昨天,百度正式发布并开源新一代文档解析模型 PaddleOCR-VL-1.5。
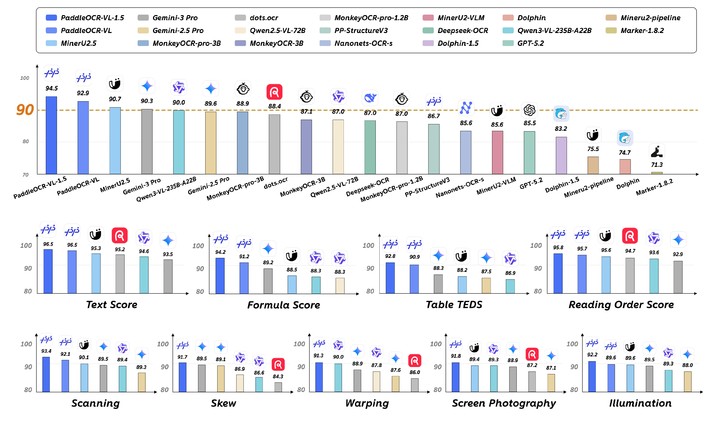
据介绍,该模型在全球权威文档解析评测榜单 OmniDocBench V1.5 中取得综合性能第一,整体精度达到 94.5%,超过 DeepSeek-OCR2、Gemini-3-Pro、Qwen3-VL-235B-A22B 以及 GPT-5.2 等主流模型。
PaddleOCR-VL-1.5 采用仅 0.9B 参数的轻量化架构,但在多项关键指标上实现领先。其中,表格结构理解得分为 92.8 分,阅读顺序预测得分为 95.8 分,均位列榜单第一。
百度表示,在文档阅读顺序预测任务中,该模型的版面逻辑解析错误率仅为同类模型的一半左右,在合同、财报等高复杂度文档场景中具备更高稳定性和可用性。
此次发布的另一核心突破在于「异形框定位」能力。百度称,这是全球首次在 OCR 模型中实现对倾斜、弯折、拍照畸变等非规则文档形态的稳定识别,使移动拍照、扫描件变形及复杂光照条件下的文档解析成功率显著提升。
该能力可应用于金融票据处理、档案数字化以及政务文档流转等真实业务场景。
在功能层面,PaddleOCR-VL-1.5 在上一代基础上进一步集成印章识别、文本检测与识别能力,并针对生僻字、古籍文献、多语种表格、下划线和复选框等复杂结构进行优化。
同时,模型新增对藏语、孟加拉语等语种的支持,并支持跨页表格自动合并与跨页段落标题识别,以缓解长文档解析中的结构断裂问题。
💻 GitHub: https://github.com/PaddlePaddle/PaddleOCR
🤗 Hugging Face: https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
👾 ModelScope: https://modelscope.cn/models/PaddlePaddle/PaddleOCR-VL-1.5






