
新智元报道
编辑:LRST
【新智元导读】视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布 EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏 KV 缓存 +LoRA 动态适应架构,彻底解决长视频「内容漂移」难题,在 EgoVid-5M 基准上刷新 SOTA!让 AI 像人一样拥有连贯的第一人称视角记忆。
随着 Sora、Genie 等模型的爆发,视频生成正从「图生动」迈向「世界模拟器」的宏大目标。
然而,在通往「无限时长」视频生成的路上,横亘着一只拦路虎——「内容漂移」(Content Drift)。
你是否发现,现有的视频生成模型在生成长视频时,往往也是「金鱼记忆」:前一秒还是蓝色瓷砖,后一秒变成了白色墙壁;原本手里的杯子,拿着拿着就变成了奇怪的形状;
对于第一人称(Egocentric)视角这种晃动剧烈、交互复杂的场景,模型更是极其容易「迷失」。
生成长视频不难,难的是「不忘初心」。
近日,来自北京大学、中山大学、浙江大学、中科院和清华大学的研究团队,提出了一种全新的长上下文扩散模型 EgoLCD,不仅引入了「类脑的长短时记忆」设计,还提出了一套全新的结构化叙事 Promp 方案,成功让 AI 在生成长视频时「记住」场景布局和物体特征。

论文地址:https://arxiv.org/abs/2512.04515
项目主页:https://aigeeksgroup.github.io/EgoLCD
在 EgoVid-5M 基准测试中,EgoLCD 在时间一致性和生成质量上全面碾压 OpenSora、SVD 等主流模型,向构建具身智能世界模型迈出了关键一步!
核心痛点
AI 为什么会「失忆」?
在长视频生成中,传统的自回归(AR)模型非常容易出现生成式遗忘。
这就像让一个人蒙眼画画,画着画着就偏离了最初的构图。对于第一人称视频(如 Ego4D 数据集)来说,剧烈的相机抖动和复杂的手物交互,让这种「漂移」更加致命。
传统的 Transformer 虽然有注意力机制,但面对长序列,计算量呈二次方爆炸根本存不下那么多历史信息;而简单的滑动窗口又会丢掉早期的关键信息。
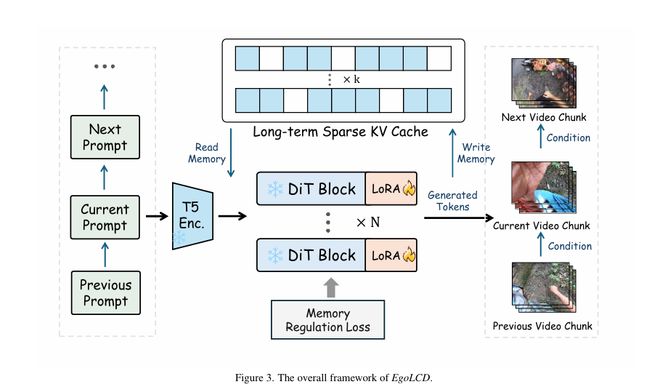
EgoLCD (Egocentric Video Generation with Long Context Diffusion) 将长视频生成重新定义为一个「高效且稳定的内存管理问题」。
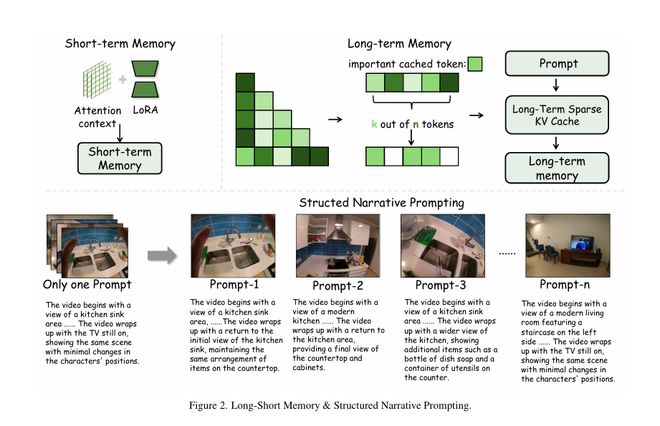
长短时记忆系统 (Long-Short Memory)
EgoLCD 设计了一种类似人类大脑的双重记忆机制:
长期记忆(Long-Term Sparse KV Cache):不再傻傻地缓存所有 Token,而是利用稀疏注意力机制,只存储和检索最关键的「语义锚点」(比如房间的布局、关键物体的特征)。这不仅大大降低了显存占用,还锁死了全局一致性。
短期记忆(Attention+LoRA):利用 LoRA 作为隐式记忆单元,增强短窗口注意力的适应性,快速捕捉当前视角的剧烈变化(如手的快速移动)。
一句话总结:长期记忆负责「稳」,短期记忆负责「快」。
记忆调节损失 (Memory Regulation Loss)
为了防止模型在训练时「偷懒」,团队设计了一种特殊的损失函数。它强制模型生成的每一帧,都要与从长期记忆库中检索到的「历史片段」保持语义对齐。
这就像给 AI 戴上了一个「紧箍咒」,一旦它生成的画面开始「胡编乱造」(漂移),Loss 就会惩罚它,迫使它回归原本的设定。
结构化叙事提示 (Structured Narrative Prompting, SNP)
EgoLCD 抛弃了简单的文本提示,采用了一种分段式的、包含时间逻辑的结构化剧本。
训练时:使用 GPT-4o 生成极其详尽的帧级描述,训练模型将视觉细节与文字严格对应。
推理时:SNP 充当「外部显性记忆」,通过检索前序片段的 Prompt,引导当前片段的生成,确保故事线和视觉风格的连贯。
性能炸裂
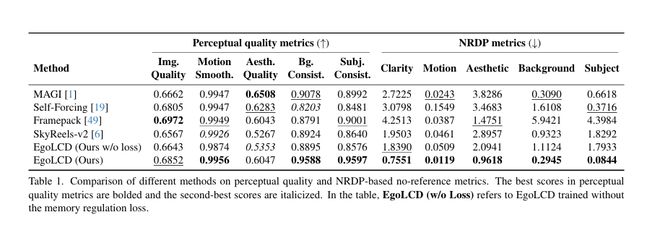
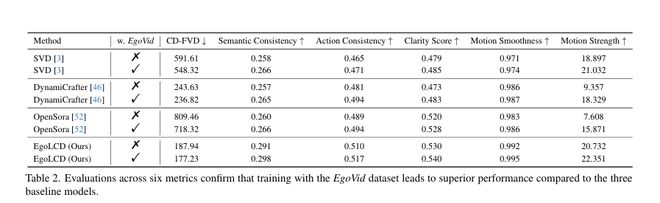
为了公正地评测「不遗忘」的能力,研究团队甚至专门开发了一套新指标——NRDP (Normalized Referenced Drifting Penalty),专门用来惩罚那些「虎头蛇尾」、越往后质量越差的模型。
实验结果显示:
一致性碾压:在 NRDP-Subject(主体一致性)和 NRDP-Background(背景一致性)上,EgoLCD 取得了压倒性优势,漂移率极低。
超越基线:相比 SVD、DynamiCrafter 和 OpenSora 等顶流模型,EgoLCD 在 EgoVid-5M 基准上的 CD-FVD(时序连贯性)和动作一致性指标均为最佳。
极长生成:展示了长达 60 秒的连贯视频生成(如一名演讲者从黄昏讲到深夜),人物衣着、背景楼宇细节始终如一,没有发生形变!
通往具身智能的「黑客帝国」
EgoLCD 不仅仅是一个视频生成模型,它更像是一个「第一人称世界模拟器」。
通过生成长时程、高一致性的第一人称视频,EgoLCD 能够为具身智能(机器人)提供海量的训练数据,模拟复杂的物理交互和长序列任务(如做饭、修理)。
正如 Sora 让人们看到了世界模型的雏形,EgoLCD 则让「通过视频教会机器人理解世界」的梦想,变得前所未有的清晰。
参考资料:






