
作者:朱秋雨
来源:盐财经(ID:nfc-yancaijing)
横空出世的 ChatGPT 狂潮,让科技公司久违地出现了“神仙打架”。
2 月 7 日,谷歌宣布推出 ChatGPT 竞品 Bard 不久,中国 AI 巨头百度也表示,即将推出大语言模型“文心一言”。
对 ChatGPT 的焦虑蔓延在中国大厂间。百度紧锣密鼓地加紧与合作伙伴的官宣,称 3 月百度地图、联想小新等平台,都将接入文心一言。
一周之内,中国科技巨头纷纷对 ChatGPT 表态。
腾讯 2 月 9 日称,在相关方向上已有布局。 阿里巴巴则被曝将 AI 大模型嵌入钉钉。公司也回应称,“确实在研发中,目前处于内测阶段”。 科大讯飞称,公司已有超过 40 个通用领域的中文预训练语言模型,预告新产品将于 5 月推出。
ChatGPT 的横空出世,让众多大厂慌了阵脚。清华大学计算机系自然语言处理实验室副教授刘知远对盐财经回忆,AI 在历史上成功出圈的次数不多。上一次备受瞩目的时刻,要属 2017 年击败柯洁的围棋 AI——AlphaGo 的推出。
谁也没想到,2023 年,人工智能正将成为颠覆人类工种的效率工具。有人把 ChatGPT 的颠覆性比作苹果、安卓系统,说此时的人工智能好比当年未爆发能量的智能手机。
“中国这一波必须要跟,” 新浪微博 AI Lab 负责人张俊林告诉盐财经,“再过 3 年、5 年去做 ChatGPT,已经跟不上了。”
尽管,从实际情况出发,“百度们”的数据质量和成本因素影响下,要推出中国版 ChatGPT 难度依存。
不过,在鼓吹 ChatGPT 带来的广阔天地时,一个重要的问题待解:为什么 ChatGPT 的技术代表了未来?
搞清楚这个问题,我们再推测,中国大厂们做 ChatGPT,到底差了哪一截。
01
总统的演讲稿,ChatGPT 写的
2022 年的最后一个月,中文互联网的话题围绕着给出古怪回答的 ChatGPT 展开。尽管该公司很快屏蔽了中国地址用户, ChatGPT 的精彩回复已经以截图形式在网络广为流传。
概括 ChatGPT 的惊艳感,那便是以假乱真、接近人类。

ChatGPT 写的悼念文章,笔触细腻
它能说出“一旦你拥有了过去,你就可以创造整个宇宙”的金句,也能在人类提示下,写作、作诗、模仿名人说话。
以色列总统艾萨克 · 赫尔佐格在 2 月 7 日的发表演讲时透露,自己的部分讲稿就是 ChatGPT 撰写的。
比如,演讲结尾这句,“让我们不要忘记,是我们的人性让我们真正与众不同。”
ChatGPT 拥有如此强的语言能力,连长期研究 AI 自然语言处理的专家也感到吃惊。张俊林坦言,ChatGPT 是基于 GPT-3.5 模型的产品,“我想过 ChatGPT 会很好,但没想到那么好”。
比起 5 年前火了的 AlphaGo,张俊林惊叹的是 ChatGPT 覆盖各个领域的实用性。“AlphaGo 尽管带了一波热潮,但对实际应用的带动很有限。如何下围棋,这是一个封闭问题。”
而“上知天文下知地理”的 ChatGPT 经发布,已经让许多行业感到被撼动。
张俊林举例,ChatGPT 的编程代码能力很强,可以根据人类一句话生成代码。“据我所知,一些公司开始用它生成或检查代码,来替代程序员的部分工作。”
清华大学计算机科学与技术系长聘副教授黄民烈告诉盐财经,ChatGPT“在一个模型里可以完成各种开放式任务,而且智能化水平相当之高,任务范围覆盖之广,能力之强,”这是令他惊叹的。
张俊林介绍,在现今科技公司的竞逐上,ChatGPT 背后依托的大语言模型(LLM)一直都在持续升级。
据 Analytics India Magazine 整理的全球顶尖大厂的 LLM,许多都迈入了千亿参数级。Open AI 的 GPT-3 模型有 1750 亿个参数,谷歌的 LaMDA 模型有 1370 亿参数,LG 的 Exaone 模型有 3000 亿参数。
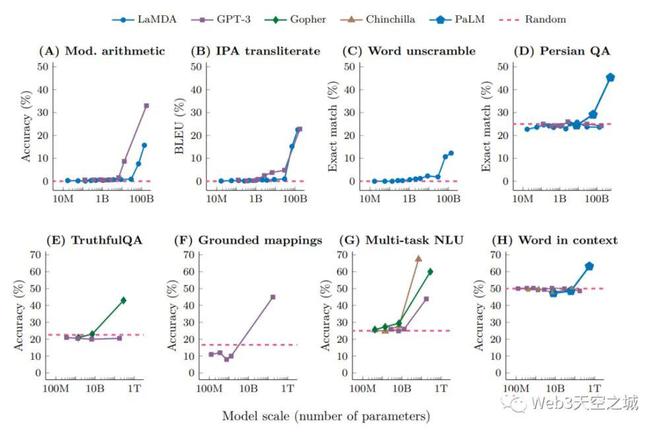
2022 年 6 月 15 日,谷歌研究院联合 DeepMind 和斯坦福大学发表了一篇论文:《大语言模型的突现能力》(Emergent Abilities of Large Language Models)。其中研究了谷歌,DeepMind 和 OpenAI 的 5 个语言模型系列的 8 个“突现能力”
上榜的两家中国公司在体积上也不示弱。百度的 ERINE 3.0 拥有 2600 亿参数,华为的盘古大模型有 2000 亿。
但“一直以来最大问题是,大语言模型的能力比较强,使用的时候却发挥不出它的能力,”张俊林说。
ChatGPT 的一大突破体现在此。它创造了结合人类反馈信息训练语言模型(RLHF)的办法。
据 Open AI 披露,ChatGPT 的训练分为三步。第一步常规步骤,即训练及微调 GPT 模型。
第二步是使用真实的用户评价标记生成内容的排序,训练出奖励模型(Reward Model)。
第三步,通过奖励模型为 GPT 生成内容打分,再用近端策略优化(PPO)进一步优化模型。
通过人类的真实评价来训练模型,张俊林说,这让 ChatGPT 在理解人的表达和语意上更进一步。“人们可以对着它畅所欲言,想说什么就说什么,和它反复对话,它都完全可以理解。这一点是最有突破性的。”
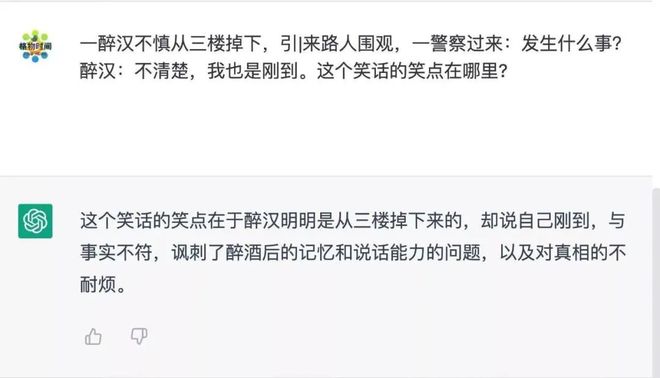
ChatGPT 对文本的理解能力很强,甚至能够“读懂”笑点
Open AI 同时要求人工标注员在评价机器生成结果时,遵循“有用”“真实”“无害”三大原则。这让 ChatGPT 给人一种礼貌、真诚、不冒犯人的体面感。
而在 ChatGPT 未出现之前,张俊林介绍,机器训练的效果通过测试集合来评估。“假设,测试集合里有 100 个任务,每个任务都有打分和指标。那么 AI 模型的优劣,最终通过完成任务的优劣程度来决定。”
这个办法,没有将真实的人的需求考虑入内。
“ChatGPT 的基座模型都在真实调用上不停迭代和优化。它不仅仅是技术上的成功,更是系统、工程、数据上的成功。”黄民烈总结。
02
百度的自嗨与自省
“ChatGPT 这一波浪潮,中国必须要跟,”张俊林焦虑地说:“通用人工智能 3 至 5 年迭代一次。在这一波落后的话,今后想跟也跟不上了。”
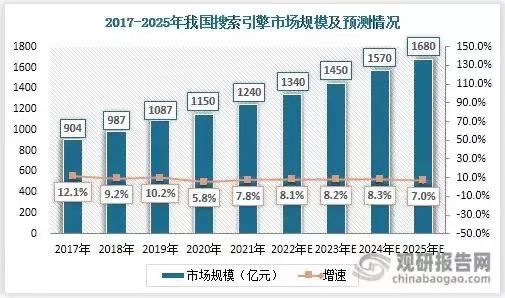
2017-2025 年我国搜索引擎市场规模及预测情况,随着消费互联网红利见顶,增长放缓成为了搜索巨头们的共同问题。图源:观研天下
也难怪被寄予厚望的国内巨头百度最为着急,2022 年底,李彦宏梳理了百度的不顺。
“百度这几年过得比较苦,财报、业务增长性都不是那么光鲜。”他还说:“有些技术同学做的事离市场很远,纯属自嗨,做了一两年发现东西没人用。”
批评归批评,李彦宏还是把希望落在了百度自称深耕 10 年的 AI 技术上。他判断,“百度的机会是把技术变成人人需要的产品,这一步最难,但也最能产生影响力。”
人人需要的产品,百度不是没做过,搜索引擎便是,只是基本公认已经被它做废了。以至于偌大中文市场,没有一个好用的搜索引擎。
ChatGPT 带来的技术未来,如果百度再棋差一着,这家企业未来的存在堪忧,也会被口水淹没。所以焦虑是必然的。
如果说 2022 年的百度还在忧愁 AI 该向落向何处,ChatGPT 在 2023 年被微软加快嵌入 office 产品和搜索引擎等的一系列动作,给了百度充足的紧迫感和方向感。
张俊林认为,之所以说 ChatGPT 是从零到一的产品,是因为它给 AI 届指明了大模型和通用人工智能的方向。
“以前 AI 的研发倾向于按领域训练出一个专有模型,比如一个专门翻译的 AI 模型,一个用于文本摘要的模型等等。但 ChatGPT 给大家证明一点,一个大规模的通用模型,可以解决大多数问题和任务。”
刘知远也告诉盐财经,ChatGPT 的出圈会让 AI 从过去只解决特定问题的“小作坊”转向了完成通用任务的“航空母舰”。这是两种底层技术的区别和迭代。
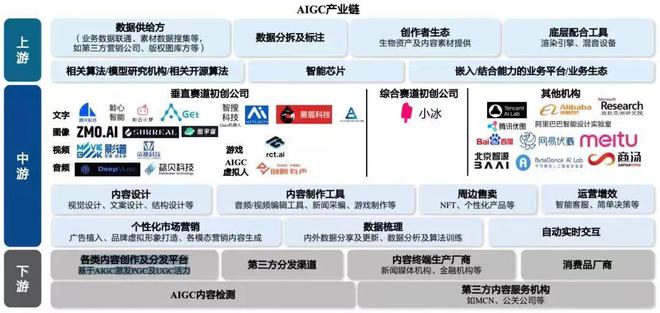
AIGC 产业链,图源:国海证券
他介绍,在 2010 年左右,AI 的深度学习曾受过一轮关注和讨论。当时的成功建立在有监督的机器学习上。
“AI 学习的数据提前由专家标注好,这些数据都是有目标的。”此后的很长一段时间,“大家默认,数据标注得越多,模型学得就越好”。
但 2018 年开始,Open AI 的 GPT 模型和谷歌的 Bert 等大语言模型横空出世,都是基于自监督学习方法。
“这类大模型的不同之处在于,不事先假定到底需要完成哪些任务或者特定能力。它穷尽互联网尽可能获取多的数据,让模型自动地从这些数据里面学习知识。”
几次迭代后,从 ChatGPT 的效果看,AI 技术已经发生了跨越式的变化。
刘知远回忆,人工智能在 2018 年左右有一个热门研究领域,叫少次学习(Few-shot Learning),即假设 AI 学习了大量一定类别的数据后,对于新的类别,只需少量的样本就能快速学习。
“大模型的数据训练之后,我们会发现,因为 AI 见得足够多,它已经有了非常强的联想类比能力。过去没有的推理能力、少次学习、举一反三的能力,好像一下都出现了。”刘知远说。
喜人的技术革新由 ChatGPT 率先引爆。上述专家都相信,今后,大语言模型将成为人工智能届的主流。
03
中国没能诞生 ChatGPT,谁全责
一个重要的前沿方向在几年前就出现。但 2018 年以来,除了 Open AI 和谷歌“大张旗鼓”在做,鲜有科技公司入局。中国的大厂除了百度和华为,其他也极少公开其对大语言模型的布局。
一个说法是,这是一个很贵的技术。Open AI 很特殊,所有的资源流向了它。
2019 年,设计 ChatGPT 的旧金山小公司 OpenAI 获得了微软大手笔 10 亿美元的投资。在此后的几年里,微软又悄悄地投资 20 亿美元。
完美的合作不止体现在“不差钱”上。前谷歌研究员艾登·戈麦斯曾表示,“建立这些系统真的需要一台超级计算机。而地球上没有多少这样的计算机。”
2019 年,Open AI 首席执行官山姆·奥尔特曼在受访时透露:“微软 10 亿美元的投资大部分是以 OpenAI 所需的计算能力出现的。微软成为其实验室唯一的算力来源。”
靠着“金主爸爸”的投资,GPT-3 模型在 2020 年推出时,便突破了千亿级参数。据国盛证券 2 月 12 日名为《ChatGpt 需要多少算力》的报告估算,GPT-3 训练一次的成本约为 140 万美元(约合 960 万元)。对于一些更大的语言模型,训练成本介于 200 万美元至 1200 万美元(1300-8300 万元)之间。
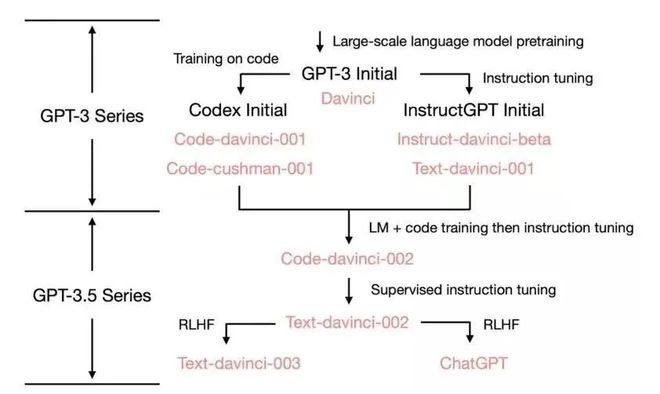
OpenAI text-davinci-003 模型,是所有模型里效果最接近 ChatGPT 的一个模型
该报告同时表示,对于全球科技大企业而言,百万至千万美元级别的训练成本虽然不便宜,但尚在可接受范围内。
“不算昂贵。”
单次成本大概率不是中国巨头们的考量。张俊林告诉盐财经,Open AI 最难得的是,它突破了长期以来 AI 届的思维惯性。
“以前没走训练大模型的路,完全是基于思维惯性。几十年来,AI 届的主流都在研究小模型,希望渐进式地实现突破和发展。”
问题不再于是否舍得投钱,而是取决于公司对通用人工智能的信心。
“不是说之前就没有大厂想过这条路。有很多人想过这条路,”张俊林说,“但是没有人(像 Open AI 一样)如此有决心发展 LLM。那时候,大家不知道这条路能不能走得通,也就不会不计回报地烧钱。”
这也就能解释,为何百度等中国巨头和研究机构,技术底子并不薄弱,投入的也足够多,但类 ChatGPT 的产品就是没率先在中国出现。这背后或许更多是路线选择和选择方法的差异。
黄民烈分析,就发展 ChatGPT 的底层技术而言,中国有很多团队和公司都有。“但在最终体现的系统能力上,我们有较大的差距。这里面有企业家精神、资本环境、人才、技术理念等多方面的因素,非常复杂。”
“比如大模型研究,我们是做一个项目,还是实现 AI 生成内容(AGI)的最终理想?”
“比如资本,我是为了短期逐利,还是坚持长期投入?”
这些差异都导向了“百度们”现今陷入奋起直追的被动结果。
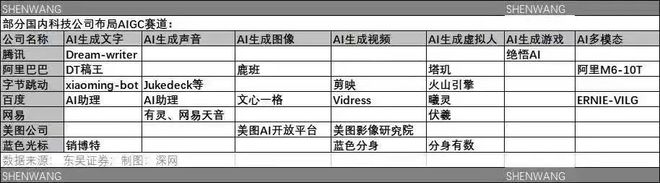
部分国内科技公司布局 AIGC 赛道
好消息是,ChatGPT 很大程度上依靠“大力出奇迹”的方法,靠着参数升级、反复训练和生成内容反馈持续迭代优化。反复投入、烧钱、迭代,这对中国公司并不陌生。
但坏消息是,留给“百度们”的时间不多了。
通用人工智能的技术迭代正在全球加速。刘知远说,虽然底层技术差别不大,但 AI 技术变革非常快。这一领域又对专利有要求,“国内外很多研究组都没那么快开展这方面研究。”
他认为,与 ChatGPT 有关的大模型以及背后技术,学界和业界都没有完全吃透。
张俊林分析,做第二个 ChatGPT 除了钱的门槛外,还有数据的阻碍。“中文数据相对英文数据还有太大差距。”他解释,由于互联网上英文占比最高,中文的高质量数据比英文相差很多。“要制作出一个相同能力的模型,在数据方面也有一定短板。”
而想做成类 ChatGPT 产品,刘知远认为,不止事关算法和底层技术。“数据、算力和人力的投入,可能都会是问题。这个领域本身需要有一个持续的投入,有一个量变,才能够产生质变。”
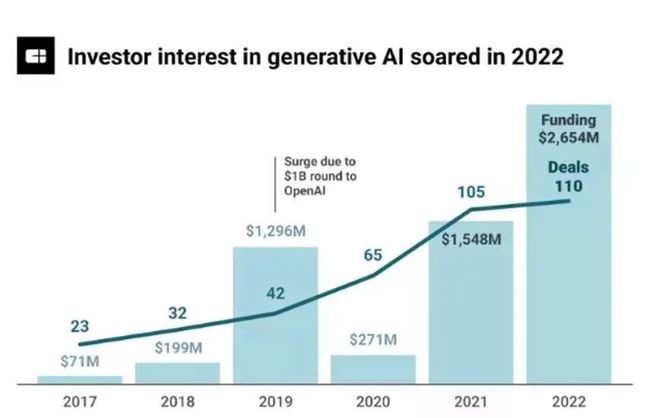
据调研机构 CB Insights 数据显示,2022 年有 110 笔创投交易和 AIGC 概念有关,投资金额超过 26 亿美元
他判断,中美科技公司的差距,保守估计1-2 年。
2023 年,席卷公众视野的 ChatGPT 无疑让众多中国科技公司拉响“红色警报”。如果这一波没有迎头赶上,技术的优势可能将造成结构性垄断和技术壁垒。到时候,再漂亮的讲故事能力,都无法掩盖技术的空心。
尽快做出叫好叫座的 ChatGPT 之余,黄民烈认为,国内科技公司的难点不在于什么时候推出中国版的 ChatGPT。
“而是在这股 AI 浪潮中,我们到底是否能够有深入的远见和创新性的想法,最终在人工智能时代迎面赶上,实现超越。”
盐财经,南风窗旗下唯一财经号关注它,看新鲜热辣的财经讯息。






