金磊发自杭州
量子位 | 公众号 QbitAI
天下苦机器人看不清透明反光物体久矣。
毕竟就连小动物甚至人,有时候一个不小心,都会搞笑地撞到干净的玻璃门……

不仅如此,若是让机器人拿起透明的玻璃杯反光的不锈钢物体,他们也会经常出现“突然瞎了”的情况。
这一切的问题,正是出在了机器人的眼睛——深度相机。
因为无论是基于结构光还是双目立体视觉的深度相机,它们的工作原理都是依赖物体表面对光线的稳定反射。
而透明材质会让光线直接穿透,高反光材质则会将光线漫反射到四面八方,导致传感器无法接收到有效的回波信号,从而产生大量缺失或错误的深度值。
对比一下我们人类看到的场景和机器人眼中的场景,就一目了然了:

毫不夸张地说,这类让机器人睁眼瞎的问题,一直是阻碍它们安全地走进家庭、商场和医院等场景的Big Big Big Problem!
但现在,随着一项新技术的提出,机器人的眼疾终于算是被治好了——
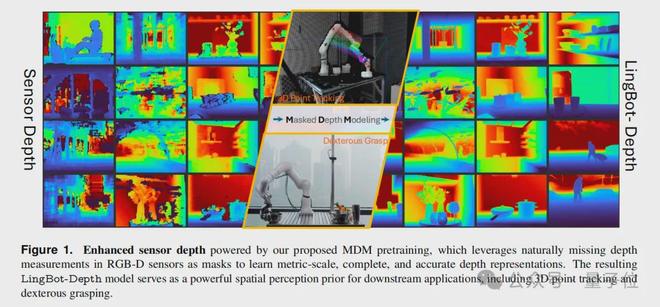
蚂蚁集团的具身智能公司蚂蚁灵波(RobbyAnt),开源了全球看得最清楚的深度视觉模型,LingBot-Depth
同样是上面两个场景,我们直接来看下在 LingBot-Depth 加持下的效果:

也正因如此,机器人现在不论是抓取反光的不锈钢杯子,还是透明的玻璃杯,都是易如反掌:

视频地址:https://mp.weixin.qq.com/s/y-5vx4MVlkucEMwxNQunJA
用一句经典歇后语来表达这个 feel,或许就是“老太太戴眼镜——不简单”
确实不简单。
因为 LingBot-Depth 不仅解锁了“全球看得最清楚”的头衔,还是首次在不需要换硬件的条件下就能实现的那种。
那么蚂蚁灵波到底是怎么做到的,我们这就细扒一下论文。
咋就一下子能看清了?
在很多非专业讨论中,透明和反光常常被混为一谈,统称为视觉难点。
但若是从算法层面来看,它俩其实是两类截然不同、甚至相反的问题。
首先,透明物体的问题在于信息缺失
玻璃几乎不提供稳定的纹理,也不会像普通物体那样反射环境光,相机看到的,更多是背景的延续。
对于深度模型来说,它既不知道玻璃本身到哪儿才算结束,也不知道真实厚度和形态。
而反光物体的问题,恰恰相反,是信息过载
高反射率表面会把环境、光源、相机本身统统映射进画面,导致同一物体在不同角度、不同时间下呈现完全不同的外观。
因此,模型很难判断,哪些像素属于物体,哪些只是倒影。
这也意味着,如果用一套统一的假设去处理这两类问题,往往两头都做不好。
LingBot-Depth 的一个重要设计思想,正是明确区分透明和反光这两种类型的物理成因,而不是把它们简单当成噪声。
为此,蚂蚁灵波团队想到了一个非常反直觉的解法
既然传感器在这些地方失效了,那这个失效本身,不就是一种最有力的特征吗?
因为传感器输出的那些缺失区域,其实是一个天然的掩码(Natural Mask),起码可以告诉模型这块区域有问题。
受今年大火的 MAE(Masked Autoencoders)的启发,团队便提出了一种名为Masked Depth Modeling(MDM,掩码深度建模)全新范式。
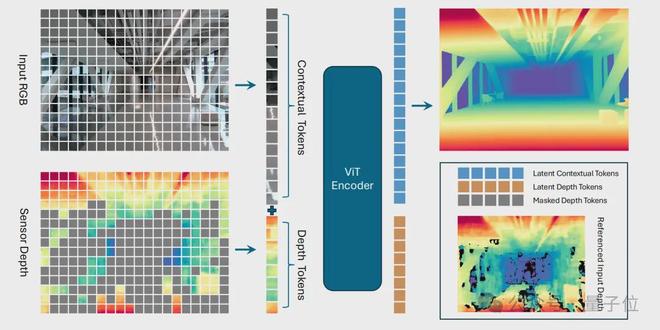
简单来说,LingBot-Depth 在训练的过程中,会把深度图中那些天然缺失的区域作为掩码,然后要求模型仅凭完整的 RGB 彩色图像和剩余的有效深度信息,去脑补出被掩码遮住的那部分深度。
但这个过程也是非常具备挑战性的。
模型必须学会从 RGB 图像中挖掘出极其细微的线索,比如玻璃边缘的折射畸变、反光表面的环境倒影、物体的轮廓和阴影,然后将这些视觉上下文与已知的几何信息进行深度融合,才能做出准确的推断。
为了实现这一目标,LingBot-Depth 在技术架构上也是做了一些小巧思:
首先是联合嵌入的 ViT 架构。
模型采用视觉 Transformer(ViT-Large)作为主干网络,它会对输入的 RGB 图像和深度图分别进行分块(Patch Embedding),生成两组 Tokens。
为了区分这两种模态,模型还引入了模态编码(Modality Embedding),告诉网络哪些令牌来自颜色,哪些来自深度。随后,通过自注意力机制,模型能够自动学习颜色与深度之间的精细对应关系,建立起跨模态的联合表征。
其次是智能掩码策略。
不同于 MAE 中完全随机的掩码,MDM 的掩码策略更聪明。它优先使用传感器天然产生的缺失区域作为掩码;对于部分有效、部分无效的深度块,则以高概率(如 75%)进行掩码;如果天然掩码不够,才会补充一些随机掩码。
这种策略确保了模型始终在解决最困难、最真实的问题。
最后是 ConvStack 解码器。
在重建阶段,模型放弃了传统的 Transformer 解码器,转而采用一个名为 ConvStack 的卷积金字塔解码器。
这种结构在处理密集的几何预测任务(如深度图)时,能更好地保留空间细节和边界锐度,输出的深度图更加清晰、连贯。
此外,在数据采集与实验验证环节,团队还使用了奥比中光(Orbbec)的 Gemini 330 系列双目 3D 相机进行了大量真实场景的采集与测试。
这不仅保证了数据来源的多样性与真实性,也为模型在实际硬件平台上的部署提供了重要支持。
通过这种方式,LingBot-Depth 不仅学会了补全深度,更重要的是,它将对 3D 几何的深刻理解内化到了模型的“骨髓”里。
即使在推理时只给它一张单目 RGB 图片(没有任何深度输入),它也能凭借学到的先验知识,估算出相当准确的深度图,展现出强大的泛化能力。
200 万真实数据炼出来的
一个模型再强大,也离不开高质量、大规模的数据。
蚂蚁灵波团队构建了一套可扩展的数据采集与合成的 pipeline,最终汇集了总计约 300 万的高质量 RGB-D 样本用于模型预训练。
其中,200 万来自真实世界,100 万来自高保真仿真。
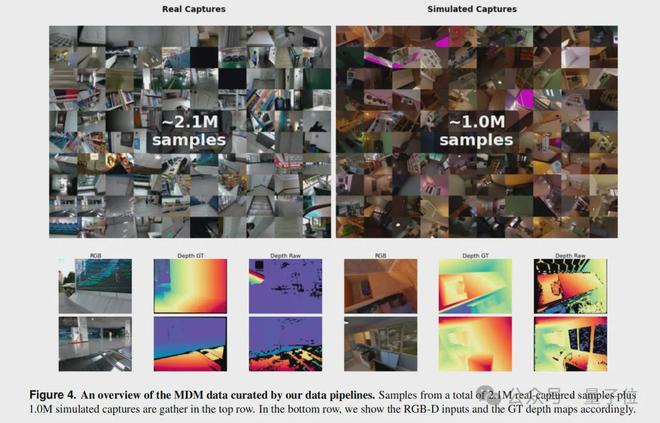
真实数据方面,团队设计了一套模块化的 3D 打印采集装置,可以灵活适配多种商用 RGB-D 相机(如 Orbbec Gemini、Intel RealSense、ZED 等)。
他们走遍了住宅、办公室、商场、餐厅、健身房、医院、停车场等数十种场景,系统性地收集了大量包含透明、反光、低纹理等挑战性物体的真实数据。这些数据覆盖了极其丰富的长尾场景,为模型的鲁棒性打下了坚实基础。

仿真数据方面,为了模拟真实深度相机的成像缺陷,团队没有简单地渲染完美的深度图,而是在 Blender 中同时渲染 RGB 图像和带散斑的红外立体图像对。再通过经典的半全局匹配(SGM)算法生成有缺陷的仿真深度图。
这种方法能高度还原真实传感器在面对复杂材质时的失效模式。
值得注意的是,这套包含 200 万真实和 100 万仿真数据的庞大数据集,是蚂蚁灵波团队近期计划开源的重要资产,旨在降低整个行业在空间感知领域的研究门槛。
算法够创新,数据够硬核,这才有了 LingBot-Depth 突出的性能表现。
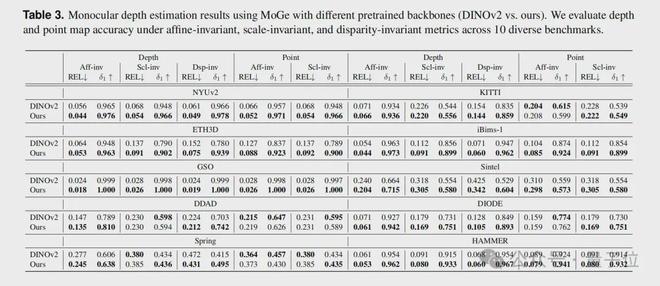
在多个权威的深度补全基准测试(如 iBims、NYUv2、DIODE)上,它全面碾压了当前最先进的 SOTA。
尤其是在最严苛的极端设定下(深度图大面积缺失并伴有严重噪声),LingBot-Depth 的 RMSE 指标比此前最好的方法降低了超过 40%。
除此之外,尽管模型是在静态图像上训练的,但它在视频序列上展现出了惊人的时空一致性。
在一段包含玻璃大门、有镜子和玻璃的健身房、海洋馆隧道的视频中,LingBot-Depth 输出的深度流不仅填补了原始传感器的大片空洞,而且在整个视频过程中保持平滑、稳定,没有任何闪烁或跳变。

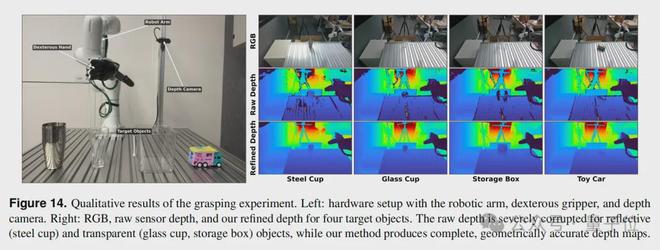
为了验证 LingBot-Depth 在真实世界中的价值,蚂蚁灵波团队将其部署到了一台真实的机器人平台上。
这套系统由 Rokae(节卡)XMate-SR5 机械臂、X Hand-1 灵巧手和 Orbbec Gemini 335 RGB-D 相机组成。

视频地址:https://mp.weixin.qq.com/s/y-5vx4MVlkucEMwxNQunJA
实验目标是抓取一系列对深度感知极具挑战的物体:不锈钢杯、透明玻璃杯、透明收纳盒和玩具车。
在 20 次抓取尝试中,使用 LingBot-Depth 的成功率远高于使用原始深度数据。
缺点,有时也是一种优势
解决物理世界的感知难题,好的硬件固然重要,但不一定非要死磕。
这或许就是 LingBot-Depth 给行业带来的一种启发。
因为在过去,当现有深度相机无法满足需求时,唯一的出路往往是斥巨资更换更昂贵、更专业的硬件。
而 LingBot-Depth 提供了一条软硬协同的路径:它可以在不更换现有相机硬件的前提下,通过算法大幅提升深度感知的鲁棒性与完整性。
它可以作为一个即插即用的算法模块,无缝集成到现有的机器人、自动驾驶汽车或 AR/VR 设备的感知链路中,以极低的成本,显著提升其在复杂真实环境下的 3D 感知鲁棒性。
例如,在与奥比中光等硬件适配的过程中,团队验证了 LingBot-Depth 能够在其现有消费级深度相机上实现接近专业级传感器的感知效果。
这无疑将大大加速具身智能在家庭服务、仓储物流、商业零售等场景的落地进程。
更重要的是,灵波团队秉承开放精神,已经开源了 LingBot-Depth 的代码和模型权重,并计划开源其庞大的 300 万 RGB-D 数据集。
这一举动将极大地降低学术界和工业界在空间感知领域的研究与开发门槛,有望催生更多创新应用,共同推动整个行业的向前发展。
除此之外,LingBot-Depth 也是有哲学意味在身上的:
有时候,缺点本身就是一种优势。
你觉得呢?
项目地址:
https://technology.robbyant.com/lingbot-depth
GitHub 地址:
https://github.com/robbyant/lingbot-depth
HuggingFace 地址:






