
新智元报道
编辑:定慧
谷歌 Google DeepMind 刚刚推出新能力,用代码赋予 Gemini 3 Flash「法眼」。
没想到吧,Google DeepMind 刚刚为 Gemini 3 Flash 推出了一个重量级新能力:Agentic Vision(智能体视觉)。(难道是被 DeepSeek-OCR2 给刺激到了?)
可以看到,这项技术彻底改变了大语言模型理解世界的方式:
从过去的「猜」变成了如今的「深度调查」。

该能力由 Google DeepMind 团队推出,核心产品经理 Rohan Doshi 表示,传统的 AI 模型在处理图片时,往往只是静态地看一眼。
如果图片里的细节太小,比如微处理芯片上的序列号或者远处模糊的路牌,模型往往只能靠「猜」。
而 Agentic Vision 引入了一个「思考-行动-观察」(Think-Act-Observe)的闭环:
模型不再是被动接收像素,而是会根据用户的需求,主动编写 Python 代码来操纵图像。
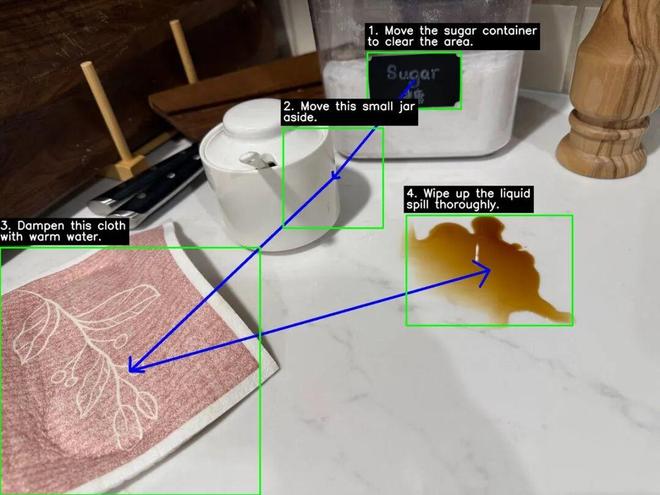
这一能力直接让 Gemini 3 Flash 在各类视觉基准测试中实现了5% 到 10% 的性能跨越。
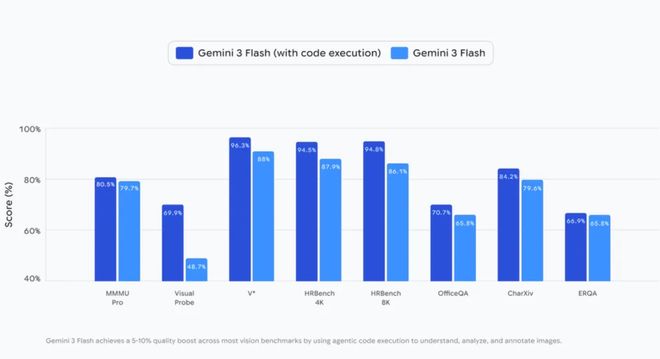
Agentic Vision:智能体视觉新前沿
DeepMind 探索的方法概括起来就是:利用代码执行作为视觉推理的工具,将被动的视觉理解转化为主动的智能体过程。
什么意思呢?我们知道,目前的 SOTA 模型通常是一次性处理图像。
但 Agentic Vision 引入了一个循环:
1. 思考(Think):模型分析用户查询和初始图像,制定多步计划。
2. 行动(Act):模型生成并执行 Python 代码来主动操纵图像(如裁剪、旋转、标注)或分析图像(如运行计算、计数边界框等)。
3. 观察(Observe):变换后的图像被追加到模型的上下文窗口中。这允许模型在生成最终响应之前,以更好的上下文检查新数据。
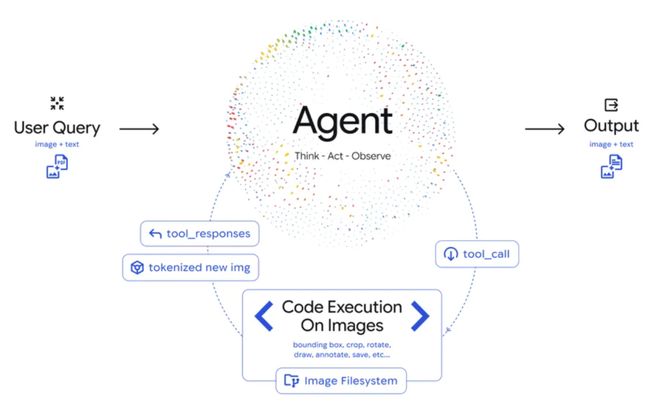
Agentic Vision 实战
通过在 API 中启用代码执行,开发者可以解锁许多新行为。
Google AI Studio 中的演示应用已经展示了这一点。
1. 缩放与检查(Zooming and inspecting)
Gemini 3 Flash 被训练为在检测到细粒度细节时进行隐式缩放。
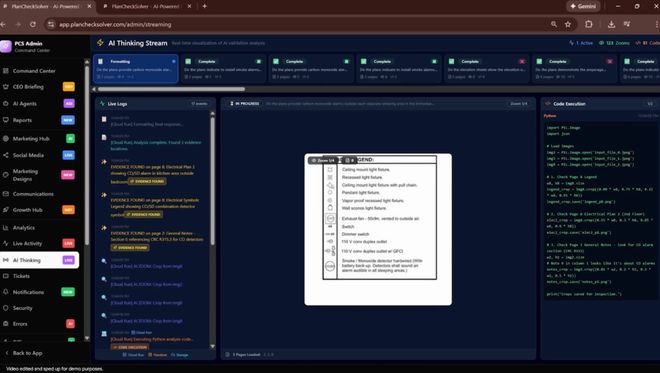
PlanCheckSolver.com 是一个 AI 驱动的建筑计划验证平台,通过启用 Gemini 3 Flash 的代码执行功能来迭代检查高分辨率输入,将准确率提高了5%。
后台日志视频展示了这个智能体过程:Gemini 3 Flash 生成 Python 代码来裁剪和分析特定的补丁(例如屋顶边缘或建筑部分)作为新图像。
通过将这些裁剪图追加回其上下文窗口,模型在视觉上确立其推理,以确认是否符合复杂的建筑规范。
2. 图像标注(Image annotation)
Agentic Vision 允许模型通过标注图像与环境交互。
Gemini 3 Flash 不仅仅是描述它看到的内容,还可以执行代码直接在画布上绘制以确立其推理。
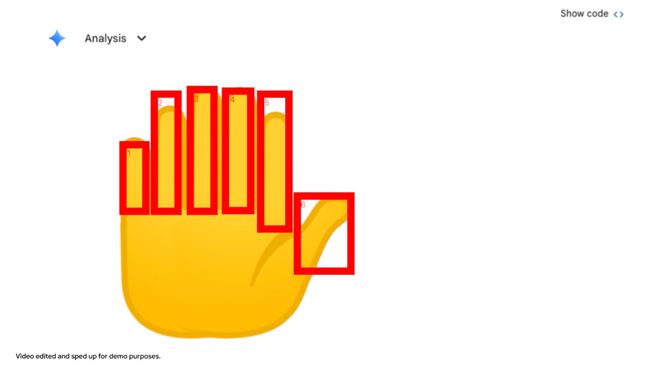
在下面的例子中,模型被要求数 Gemini 应用中一只手上的数字。
为了避免计数错误,它使用 Python 在它识别的每个手指上绘制边界框和数字标签。
这种「视觉草稿纸」确保其最终答案是基于像素级的完美理解。
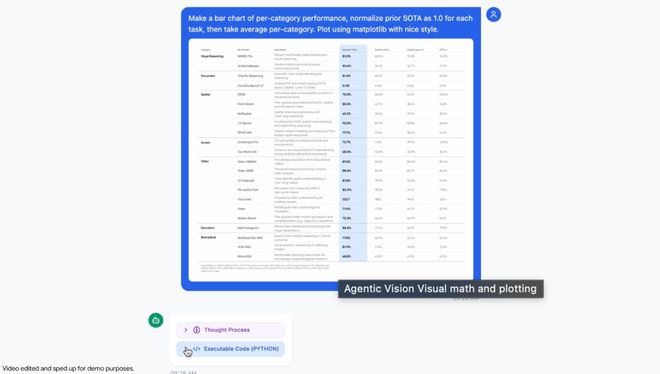
3. 视觉数学与绘图(Visual math and plotting)
Agentic Vision 可以解析高密度表格并执行 Python 代码来可视化发现。
标准 LLM 在多步视觉算术中经常产生幻觉。
Gemini 3 Flash 通过将计算放到到确定性的 Python 环境中来绕过这个问题。
在 Google AI Studio 的演示应用示例中,模型识别原始数据,编写代码将之前的 SOTA 归一化为 1.0,并生成专业的 Matplotlib 条形图。这用可验证的执行取代了概率性猜测。
如何上手
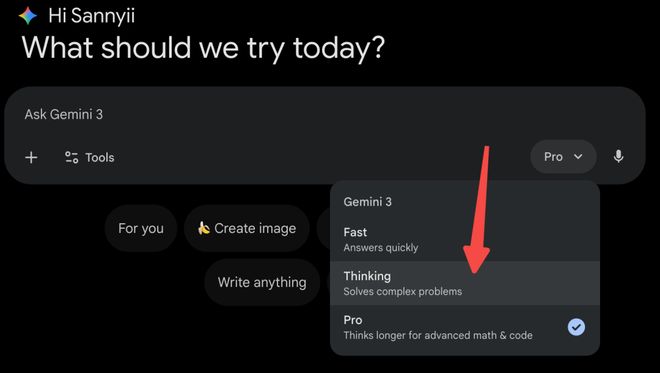
Agentic Vision 今天已通过 Google AI Studio 和 Vertex AI 中的 Gemini API 提供。
它也开始在 Gemini 应用中推出(通过从模型下拉菜单中选择 Thinking 访问)。
以下是一个简单的 Python 代码示例,展示了如何调用这一能力:
print (response.text)未来展望
Google 表示,Agentic Vision 才刚刚开始。
目前,Gemini 3 Flash 擅长隐式决定何时放大微小细节。虽然其他功能(如旋转图像或执行视觉数学)目前需要显式的提示引导来触发,但 Google 正在努力在未来的更新中使这些行为完全隐式化。
此外,Google 还在探索如何为 Gemini 模型通过更多工具(包括网络和反向图像搜索)来进一步确立其对世界的理解,并计划将此功能扩展到 Flash 以外的其他模型尺寸。
彩蛋:难道是因为 DeepSeek?
这就很有意思了。
DeepSeek 前脚刚开源了堪称「OCR 2.0」的 DeepSeek-OCR,谷歌后脚就发布了 Gemini 3 的 Agentic Vision。
这真的是巧合吗?
我们不妨大胆猜测,谷歌这次的「深夜炸场」,极有可能是被 DeepSeek 逼出来的。
理由有三:
1. 时间点的惊人巧合
1 月 27 日,DeepSeek 刚刚发布了 DeepSeek-OCR2,搭载核心黑科技DeepEncoder V2。它抛弃了传统的机械扫描,让 AI 学会了像人类一样「按逻辑顺序阅读」,仅用几百个 Token 就实现了对复杂排版和图表的完美理解。
谷歌同一天立马拿出 Agentic Vision,仿佛在这场「视觉军备竞赛」中隔空喊话:「你们让 AI 看懂逻辑,我们直接让 AI 上手操作」。
2. 技术路线的巅峰对决
DeepSeek-OCR2 走的是「内功流」,通过 DeepEncoder V2 模拟人类的视觉注意力机制,动态重组图像信息,把「看」这个动作做到了极致的轻量化和逻辑化。
而谷歌的 Agentic Vision 走的是「外设流」,也就是「不光要看清,还要能动手」。DeepSeek 在教 AI 怎么「用心看」,谷歌在教 AI 怎么「用手算」。
3. 争夺视觉AI定义的终局
DeepSeek-OCR2 证明了即便是 3B 的小模型,只要「视觉逻辑」对路,也能吊打大模型。谷歌则试图用「代码执行」来降维打击:你视觉再好也是「看」,我能写代码验证才是「真懂」。
这场仗,本质上是谁能重新定义「机器视觉」——是极致的感知,还是全能的交互?
不管是不是「应激反应」,这场神仙打架,最后爽的还是我们程序员。
参考资料:






