错误的情况与经典情况一样(图3);为了纠正Z错误,可以用“000”和“111”的叠加态“+++”和“---”来编码。如此,一共 9 个物理量子位,巧妙地组成某种嵌套式的编码,就可以同时纠正X和Z的错误。这个用 9 个量子比特来代表一个逻辑量子比特,就是当年秀尔提出的第一个量子纠错码。如此构成的一个逻辑量子比特,其性能表现比一个物理比特更好。但是,因为量子系统的错误率太高了,纠错本身也会发生错误,所以仍然有“越纠越错”的可能性。
要避免越纠越错,量子纠错必须达到一个盈亏平衡点,这个点与纠错码的结构有关。纠错码的结构中有一个重要的参数d,叫做纠错码的距离。距离是在任一维度上跨越代码的物理量子比特数。距离d越大,需要的冗余量子比特就越多,纠错性能便越好。同时,d与另一个参数t有关:2t+1=d,意味着对应距离d的编码,可以纠正t个比特上的X, Z 或者 XZ 错误。例如, 如果一个纠错码d=3,得到t=1,意味着可以纠正 1 个物理量子比特上的错误。如果d=5,则t=2,可以纠正 2 个物理量子比特上的错误。一般来说,需要提供的物理量子比特的数目,正比于距离 d 的平方,而错误率与距离d的关系如图 4 所示。
由图 4 可见,逻辑量子比特误差的概率随着距离d的增加呈指数级下降。但欲使距离增加,又必须增加更多的与d成平方关系的冗余量子位数目。

图4:误码率 vs 距离
四、量子纠错最新进展
自秀尔之后,为了更有效地利用量子比特,有更多、更高效的纠错码被提出和研究,例如图 5 所示的 Steane 码和表面码。

图5:量子纠错的 Steane 码和表面码
通过纠错,科学家们希望实现的目标是“容错量子计算”。在这种计算中,建立起足够的冗余和适当的编码,使得即使有几个量子比特出现错误,系统仍能运行并返回准确的答案。量子比特数的扩张,以及量子纠错技术的重大进展,是实现量子计算的关键和挑战。
所以,量⼦纠错的思想就是将单个“逻辑”量子比特值在多个物理量子比特之上进行复杂的编码,合称为纠错码。量⼦纠错码有很多种类,各有优缺点。例如上面说的 Shor 码,是 9 个物理量子比特,编码 1 个逻辑量子比特。图 5 左土的 Steane 码,用 7 个量子比特,编码一个逻辑量子比特。除此之外,还有表面码、色码、积码、等。其中的表⾯码是最常用的一种拓扑码(图 5 右图)。表面码由于容错阈值高、且与二维网格结构完美兼容,近年来被认为是最有潜力和实用价值的量子纠错码方案之一。
从实际操作的角度考虑,俄裔美国物理学家,加州理工学院物理系教授基塔耶夫(Kitaev)提出了量子纠错表面码,通过使用二维方格上布局的量子比特来进行编码和探测,得到良好的纠错性质。由于超导、离子阱和中性原子等技术,均可实现这种量子比特的布局,表面码纠错成为近几年的研究热点。除了纠错码之外,基塔耶夫对量子计算做出了杰出的贡献,在朗道理论物理研究所工作时,他引入了量子相位估计算法和拓扑量子计算机,并引入了任意子。他曾获基础物理学奖、狄拉克奖等。
表面码等仍然需要大量的物理量子比特,来编码一个逻辑量子比特。例如,一个距离为 10 的表面编码将需要大约 200 个物理量子比特来编码一个逻辑量子比特。2023 年之前,表面码需要多达 4000 个物理量⼦位来构建 12 个逻辑量子位。
所幸的是,2023 年底,量子计算技术迎来了几项重要的突破,包括量子纠错方面的突破。在 2023 年 12 月 6 日发表于《Nature》的论文中,美国哈佛大学米哈伊尔·卢金(Mikhail Lukin)领导的团队,采用了一种全新的纠错方法,将 280 个物理量子比特转化为 48 个逻辑量子比特。这比 IBM 希望在其下一代芯片中实现的效果要好 20 倍,比当前技术试图达到的1,000 比 1 的比例要高效 200 倍。哈佛大学的研究人员与 MIT 等团队合作,成功在一个具有 280 个物理量子比特的系统中,制备了 1 个码距为7、或者 40 个码距为3、或者 48 个码距为 2 的逻辑量子比特,并对上述不同码距的逻辑量子比特进行了有效的错误探测,研究了经过后选择的逻辑量子比特的性能,为实现更多不受错误干扰的逻辑量子比特,提供了重要的技术基础。
哈佛等团队的 48 个逻辑量子比特听起来似乎还不多,但量子计算机的计算能力是以指数级增长的。总之,2023 年量子计算机的一系列研究成果预示出,建造实用量子计算机的竞赛正在进入一个新阶段。2024 年将如何发展,科学家们正拭目以待。
[1]Ziemer, RodgerE.; Tranter, William H. (17 March 2014). Principles of communication : systems, modulation, and noise (Seventh ed.). Hoboken, New Jersey.
[2]基于超导量子系统的量子纠错研究进展,Acta Physica Sinica, 71, 240305 (2022) DOI: 10.7498/aps.71.20221824
[3]张天蓉,世纪幽灵-走近量子纠缠[M].合肥:中国科技大学出版社,2013 年 6 月。






