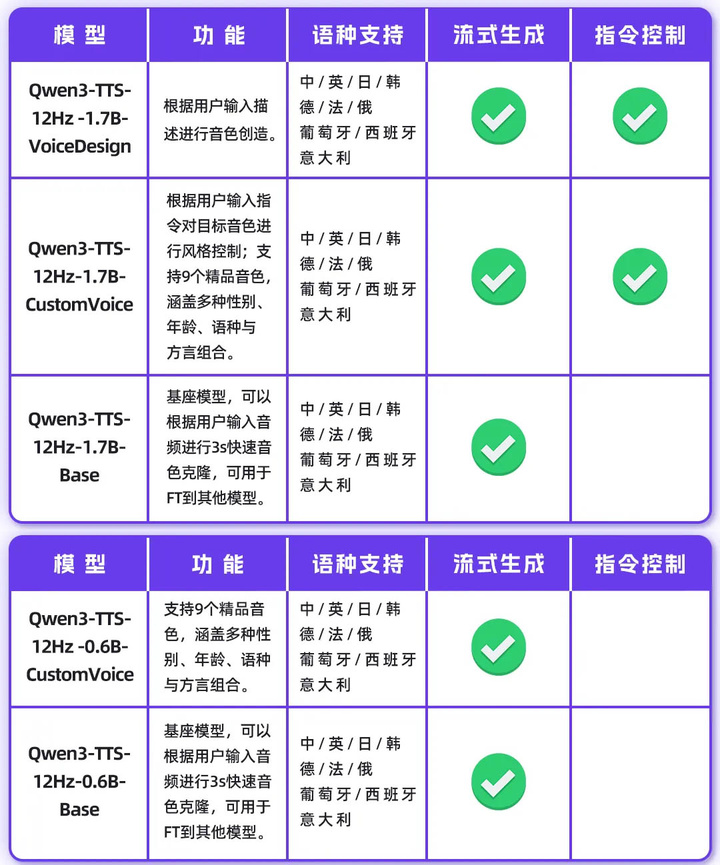
近日,千问 Qwen 宣布 Qwen3‑TTS 全系列语音生成模型正式开源,覆盖 1.7B 与 0.6B 两种尺寸,并支持音色克隆、音色创造、情感与韵律控制、多语种生成等完整语音能力。
官方表示,新版本在生成质量、延迟控制与跨语言泛化方面均达到业内领先水平。
官方宣称,Qwen3‑TTS 可在保持声学细节与副语言信息的前提下实现高效压缩,并通过轻量级非 DiT 架构实现高速还原。
官方数据显示,该 tokenizer 在 PESQ、STOI、UTMOS 等指标上均达到 SOTA 水平,且在说话人相似度上显著领先同类模型。
据介绍,模型端到端合成延迟最低可达 97ms,输入单字后即可输出首包音频,满足实时交互需求。
Qwen 表示,1.7B 版本面向极致性能场景,具备更强的音色控制与情感表达能力;0.6B 版本则在性能与效率之间取得平衡,更适合边缘部署。
在功能层面,Qwen3‑TTS 支持自然语言指令驱动的音色、情感、节奏与韵律控制,可根据文本语义自适应调整表达方式,并具备对噪声文本的更高鲁棒性。
模型覆盖中文、英文、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语、意大利语等 10 种语言,并提供多种方言音色,适用于全球化应用场景。
目前,Qwen3‑TTS 已在 Github、HuggingFace 与 ModelScope 全面开源,开发者可直接下载模型或通过 Qwen API 体验。
💻 Github: https://github.com/QwenLM/Qwen3-TTS
🤗 HuggingFace: https://huggingface.co/collections/Qwen/qwen3-tts
👾 ModerScope: https://www.modelscope.cn/collections/Qwen/Qwen3-TTS






