
新智元报道
编辑:定慧
过去 10 年,AI 大模型的技术本质,是把电力能源通过计算过程转化为可复用的智能。2026 年,我们需要让 AI 模型在单位时间内「吃下」更多能源,并真正将其转化为智能。
2026 年的 AI 圈子,最怕什么?
从 2022 年底 ChatGPT 横空出世以来,AI 圈子里一直潜藏着一个「幽灵」。
从 ChatGPT 到惊艳世界的 DeepSeek,再到 2025 年底的 Gemini 3、GPT-5.2 等,所有这些顶级模型背后都是这个幽灵。
他就是Scaling Law,但是令所有人焦虑的是:这个幽灵是否将要,还是已经「撞墙」了?!
Scaling Law 是否已经失效?
大佬们的看法出现了前所未有的分歧。
Ilya Sutskever公开表示,单纯堆砌预训练算力的时代正在进入平台期,智能的增长需要转向新的「研究时代」。

Yann LeCun则一如既往地毒舌,认为当前的大语言模型无论怎么 Scaling 都无法触达真正的 AGI。
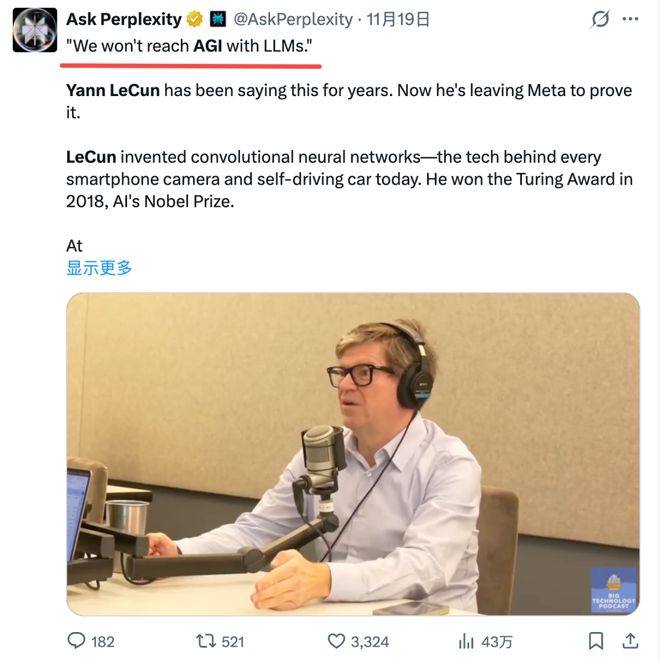
即便是Sam Altman,也在公开场合含蓄地承认过,仅仅靠更多的 GPU 已经无法换回同比例的智能跃迁。

当全行业都在为「数据枯竭」和「算力报酬递减」头疼时,大家都在问:
算力还在涨,为什么智能的跃迁似乎变慢了?
最近在刷知乎时,读到了新加坡国立大学校长青年教授、潞晨科技创始人尤洋(Yang You)的一篇深度长文:《智能增长的瓶颈》。(文末附有原文)
这篇文章的角度非常独到,尤洋站在基础设施与计算范式的底层,探讨了一个更本质和底层的问题:
算力是如何被转化为智能的,以及这种转化机制是否正在失效。
尤洋教授在文中给出了一个引人深思的观点:
过去 10 年,AI大模型的技术本质,是把电力能源通过计算过程转化为可复用的智能。

文章系统性地梳理了过去十年大模型成功背后的「隐含假设」,并指出这些假设正在接近边界。
一、智能从哪里来?
尤洋对「智能」的定义相当通俗易懂,也就是模型的预测与创作能力。
在此基础上,他进一步提出:
「过去 10 年,AI 大模型的技术本质,是把电力能源通过计算过程转化为可复用的智能。」
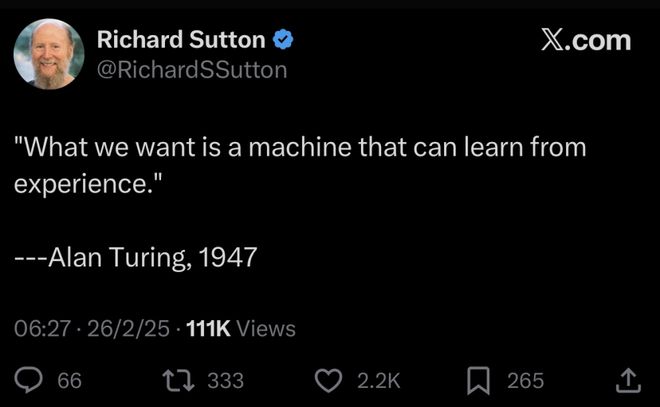
这与强化学习教父 Richard S. Sutton 分享的观点类似。
在尤洋的叙述中,有三个关键共识被明确强调:
- 预训练是智能的主要来源
微调、强化学习等阶段贡献有限,根本原因并非算法无效,而是能源(算力)投入规模不在一个数量级。
- Next-Token Prediction 是一个极其成功的 Loss 设计
它最大化减少了人为干预,给 AI 大模型提供了近乎无限的训练数据。
- Transformer 的胜出,是因为 Transformer 也是一台并行计算机。
Transformer 并非「更像人脑」,而是更像GPU——高度并行、计算密集、通信可控。
正是这三点共同作用,使得从 GPT-1、BERT、GPT-2、GPT-3,到 ChatGPT 与 Gemini,大模型得以在十余年间持续放大算力投入,并将其稳定转化为可感知的智能提升。
尤洋也因此指出了真正的瓶颈所在。
二、真正的「瓶颈」在哪里?
在《智能增长的瓶颈》中,尤洋重新界定了「瓶颈」的涵义,并明确区分了两类经常被混淆的进展:
- 效率提升
用更少参数、更低算力,达到相同效果(如剪枝、蒸馏、低精度、Mamba 等)。这类进展对于工程落地和规模化部署至关重要,但并不直接决定智能的上限。
- 智能上限提升
在相同的浮点计算总量约束下,训练出能力更强、泛化性更好的模型。这才是决定智能是否能够持续跃迁的关键指标。
在尤洋看来,当前遇到的并不是「算力不够」,而是:
「我们现在的范式无法充分利用持续增长的算力。」
换句话说,问题不在于 GPU 增长放缓,而在于模型、Loss、优化算法对算力的「消化能力」正在下降。
我们需要让 AI 模型在单位时间内「吃下」更多能源,并真正将其转化为智能。这么来看:
大模型智能可能还有很大的发展空间,预训练才刚刚开始。
三、未来方向
不是「省算力」,而是「吃下更多算力」
文章对未来路径的判断,整体偏向高投入、强基础设施导向。
简单地说,也就是如果不考虑成本,问题不是「如何更省」,而是「如何更有效地消耗更多算力」。
尤洋提出了几个值得关注的方向:
- 更高数值精度
当前从 FP16→FP32→FP64 并未带来明显智能跃迁,但这可能是「未被充分探索」的方向,而非被证伪。
- 更高阶优化器
从一阶梯度方法转向更高阶优化器,理论上可以提供更「聪明」的参数更新路径,但高阶优化器的全面替代可能需要很长的时间。
- 更具扩展性的模型架构或 Loss 函数
不以吞吐或效率为目标,而以「在极限算力下能否训出更强模型」为标准。
- 更充分的训练和搜索
包括 Epoch、超参数、数据与参数匹配关系,而非简单「再多跑几轮」。
值得注意的是,文章明确将推理优化、低精度、蒸馏等技术划归为「落地层面」,并强调它们与「智能上限」是两条不同的技术曲线。
结语
如果说过去十年 AI 的核心问题是「如何获得更多算力」,那么接下来一个阶段,问题可能变成:
我们是否真的知道,如何把这些算力变成智能。
《智能增长的瓶颈》像是一份写给从业者的技术备忘录:当算力仍在增长,但智能不再「自动升级」时,我们需要重新审视哪些变量才是真正决定上限的因素。
以下为《智能增长的瓶颈》原文。
智能增长的瓶颈
作者:尤洋,新加坡国立大学校长青年教授,潞晨科技创始人。
2026 年已至。
在 ChatGPT 诞生三年多后的今天,关于我们的智能水平是否令人满意,以及未来是否还能强劲增长,笔者想分享一些个人的看法。如有谬误,恳请大家指正。
为了能深入探讨智能的本质,本文将不涉及产品易用性、成本等商业化或落地问题,因为这些本质上与智能突破本身无关。
智能的现状
什么是智能?
其实目前并没有一个明确的定义。
从最近图灵奖得主 Yann LeCun 和诺贝尔奖得主 Demis Hassabis 关于 AGI 的争论中,我感受到即便是世界上最顶尖的专家也无法准确定义智能。
个人感觉,AGI 很难定义,其标准也会随着时代的变化而变化。
我依然记得十几年前,普通人对人脸识别技术感到不可思议。
如果把今天的 ChatGPT 拿到 2006 年,相信那时候的很多人会毫不怀疑地认为我们已经实现了 AGI。
我觉得智能的核心是预测和创作。
我认为如果达到以下这种状态,那么就离 AGI 不远了:
-
如果你选择接受哪个工作 Offer,完全听从 AI 的意见。
-
如果你买足球彩票预测世界杯冠军,完全听从 AI 的意见。
-
如果你有健康问题,会完全采用 AI 制定的方案去治疗。
-
你分辨不清楚一部奥斯卡最佳电影是否是由 AI 生成的。
-
石油公司的勘探团队用 AI 替代了所有数值算法。
-
AI 能指导初级高铁工程师在 5 分钟内排除高铁的疑难故障。
-
AI 能研制出一款专杀癌细胞且不破坏好细胞的药物。
-
AI 能通过某区域的地下结构数据,精准预测地震的时间。
-
等等……
今天,我们显然还没实现这些。未来能否实现,取决于我们能否克服智能发展的瓶颈。
智能发展的瓶颈
今天,我们经常听到一些关于智能发展遇到瓶颈,或者预训练红利已尽的观点。
何为瓶颈?我们先探讨一下智能从何而来。
过去 10 年,AI 大模型的技术本质,是把电力能源通过计算过程转化为可复用的智能。
技术的好坏取决于这个转化效率的高低。类似的表述,我也听月之暗面的朋友提及过。
今天模型的智能本身,最主要还是来自预训练(往往是自监督方法),仅有少量来自微调或强化学习。
为什么?先算一笔浅显的经济账:因为预训练消耗的算力最多,消耗的能源也最多。
当然,预训练、微调、强化学习本质上都是在计算梯度以更新参数。
如果有合适的海量数据和 Loss 函数,未来在预训练阶段采用 SFT(监督微调)或特殊的强化学习方法也有可能。
从智能增长的角度,我们甚至不用刻意区分预训练、SFT 和强化学习。
它们的区别主要在于更新参数的次数与规模。从计算本质上看:预训练、微调、强化学习(比如 GRPO)都是在计算梯度的类似物,并用它来更新参数。
那么,能源从何而来呢?
这就是 GPU 或算力。英伟达在这点上做了最大的贡献。
虽然英伟达有很多先进的技术,比如更强的 Tensor Cores、Transformer Engine、互联技术(NVLink/网络化 NVLink)、软件栈等,但我先试图用一句话说清楚英伟达过去几年在技术上做的最重要的事情,即其 GPU 设计的核心思路。
简而言之,英伟达过去几年最重要的路线是:在同样的物理空间里堆更多 HBM(高带宽内存)。
HBM 虽然带宽很高,但依然是计算核心之外的内存(Off-chip from logic die),与计算核心存在不可忽略的物理距离。
为了掩盖内存访问延迟,GPU 只能依赖超大的 Batch Size(批处理量)和大规模并行来处理数据。
英伟达 GPU 本质上就是一台并行计算机。
因此,英伟达对算法层和软件层的要求非常明确:必须提供足够大的 Batch Size 或并行度。
面对英伟达的要求,很多研究团队都提出了自己的方案。比如 RNN、Transformer、卷积序列模型(CNN for Sequence)等等。甚至有人尝试用 SVM 来处理大规模序列数据。
那为什么 Transformer 率先脱颖而出?
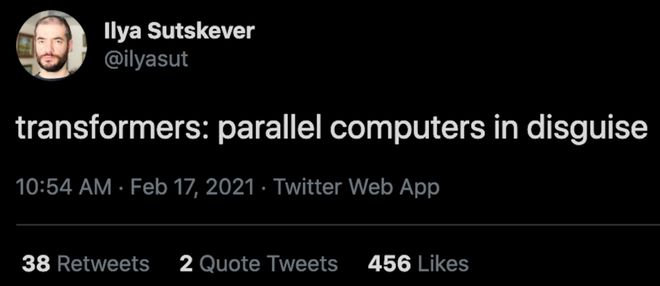
因为 Transformer 也是一台并行计算机。这里我引用一下 Ilya Sutskever 的一句话:
Transformers:parallel computers in disguise.
直白的意思是:Transformer 本质上是一个被神经网络外壳包裹起来的并行计算机。
这也是 Transformer 最先能够显现智能的核心原因,因为它的并行计算特性完美匹配了 GPU 的并行计算单元。
同时,OpenAI 完美地实现了 Next-Token Prediction 这个 Loss 函数,它给了 AI 大模型近乎无限的训练数据。
理论上 BERT 的 Loss 函数(完形填空和 Next Sentence Prediction)也可以提供近乎无限的数据,但在实践中,Next-Token Prediction 的效果明显更好。
我推测,这个 Loss 函数最小化了人类的干预——它不是人为设计的,而是大自然在进化过程中赋予人脑的逻辑。
并且,Next-Token Prediction 其实是预测未来,而 BERT 的完形填空其实是把过去的信息和现在的信息串联起来。
这就好比让一个足球专家根据历史数据和当天的比赛结果去解释合理性,几乎所有专家都能做到;但是,如果让专家去预测每一场比赛的精准比分,他们会经常出错。
这再次说明了,预测(Prediction)是智能的核心能力体现,难度远高于解释(Explanation)。
其实我挺佩服 OpenAI 团队能够坚持下来的勇气。
2018 年时,BERT 在媒体上的影响力几乎完全碾压了 GPT,且当时 OpenAI 的 AI 研发团队体量跟 Google 比起来微不足道。
很佩服他们没有放弃 Next-Token Prediction,也没有转向类 BERT 的训练方式。真理往往需要时间去检验。
同时,以 Transformer 为核心的方案收获了「一箭双雕」的双重优势:
- 模型的每层参数量越多,并行度就越高(Tensor Parallelism)。
所以,只要通信代价不显著增加,能同时利用的算力就越多。这点需要点赞行业领导者的先见之明。几年前,我看到 CNN 时代有研究人员试图把模型往深度发展,比如设想 1000 层的神经网络。其实非常深(层数非常多)的神经网络是不利于有效利用算力的,因为流水线并行提供的并行度上限不高。
- Transformer 的不同 Token 可以同时计算。
序列长度越长,并行度就越高,只要通讯代价不显著增加,能同时利用的算力就越多。Sequence Parallelism 与 Data Parallelism 互补,进一步提供了更多的并行度。
就这样,我们见证了 GPT-1、BERT、GPT-2、GPT-3、ChatGPT、Gemini 一步一步把智能提升到了今天的高度。
到这里,大家大概也清楚为什么 AI 模型的智能增长会遇到瓶颈了——因为我们现在的范式无法充分消化持续增长的算力。
假定一次模型训练和微调消耗的浮点数计算次数(即程序员面试中的计算复杂度的具体值)从 10^n变成 10^{n+3}时,我们是否获得了一个显著更好的模型?
其实,很多时候我们把「效率优化技术」和「智能提升技术」混淆了。
比如,明天我提出一个新的架构,实验发现达到跟 GPT-5 类似的效果,只需要 20% 的参数量或计算量。
这其实更多是落地或商业化问题;智能的终极问题是:使用同样的浮点数计算次数(而非 Token 量),能否获得一个更好的模型。浮点数计算次数,才是算力最基本、最本质的计量单位。
未来的方法探讨
首先从硬件层来看,我们需要持续产生更大的绝对算力,这不一定局限于单位芯片上的算力提升。
即便单位芯片上的算力没有大幅度提升,我们通过集群的方式也能构建更大的绝对算力。这里需要平衡的是:聚集芯片带来的性能增长,要高于「芯片或服务器之间通信增长带来的负担」。
所以,具体的硬指标就是:增长或至少维持住「计算开销/通信开销」这个比值。这是整个 AI 基础设施层最核心的技术目标。要想实现这个目标,我们需要扩展性更好的并行计算技术,无论是软件还是硬件。
在更上层的探索中,我们需要让 AI 模型在单位时间内「吃下」更多能源,并真正将其转化为智能。
个人感觉大概有以下几点方向:
- 更高精度的计算能力。
今天,从 FP16 到 FP32,甚至 FP64,模型智能并未出现明显跃升。这本身就是一个瓶颈。理论上,更高精度应当带来更可靠的计算结果,这一点在传统科学计算中早已得到验证。这个观点可能与主流机器学习共识并不一致,而且真正发生可能需要很长时间,但从本质上看,智能仍然需要更精准的计算。这与过拟合并无直接关系,过拟合的根源在于数据规模不足或参数与数据不匹配。
- 更高阶的优化器。
Google 的朋友告诉我,他们有时候已经不用类 Adam 优化器,而是用更高阶的优化器在训练模型。高阶优化器理论上能在学习过程中给模型更好的指导,算出更好的梯度,这是模型智能提升的本质。当然,高阶优化器的全面替代可能需要很长的时间。
- 扩展性更好的模型架构或 Loss 函数。
我们仍然需要一种扩展性更好的整合和利用算力的方式。这点我们需要注意:优化效率不一定能提升智能。比如 Mamba 出来的时候,宣传重点是吞吐量的提升,用更小的模型获得同水平的智能。但是,本文关注的是:在最健全的 AI 基础设施上,用最大的可接受成本,能否训出更好的模型,获得更高的智能。比如,今天 Google 告诉你:预算 300 亿美元,半年内给我训出一个更好的模型,不考虑省钱问题,花 10 亿和花 100 亿没区别。在这个场景下,你最终是否会用 Mamba 这样的架构?你是否需要设计更好的 Loss 函数?
- 更多的 Epoch 和更好的超参数
迫于成本压力,我们今天其实并没有对 AI 模型进行深度优化,甚至没有深度搜索超参数。这其实也是我之所以对 AI 模型的智能继续增长有信心的原因。我这里的意思不是直接训练更多的 Epoch。明知无效却生硬地跑更多 Epoch 其实是方法不对(比如参数量和数据量不匹配)。但是,根本上,更多的 Epoch 代表更多的浮点数、更多的能源。我们需要找到方法去「吃下」更多能源,并转化出更高智能。
有些技术对大规模落地 AI 非常重要,比如低精度训练、剪枝、量化、蒸馏、PD 分离等推理优化技术。
但是,在一个「算力转智能」极端有效的情况下,这些技术跟提升智能上限无关。
笔者对这些技术的贡献者非常尊重,它们在实际落地中至关重要,只是与本文探讨的主题无关。
智能增长归根到底还是算力利用问题。假定算力无限大,比如一个集群的算力达到今天的万亿倍,可能我们会发现更简单的模型结构比 Transformer 和 Next-Token Prediction 的扩展性更好。
从 SVM 到 CNN、LSTM、BERT、GPT、MoE:我们始终在寻找能更高效利用算力且具备更好扩展性的方法。
这个过程中,核心原因是问题的规模在不断扩大。
我们在 AI 时代到来之前便已实现天气预报,然而至今仍未能攻克地震预报,尽管两者本质上都是针对地球数据的研究。
究其原因,地下结构涉及比大气更加错综复杂、且变量规模呈指数级庞大的动态多模态数据。
这种传统计算模式难以驾驭的高维复杂性,恰恰是未来 AI 技术大有可为的机遇所在。
所以,我有信心我们未来会不断找到更高效的算力使用方式。
虽然过程中可能会有很多困难和低潮,但大趋势不可阻挡。
最后,借用 Richard Sutton 教授的一句话收尾:
人工智能 70 年的研究留给我们最大的经验教训是,依托计算能力的通用方法才是最终的赢家,且具备压倒性的优势。






