
新智元报道
编辑:犀牛 KingHZ
超越主流商业模型!SkyReels-V3 在参考一致性、视频质量上碾压对手,构建 200 组测试基准,影视、电商、广告场景全覆盖,真正降维打击。
起猛了!
马斯克和孙悟空同框了。

更离谱的是:这种「真假难辨」的视频,现在一张图 + 几句话就能做出来。
不仅普通创作者能直接上手,而且开发者也能二次开发。
作为迭代自 V1(AI 短剧创作)、V2(无限时长电影生成)的重磅版本,昆仑天工 SkyworkAI 团队正式开源了多模态视频生成模型 SkyReels-V3:
论文:https://arxiv.org/abs/2601.17323
开源:https://github.com/SkyworkAI/SkyReels-V3
API 链接(限时免费):https://www.apifree.ai/model/skywork-ai/skyreels-v3/standard/single-avatar
这不仅仅是一个模型的发布,更像是一场对现有 AI 视频工具的「降维打击」。
AI 视频创作三大难事,
一次做全了
以前做 AI 视频,你需要在A模型生图、B模型动效、C模型对口型之间反复横跳。
而 SkyReels-V3 这次主打一个全能通吃,在一个架构里搞定三大核心能力:
1)参考图像转视频:给1–4 张图+文本指令,生成多主体视频。重点是: 主角不乱变,告别抽卡式创作。
2)视频延长:把 5 秒镜头扩到 30 秒,还能加转场。重点是: 画面连续、动作不「抽帧」。
3)音频驱动虚拟形象:一张肖像+一段音频,生成分钟级视频。重点是: 嘴型对得上、人物稳得住 。
AI 视频的门槛正在被铲平:创作者拿到的是趁手的工具,开发者拿到的是万能的模块。
参考图像转视频:主角就是主角
如果一个电商运营今晚就要把新品视频上架,但他现在手里只有三张图:商品主图、模特上身图、品牌 Logo。
传统做法?要么找外包烧钱,要么自己用剪辑软件硬搓。
SkyReels-V3 的玩法则是:1 到 4 张参考图+一句文本指令,等待几分钟,一条 15 秒的高保真产品广告就生成了。
直出一段多主体、高连贯的视频。
你可以这么下指令:
-
模特拿起商品转身展示,镜头从近景推到中景,背景保持干净明亮。
-
Logo 始终在右下角,商品纹理要清晰,动作别抽搐。
它要解决的不是「会动」,而是更难的事:「像同一个人、同一个商品、在同一个世界里连续发生」。
在 SkyReels-V3 眼里,参考图像不再只是灵感,而是一份「身份合同」——主角签了字,就别想临场变脸。
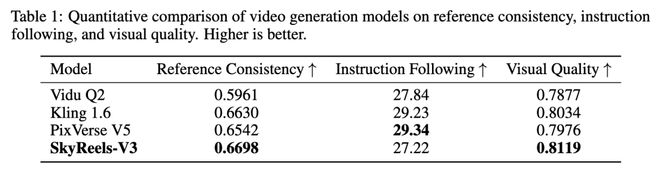
其参考一致性得分高达0. 6698,视觉质量0. 8119,这两个核心指标,直接超越了市面上的主流商业模型。
比如,让马斯克免费给你带货,或者生成一段极具质感的运动鞋广告:
没有任何诡异的形变,只有丝滑的商业级质感。
1 简洁明亮的展区内,柔和的灯光均匀洒落,周围摆放着一些运动相关的小物件。一位身穿黑色上衣的男士正仔细地向大家展示一双设计简洁、配色亮丽的运动鞋。
之前,Gemini 3 生成的硅谷巨头大合照,很火很逼真:

现在,SkyReel-V3 直接让图片动起来了──
这质量,这还原度,这一致性,真不是吹!
视频延长:5 秒变 30 秒, AI 学会了「导演思维」
做过视频的人都知道,视频延长是个技术活。
你有一个 5 秒的空镜头,氛围很好,但太短了。
传统做法要么重拍,要么靠后期「魔法」——变速、复制帧、加特效遮掩,但怎么弄都有点假。
SkyReels-V3 的视频延长功能,不仅可以把 5 秒的素材平滑扩展到30 秒,更绝的是,它「懂镜头语言」。
它内置了5 种专业转场效果:切入、切出、多角度切换、正反镜头、切离。
比如,第一个视频延长到 15 秒:
你不只是在「拉长」视频,而是在即时即兴剪辑。
比如,将一段小姐姐骑车的 3 秒视频延长到 9 秒:

视频延展后,无论小姐姐的主体还是视频背景,都完美保持一致,仿佛摄影师真的扛着摄像机跟拍了一路。

再比如,我们将这个林妹妹与鲁智深对话的脑洞视频,加入「多角度切换」的转场。

The two people sat facing each other and talked.
这种人物一致性,简直绝了。

Switch to a long shot, with the two people talking face to face.
从技术上说,这得益于它的「统一多分段位置编码」和「鲁棒时空建模」。
听起来很硬核,本质上就是让 AI 理解了视频里的「时间逻辑」和「空间关系」,所以延长出来的内容才会顺滑如丝,没有那种 AI 常见的时空扭曲感。
一句话:SkyReels-V3 把素材不足从一场灾难,变成了一个可控的工程问题。
音频驱动虚拟形象:一张图+一段声就能「开口说话」
这是 SkyReels-V3 最让人兴奋的能力之一。
输入一张人像照片,再配上一段音频——
可以是你的录音,可以是 AI 合成的语音,甚至可以是一段采访素材。
模型会生成一段视频,让照片里的人瞬间「活过来」:
嘴唇动作和音频精准同步,表情自然变化,头部还有轻微的摆动,仿佛真人在镜头前呼吸。
比如,一张小姐姐的图片加上一小段音频,就能生成小姐姐唱歌的片段。
最厉害的是,它不挑食。
不只是真人照片,卡通角色、动物形象、二次元立绘,统统可以驱动。
比如,使用一张小狗照片+一段音频,就可以一步生成「小狗深情演唱」的视频,时长甚至支持分钟级生成。
你甚至可以让两个角色在同一个画面里对话。
只需上传一张图片加上几段音频,SkyReels-V3 便能够自行判断出音频对应的人物,在说话和聆听状态之间自然切换。
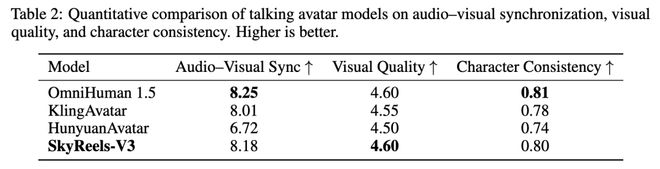
SkyReels-V3 这项能力的音视频同步性得分高达 8.18,视觉质量 4.60,比肩甚至超越了行业顶尖的 OmniHuman 1.5。
为什么是 SkyReels-V3?
领先三大维度
在 AI 视频生成领域,「全能选手」向来稀缺。
SkyReels-V3 的出现,打破了这一格局——它是目前少数能在单一架构内同时实现参考图像生成视频、视频延展、音频驱动虚拟人三大核心能力的模型。
SkyReels-V3 敢称行业标杆,底气何在?
在最考验硬实力的参考图像转视频领域,SkyReels 研究团队构建了一个包含 200 组测试数据的评估基准,涵盖影视、电商、广告等多元场景,参考图像类型覆盖人物、动物、物体和背景。
结果显示,在参考一致性、视频质量这两个核心指标上,SkyReels-V3 直接超越了市面上的主流商业模型。
作为一个开源模型,这是对闭源阵营的一次强力挑战。
视频延展是 SkyReels-V3 的另一大杀手锏。
为实现这一能力,研究团队开发了镜头切换检测器,可分析长视频中是否存在转场及其类型。
配合统一的多片段位置编码和分层数据训练,模型能够精准建模运动轨迹,在复杂的多片段视频延展中实现平滑过渡。
输出支持 720p 分辨率,单镜头延展时长可达 30 秒,支持1:1、3:4、4:3、16:9、9:16 等多种画幅比例。
在音频驱动虚拟形象生成领域,SkyReels-V3 同样表现亮眼。
音视频同步性得分 8.18,视觉质量 4.60。这些数据比肩甚至在部分指标上超越了行业顶尖的 OmniHuman 1.5。
虚拟形象生成的难点在于唇形同步和长时序稳定性。
SkyReels-V3 支持 720p、24fps 的高清视频输出,唇部动作能够精准对齐音素级别的音频动态。
更关键的是,它支持分钟级视频的单次生成——不是靠多段拼接,而是一次性前向推理完成,全程保持身份一致、动作连贯、表情稳定。这使它天然适用于教学视频、新闻播报、长篇故事等场景。
值得一提的是,SkyReels-V3 还支持多人场景。
在对话场景中,角色能够正确响应对话音频,在说话和聆听状态之间自然切换。
SkyReels-V3 是真开源
市面上做 AI 视频生成的模型不少,但 SkyReels-V3 是真开源。
很多所谓的「开源」模型,要么只开放部分权重,要么限制商用,要么文档稀烂根本跑不起来。
SkyReels-V3 是完整开源,代码托管在 GitHub,支持个人和企业自由下载、本地部署、定制改造。
对于中小团队来说,这意味着零成本获得顶级AI视频能力的可能。无需支付高昂的 API 调用费用,无需担心数据隐私问题,完全可以在自己的服务器上跑通全流程。
如果你是开发者:你要的可能不是「看 Demo」,而是把能力接进流程。
把 SkyReels-V3 当成一个模块,接到你的脚本生成、素材管理、投放系统里——这就是开源生态的意义。
最后,真正能把开源模型做成「生态」的,从来不是发布那一刻,而是你把作品发出来的那一刻。
下载、跑通、生成第一条视频,然后把你的 prompt 和结果分享出来——
让更多人站在你的肩膀上继续迭代。
视频创作的「奇点」时刻
从 V1 的短剧尝试,到 V2 的电影梦想,再到今天 V3 的全能爆发,SkyworkAI 团队正在用技术填平专业视频制作的沟壑。
SkyReels-V3 的出现,标志着高保真、长时长、多模态的视频生成能力正式从「尝鲜」走向「实用」。它把原本属于专业工作室的权利,交还给了每一个有故事要讲的人。
在 AI 的辅助下,未来的斯皮尔伯格可能就诞生在你的代码仓库里。
工具已经备好,现在,请开始你的表演。






