
新智元报道
编辑:KingHZ 好困
ICLR 2026 投稿破纪录达 19000 篇,录用率仅 28.18%,平均分 5.39 创三年最低。评审系统漏洞曝光之后,作者们仍晒出喜报,如北大张铭组中 5 篇,庆祝努力收获。
放榜了!
顶会 ICLR,在评审员和作者互相开盒之后,录用结果来了。
ICLR 2026 可谓「一片混乱」:先是评审结果惹争议,多名投稿人经历投稿分数全0;后有评审系统被爆出漏洞,审稿人全员裸奔。
终于,ICLR 2026 带来了一线希望,录用通知从 1 月 25 日发出——
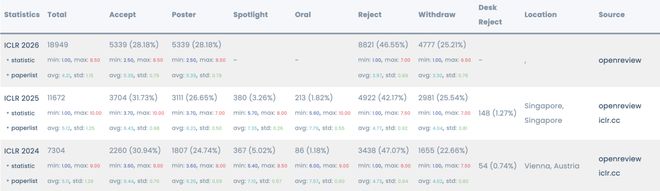
据 Paper Copilot 统计,ICLR 2026 总投稿论文再创新高,为 19000 篇;录用率只有 28.18%,对应的平均得分为 5.39、最低分为 2.50、最高分为 8.50,均为最近三年最低水平;Poster 录用率为 28.18%,为最近 3 年新高。
投中的作者发帖庆祝,苦尽甘来,努力终有收获,但并非没有争议,特别是关于 LLM 滥用的争议。
顺便提一句,本届 ICLR 将于 2026 年 4 月 23 日至 27 日在巴西里约热内卢举行。

网友纷纷晒出成绩单
多名作者在国内外社交平台发文,祝贺 ICLR 2026 喜创佳绩。
我们先看一下国内平台上大家晒出的「成绩单」。
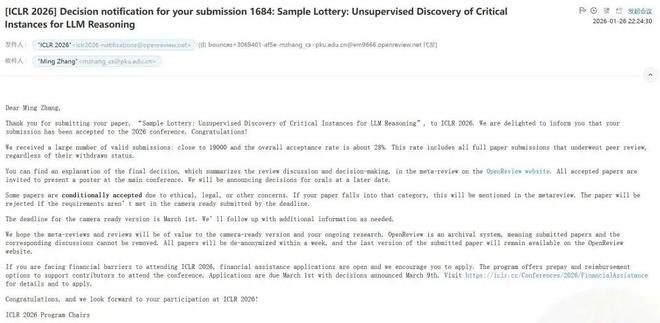
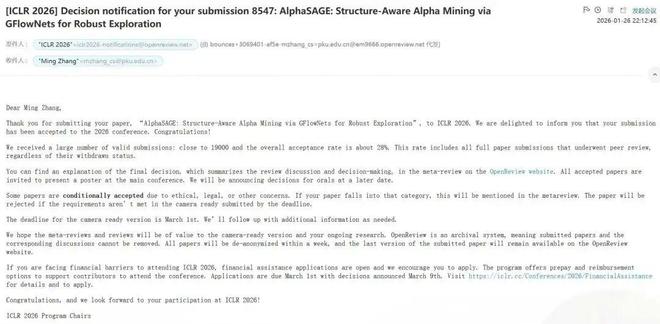
北大张铭教授组顶会 ICLR 中 5 篇:
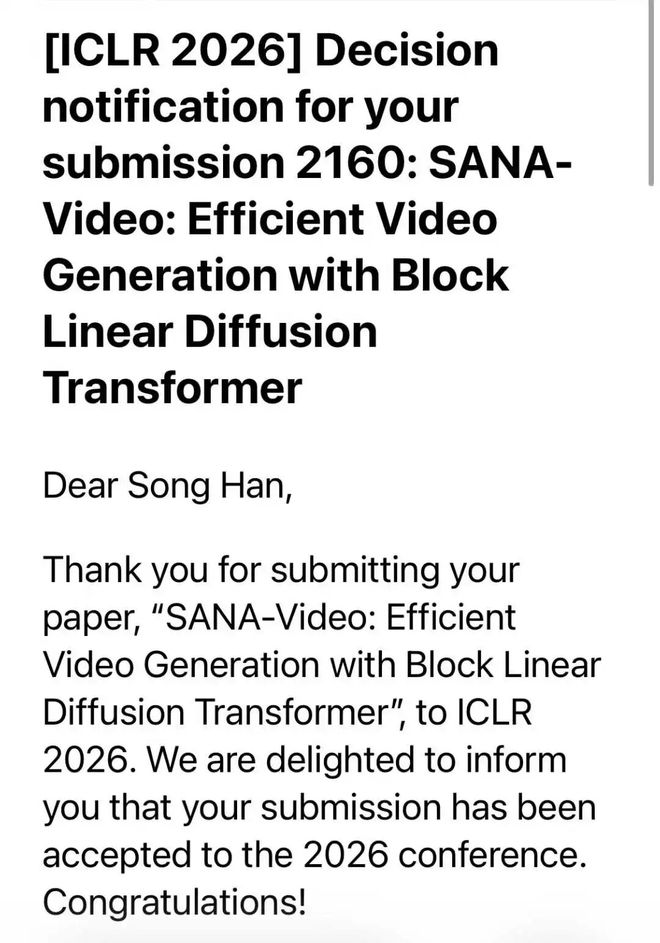
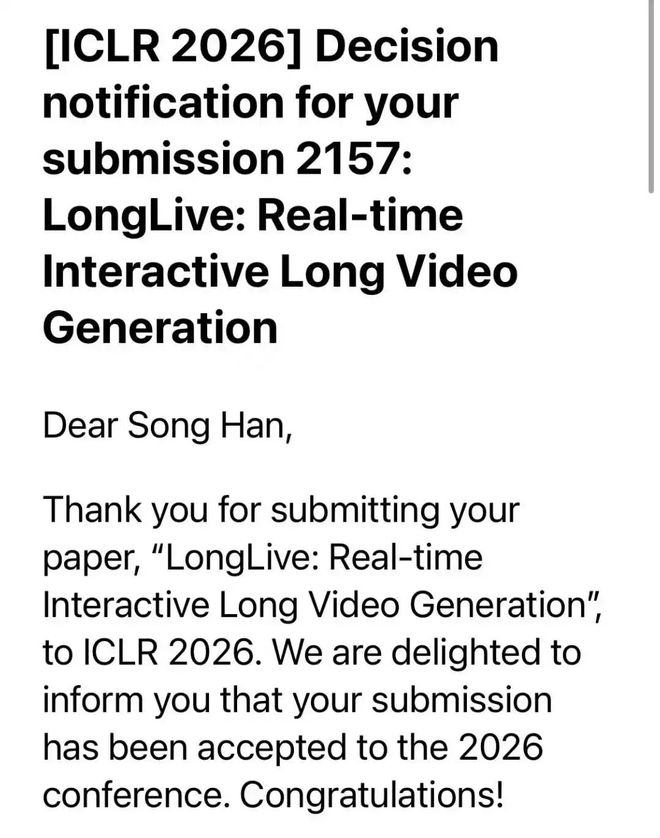
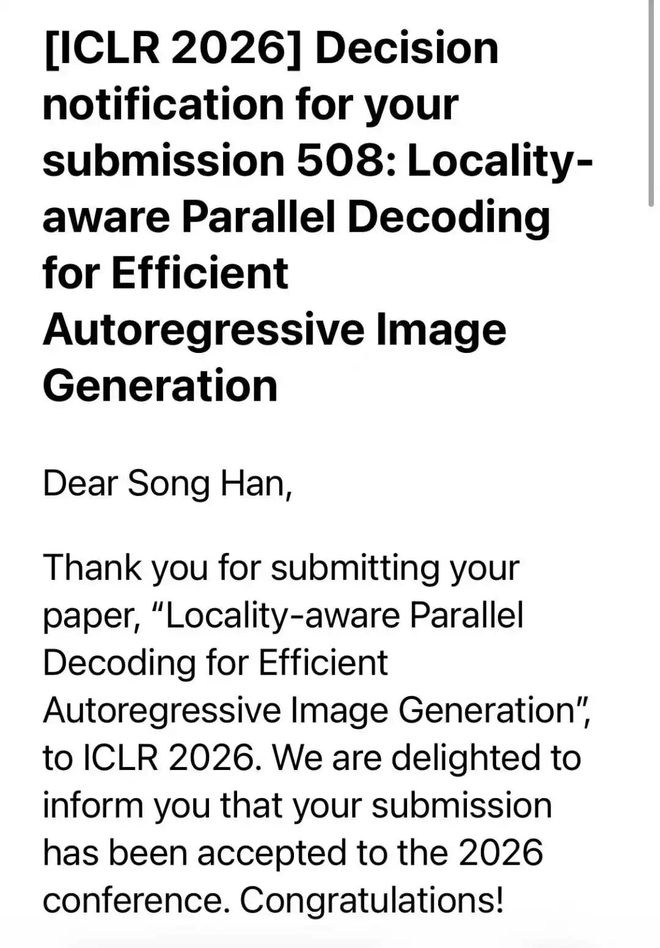
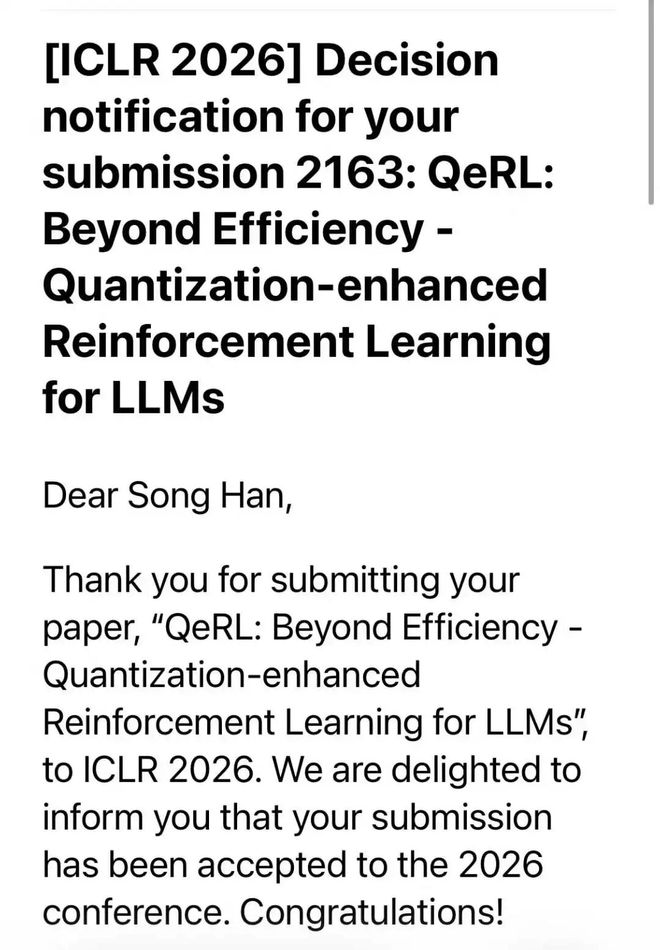
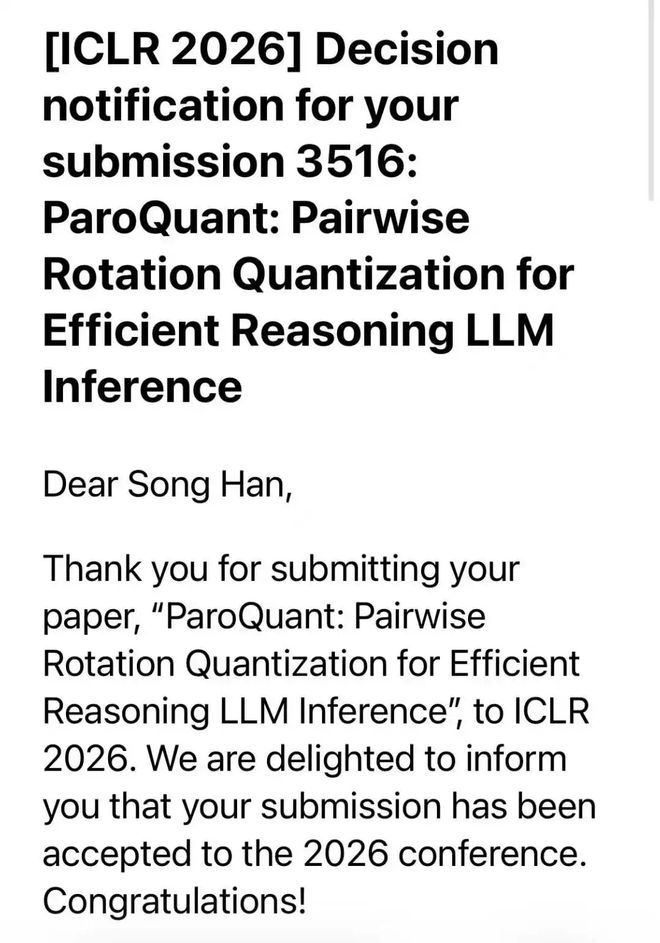
MIT 教授、清华校友韩松投稿 ICLR 的第十年,联合战队生产力大爆发,投中至少 9 篇:


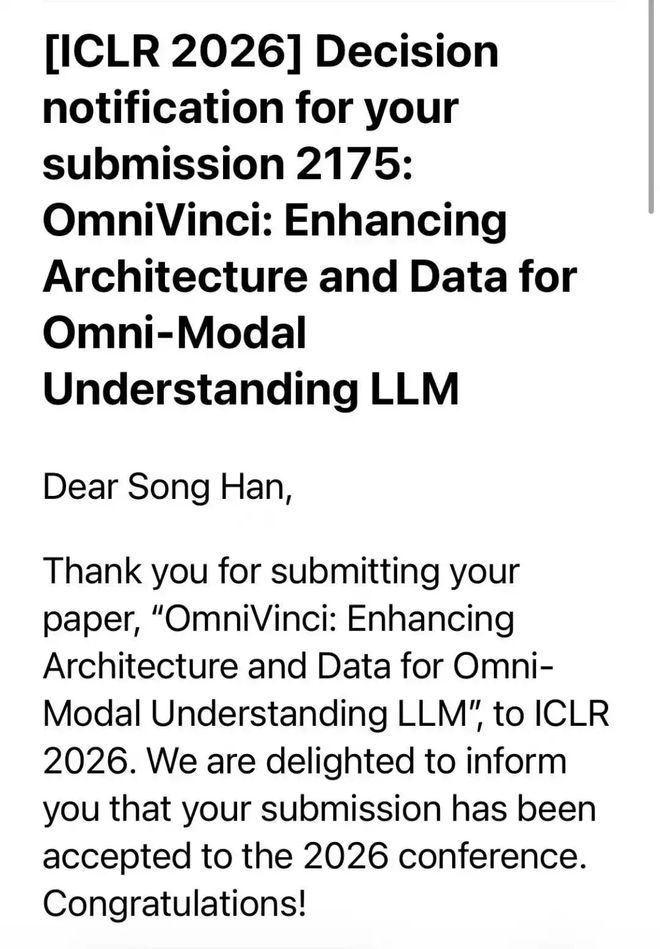
TAMU 计算机系助理教授涂正中,喜提 5 篇 ICLR。
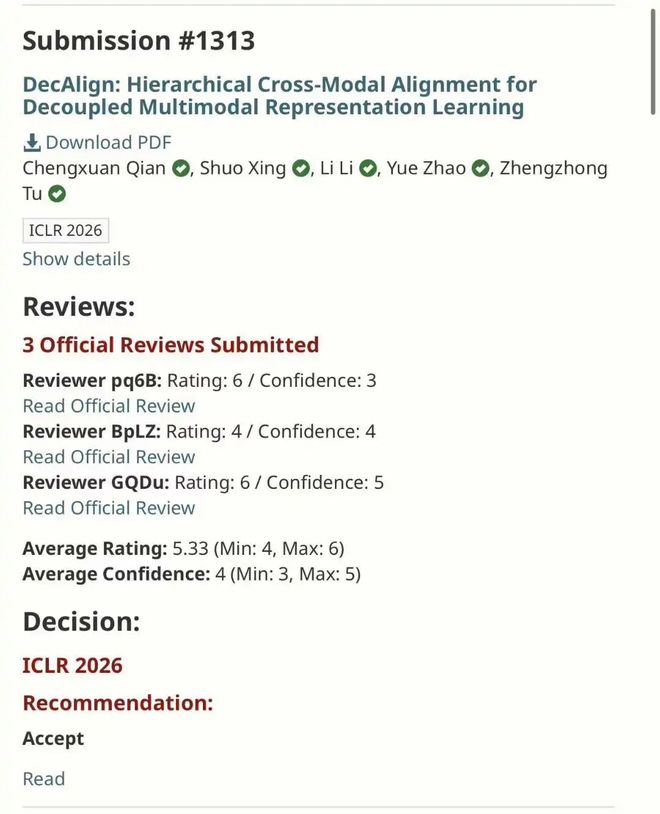
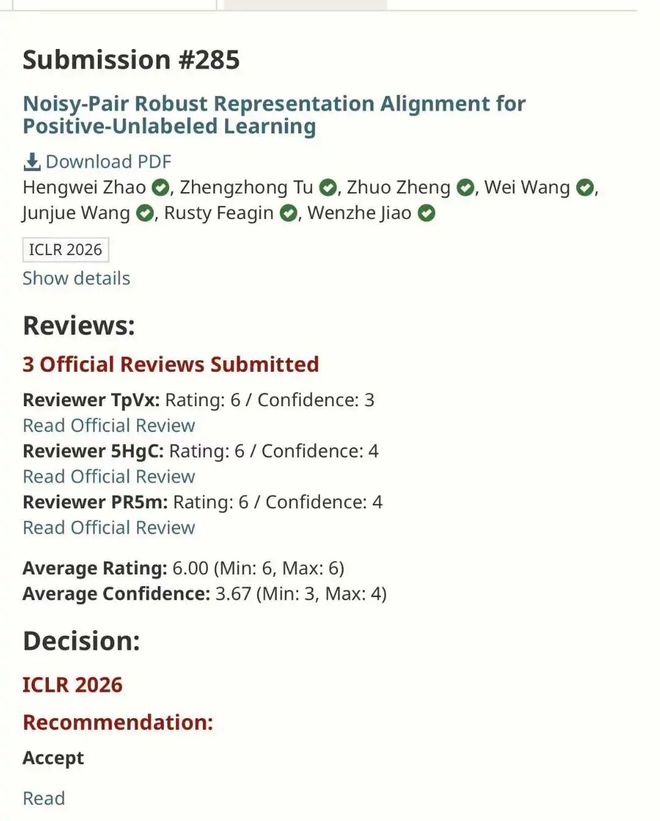
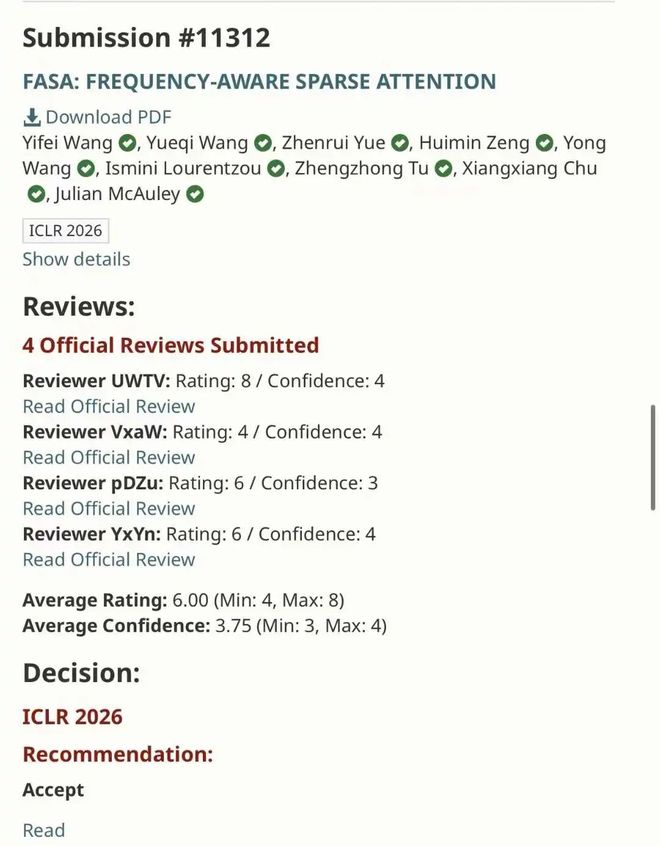

港科大田泽越 ICLR+4:
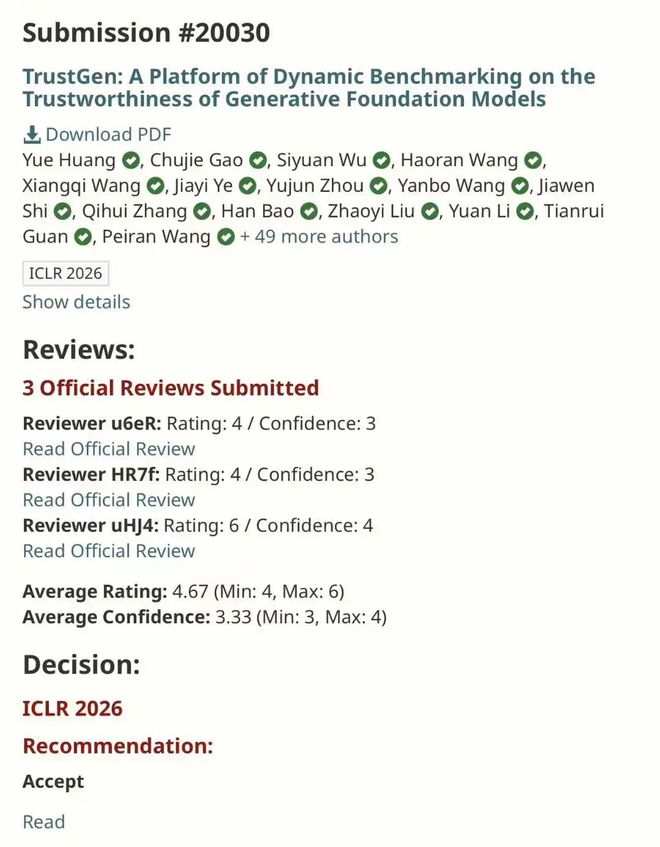
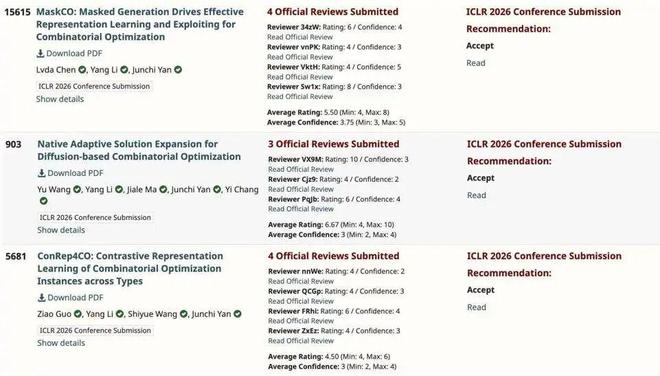
上海交通大学郦洋和团队投中 3 篇:
1. 基于掩码生成的类自监督学习范式 MaskCO,在 TSP 上相比 SOTA 实现了超过 99% 的 gap 缩减,并带来 10 倍的加速。
2. 面向组合优化的掩码扩散框架 NEXCO,将解的解码过程内化为扩散模型的原生机制,在保证约束满足的同时显著提升解的质量与推理效率。
3. 面向组合优化问题的统一表示学习框架 ConRep4CO,实现跨问题的预训练,显著提升表示质量、泛化能力及下游优化性能。
南洋理工加小俊和团队取得了优异成果。
据介绍,本次他参与了三篇 ICLR 2026 论文,其中一篇是共同一作,两篇是通讯作者,分别聚焦 LLM 安全对齐 / 多模态越狱安全评测 /文言文越狱攻击等方向。
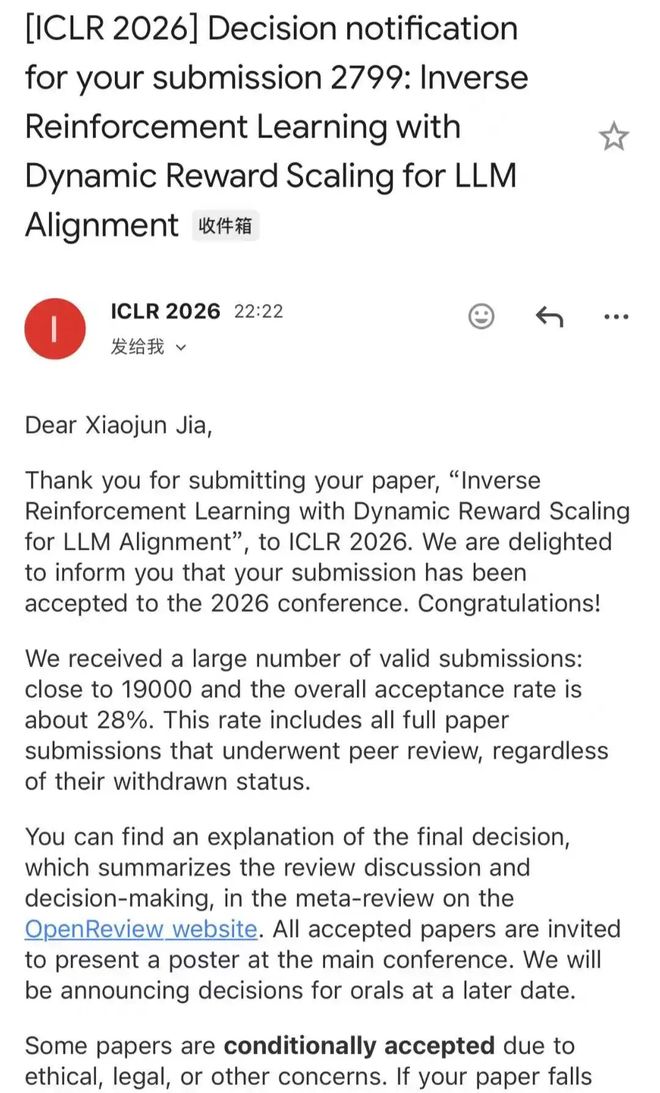
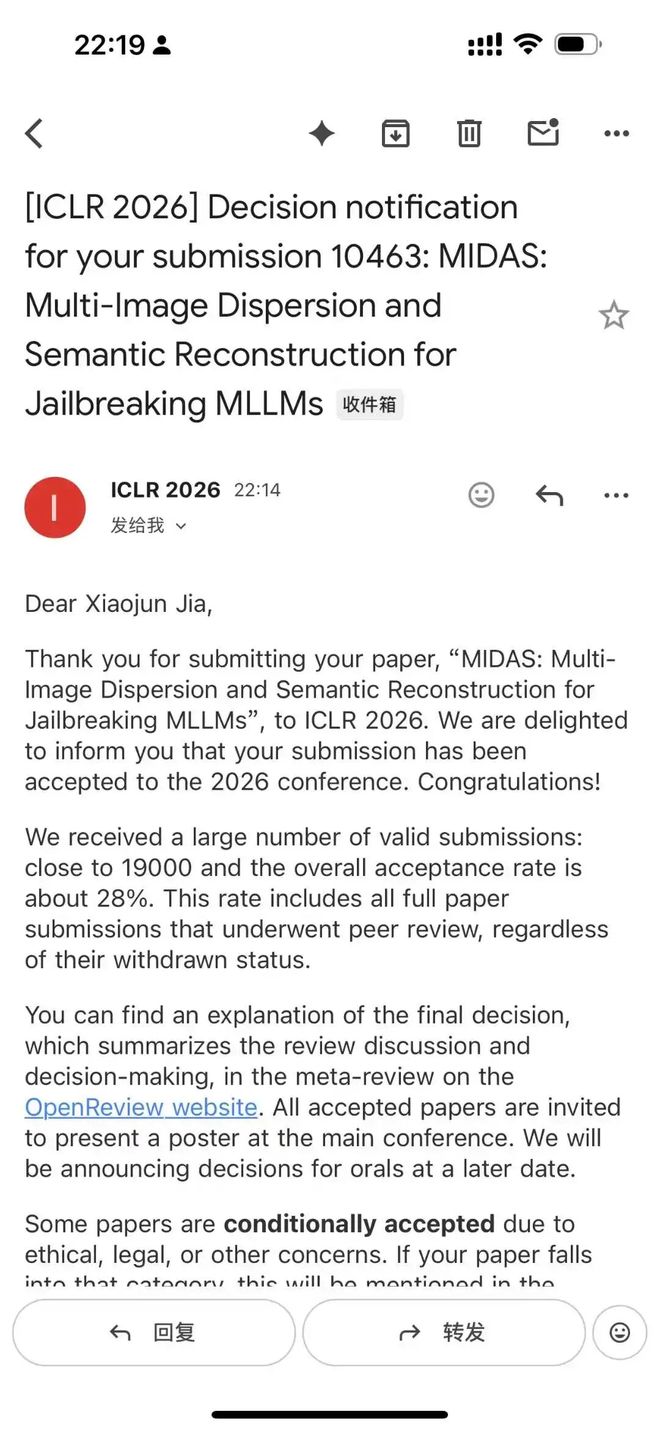
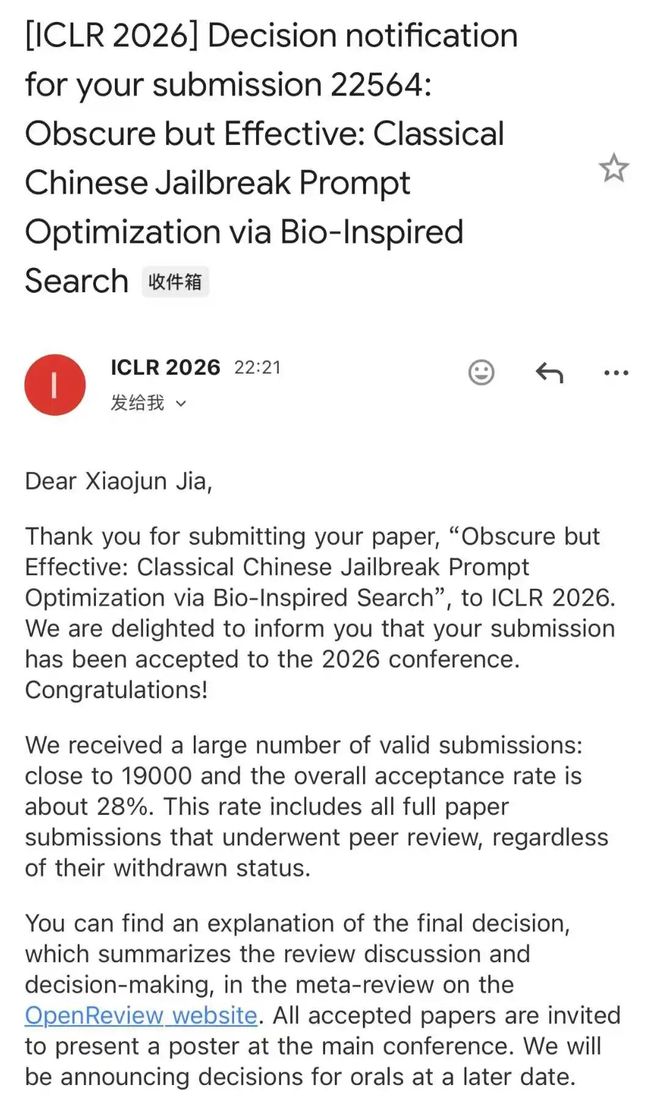
清华在读博士生李凯的两篇一作论文顺利拿下「双杀」,并且还把 Paper、Code 和 Dataset 全都开源了。
Work 1: Dolphin 高效音视频语音分离,小海豚游得快!
Paper:https://huggingface.co/papers/2509.23610
Space: https://huggingface.co/spaces/JusperLee/Dolphin
Work 2: AudioTrust Audio LLM 的可信度评估 Benchmark。
Paper: https://huggingface.co/papers/2505.16211
Dataset: https://huggingface.co/datasets/JusperLee/AudioTrust


中科大梁锡泽 ICLR+2,方向包含大模型多领域 RL、大小模型协同推理。
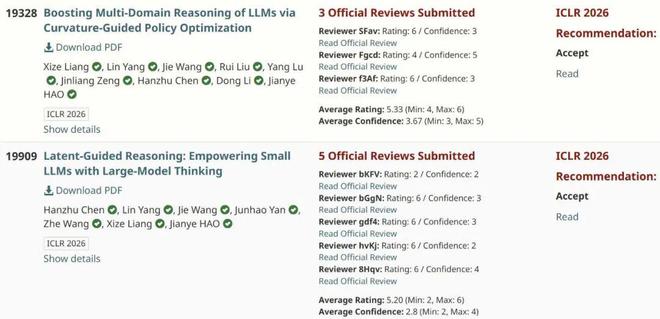
多领域 RL 方面,他们提出了 RLCGPO 算法,在数学、代码、科学、创意写作 4 个领域的 7 个基准上取得平均 +2.3 分提升,并带来更快的奖励增长(例如训练 50 步后奖励提升达到基线的2–3 倍);同时每步额外开销仅2–5%。
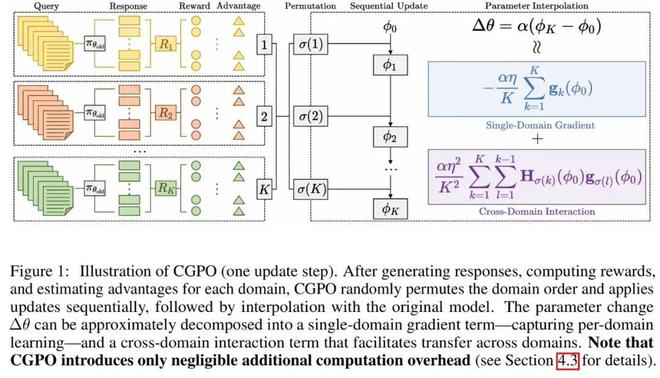
在大小模型协同推理领域,他们提出了 Latent Guidence 框架,使小模型相较其独立基线的准确率最高提升 13.9%、速度提升 2 倍,同时整体推理速度比大模型快至 4 倍。
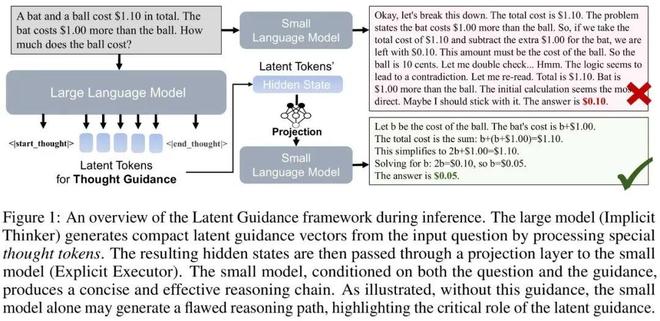
华师大王嘉宁,同样 ICLR+2:
R-Horizon:大模型长程推理分析与 RL 优化
ScienceBoard:面向 AI for Science 的 Agentic 工作流评估
港科大(广州)宋文轩,作为共一和 project lead 参与的两篇 VLA 文章都接收了,分别代表了两条路线上的探索(VLA 的视觉表征学习和 diffusionVLA),两篇工作均已开源(均 Github 100+ stars)
Spatial Forcing: https://spatial-forcing.github.io/
Unified Diffusion VLA:https://arxiv.org/abs/2511.01718

英伟达谢恩泽,参与的 SANA Video 和 Fast dLLM 系列都中了 ICLR 2026!
在线性注意力应用于 Diffusion 视觉生成的基础之上,这次他们在 Diffusion LLM 语言模型上的研究也取得了一些不错的进展。
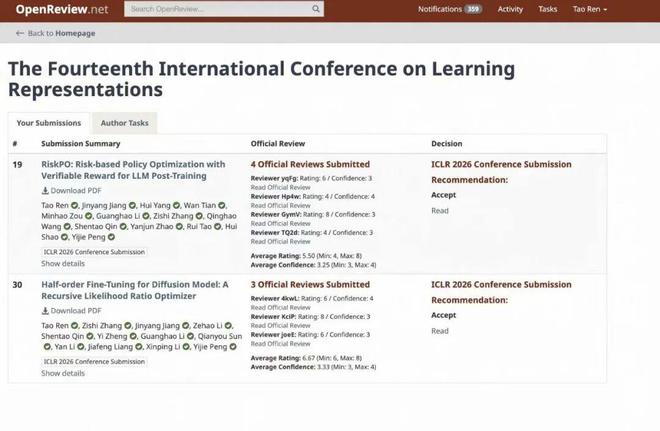
北大任韬,ICLR 2026 投中两篇论文,聚焦于 LLM 和 Diffusion 的后训练强化学习算法,从风险度量和随机梯度估计的角度给出了一些不同的看法。
港科大(广州)陈晋泰,关于「心电全景图(Electrocardio Panorama)」的 Nef-Net v2 正式被录用。
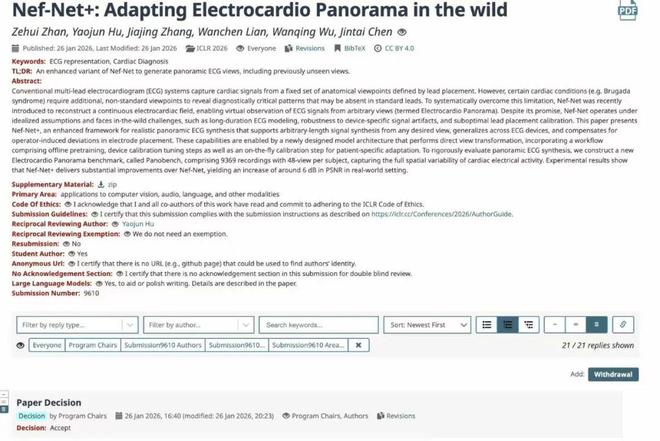
v2 版本已经实现了对任意时长、任意心电设备的覆盖,效果已经远超初代。他认为更重要的是落地:
发论文从来不是目的,现在如果目标仅仅是发一篇顶会并不难。真正的意义在于我们将心电全景图的应用向临床又推进了一大步。我们的 v3 已经在路上。
复旦仝竞奇等在被接收的工作中,发现游戏任务训练可以提升 AI 的通用推理能力。
论文链接:https://arxiv.org/abs/2505.13886
代码仓库:https://github.com/tongjingqi/Game-RL
数据与模型:https://huggingface.co/datasets/Code2Logic/GameQA-140K


国外社交平台上,也很热闹。
被誉为诺奖风向标之一的斯隆研究奖得主、OSU 教授 Yu Su 实验室中了 11 篇,激动发帖:「OSU NLP Group 中了 11 篇,涉及智能体记忆、安全、评估、机制解释性以及面向科学的 AI 等话题。」

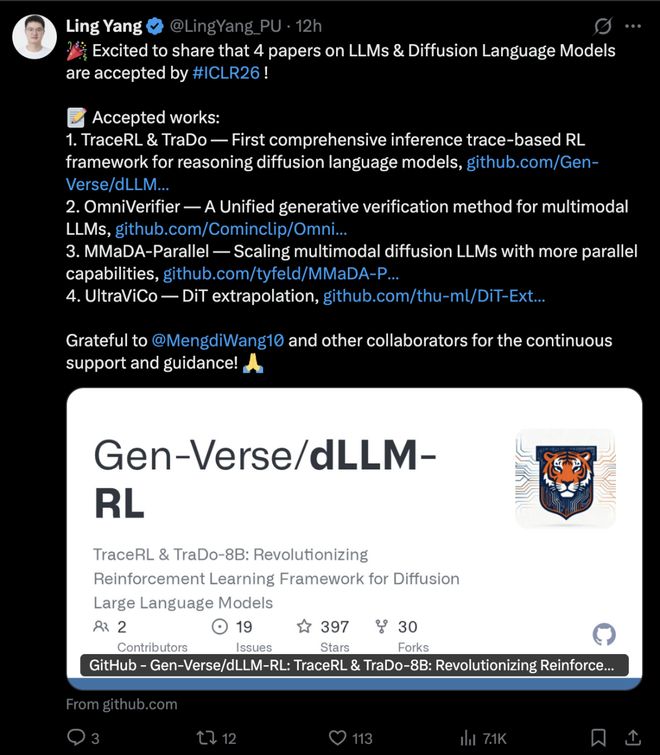
与合作者一起,普林斯顿的博士后 LingYang,在「大模型和扩散语音模型上」上一人中了 4 篇:
香港中文大学博士后 Yafu Li,投中了 6 篇,而且全部开源,对推理、强化学习和多模态理解可以看看。

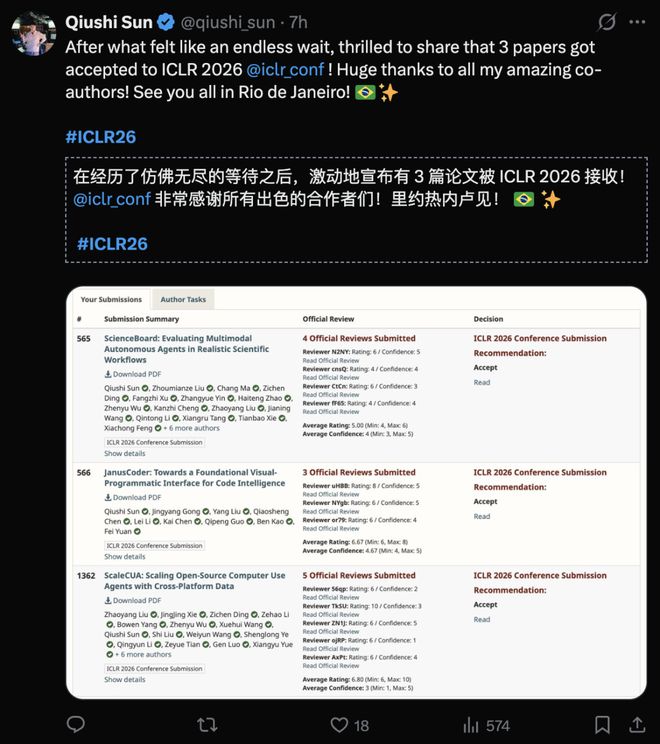
在读博士 Qiushi Sun 参与的 3 篇论文被 ICLR 2026 接收。
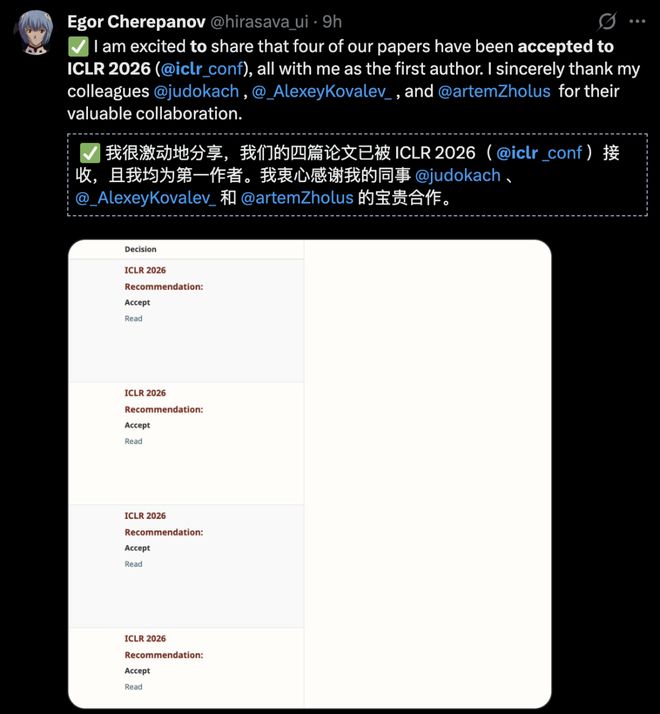
作为第一作者,网友 Egor Cherepanov 有 4 篇论文被接收。
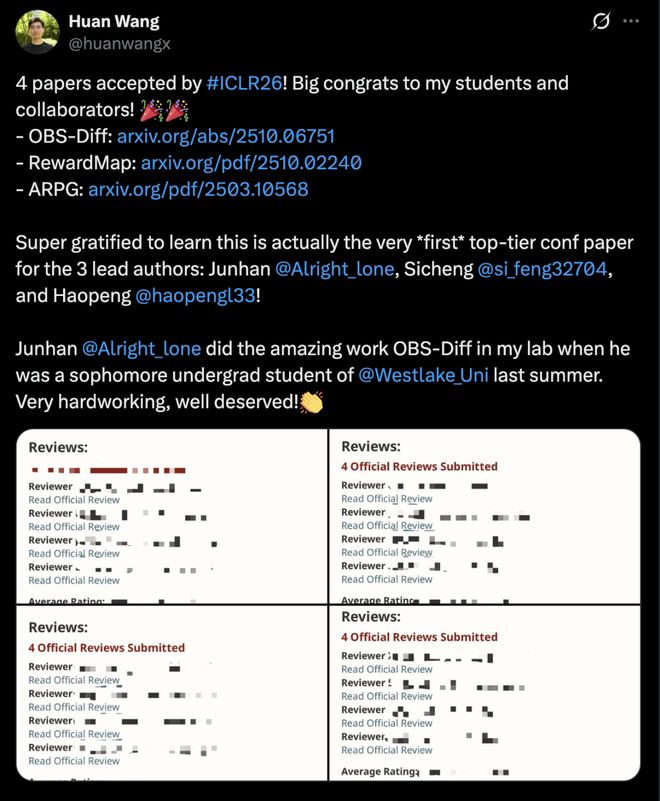
国内高校一些学生解锁「首篇顶会论文」成就,甚至还有大二学生!
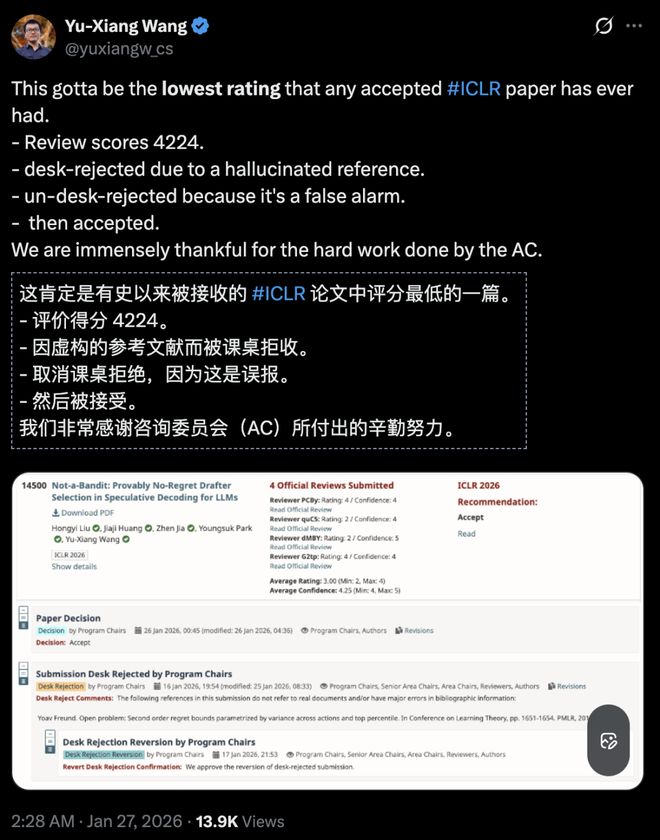
因误报虚构参考文献,被 ICLR 2026 桌面拒稿,最后柳暗花明,Yu-Xiang Wang 分享了「有史以来 ICLR 中稿论文」最低的一篇的故事。
根据传言,中一篇 ICLR 等顶会论文,作者就可以正式称自己为「AI 研究员」,恭。和新 AI 研究员一起分享这些喜悦吧。
在此,恭喜所有 ICLR 2026 论文作者。
但 AI 研究社区涌现出了新的问题,不容小觑。
AI 顶会之乱,ICLR 之殇
最大问题不是审稿人信息被泄露,投稿人和审稿人直接对线,而是评审质量的下滑。
比如,AI 开始反噬 AI 研究。
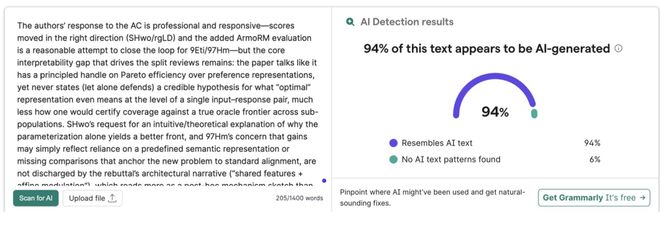
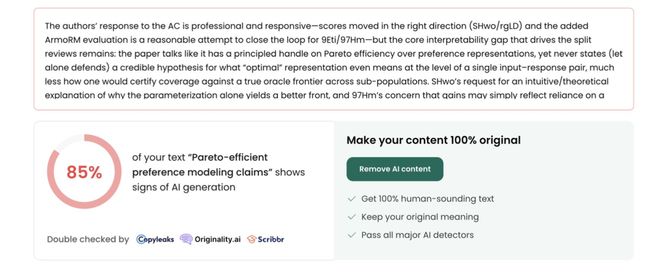
此前,卡内基梅隆大学教授 Graham Neubig 使用 Pangram Labs 的 AI 文本检测工具 EditLens,发现 ICLR 公开的 75800 条评审意见 21% 被高度怀疑「完全由 AI 生成」。
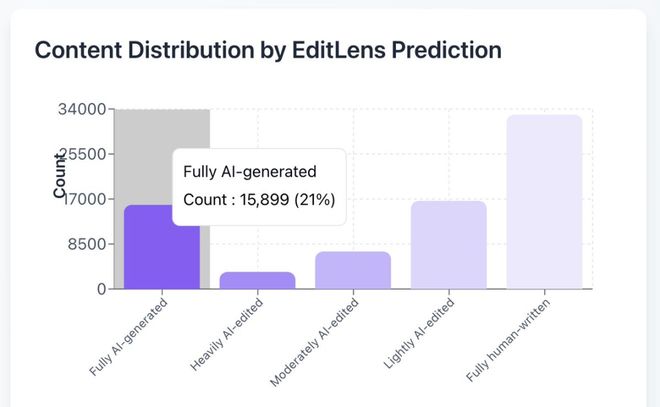
AI 写论文,AI 评阅!AI 顶会 ICLR 完成「AI 闭环」,1/5 审稿意见纯 AI 给出
这种 AI 滥用现象并没有得到解决:

ICLR2025 发布了评审或元评审过程中使用 LLM 的相关政策:

不过,ICLR 似乎没有提出合适的机制,确保 AI 评审的质量,只是要「评审人对评审内容负有最终责任」、遵守学术伦理。
有投稿人直言,100% 的评审意见全是 AI 生成的。
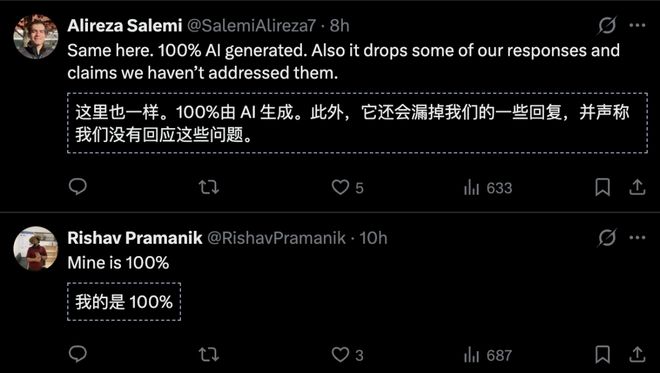
有网友直言,受够了整个匿名评审这套游戏——
即使拿到了高分,即使多数审稿人都表示文章可以接收,只要一个审稿人就能推翻录用结果。
更糟糕的是,你可能收不到任何解释。

审稿人的偏见在匿名审稿中似乎看不到如何被纠正。
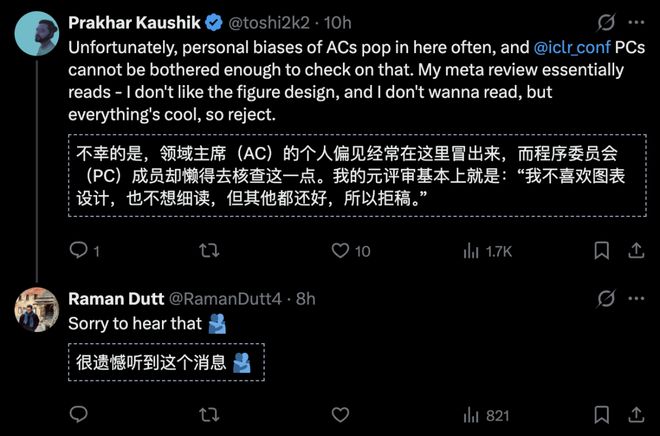

更不要说,审稿人的学术品味也不一定足以胜任顶会审稿工作。
国内人大副教授刘勇,从事大模型基础理论研究,就有多篇论文被「误杀」。
他感慨道「搞理论的本来不容易,希望审稿人专业点」,呼吁给理论研究留下「火种」。
参考资料:






