昨天,腾讯混元团队与复旦大学联合发布了全新的语言模型评测基准 CL-bench,并同步上线混元研究博客,系统阐述了当前前沿模型在「上下文学习」能力上的核心瓶颈。
值得注意的是。这是姚顺雨加入腾讯担任首席 AI 科学家后首次署名的研究成果。
研究指出,尽管当今顶级大模型在复杂推理、编程和专业考试中表现亮眼,但这些能力主要依赖预训练阶段形成的「参数化知识」。
在真实世界场景中,人类往往依赖即时出现的上下文信息完成任务,例如阅读从未见过的 SDK 文档、理解新游戏规则或从实验日志中归纳规律,而当前模型在这些任务上普遍表现不佳。
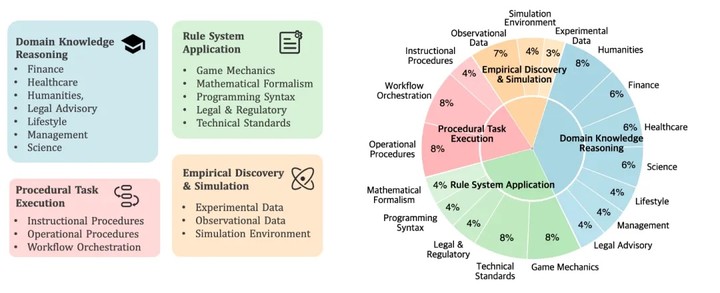
CL-bench 的目标正是衡量模型能否从提供的上下文中学习全新知识并正确应用。基准包含 500 个复杂上下文、1899 个任务和 31607 个验证标准,覆盖四类典型场景:领域知识推理、规则系统应用、程序性任务执行以及经验发现与模拟。
所有任务均为完全自包含,且通过虚构内容、小众知识和变体构造确保无训练数据污染。
实验结果显示,即便是表现最好的 GPT-5.1(High),在 CL-bench 上的任务解决率也仅为 23.7%,平均水平更是只有 17.2%。
研究团队指出,模型失败的主要原因并非信息缺失,而是忽略或误用上下文;长上下文处理和指令遵循虽重要,但不足以支撑真正的上下文学习;归纳推理尤其困难,任务成功率通常不足 10%。
研究还发现,提高推理强度在部分任务上能带来有限提升,但整体仍受限于模型无法有效吸收和组织上下文信息。此外,context 的难度不仅来自长度,也来自其结构复杂度和隐含规则。
腾讯混元团队认为,未来模型若能真正掌握上下文学习,人类在 AI 系统中的角色将从「训练数据提供者」转向「上下文提供者」。
但在当下,上下文学习仍是「临时性的」,如何让模型将从上下文中获得的知识持久化,将成为今年的重要研究方向。
团队强调,只有让上下文学习能力走向现实,语言模型才能迈向更高价值的应用场景。






