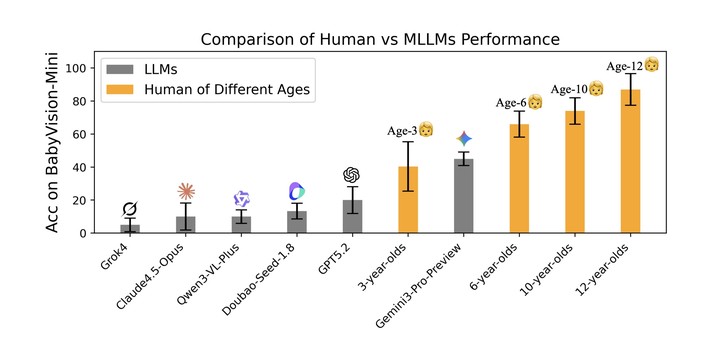
据量子位报道,多家研究机构最新发布的 BabyVision 视觉推理基准结果显示,当前最强多模态模型在视觉推理方面的表现,仍显著落后于人类儿童水平。
即便是表现最好的 Gemini 3 Pro Preview,其得分也仅略高于 3 岁儿童,与 6 岁儿童仍存在约 20% 的差距,与成年人 94.1% 的水平更是相去甚远。
研究来自 UniPat AI、xbench、阿里、月之暗面、阶跃星辰等团队。结果显示,Gemini 3 Pro Preview 以 49.7% 的成绩领跑闭源模型,其后依次为 GPT‑5.2(34.4%)与豆包 Seed‑1.8(30.2%)。
其他模型表现更低,包括 Qwen3‑VL‑Plus(19.2%)、Grok‑4(16.2%)与 Claude 4.5 Opus(14.2%)。在开源模型中,Qwen3VL‑235B‑Thinking 以 22.2% 的成绩位列第一,但仍无法与闭源模型竞争。
研究指出,当前多模态大模型普遍采用「视觉转语言」的推理路径,即先将图像压缩为语言表征,再依赖语言模型进行推理。
这一架构在处理细粒度几何、空间关系、路径连续性等非语言特征时存在天然瓶颈,导致模型在「找不同」「连线」「空间想象」「视觉规律归纳」等任务中频繁出错。
在 BabyVision 的四大能力维度 —— 细粒度辨别、视觉追踪、空间感知与视觉模式识别中,模型均暴露出明显短板。
例如,Gemini 3 Pro Preview 在拼图匹配、路径连线与三维结构推断任务中均出现错误;Qwen3‑VL‑Plus 在视觉规律归纳任务中也未能给出正确答案。
研究团队进一步分析了模型在视觉推理中的四类核心挑战:
- 非言语性精细细节难以保留,导致模型无法区分微小差异;
- 流形一致性缺失,使模型难以在复杂路径中保持连续追踪;
- 空间想象能力不足,难以从二维图像构建稳定的三维表征;
- 视觉模式归纳能力薄弱,无法从示例中抽象出变化规则。
为突破语言化视觉推理的限制,研究提出两条潜在路径:基于可验证奖励的强化学习(RLVR)与基于生成模型的视觉推理。
实验显示,Qwen3‑VL‑8B‑Thinking 在 RLVR 微调后整体准确率提升约 4.8 个百分点;而在 BabyVision‑Gen 的生成式推理测试中,NanoBanana‑Pro 以 18.3% 的准确率领先 GPT‑Image‑1.5 与 Qwen‑Image‑Edit。
研究认为,未来多模态智能的发展方向,将从「语言驱动」转向「视觉原生推理」。
统一架构(如 Bagel)与具备物理建模能力的生成模型(如 Sora 2、Veo 3)展示了在视觉空间中进行显式推理的潜力,包括绘制中间步骤、标注关键区域或生成物理轨迹等方式。
研究团队指出,生成过程本身可能成为一种更高级的推理形式。






