新智元报道
编辑:倾倾
学霸的谎言被揭穿!一篇来自 Adobe Research 的论文发现,高语义理解并不会提升生成质量,反而可能破坏空间结构。用 iREPA 简单修改,削弱全局干扰,生成质量立即飙升 。
我们经常会疑惑:为什么视觉模型越高级,生成效果反而越差?
最近,Adobe Research 发了一篇论文,专门解释了这个看起来有点反常、但反复出现的现象。

论文地址:https://arxiv.org/pdf/2512.10794
按直觉,模型要先知道「这是什么」,才能把它画出来。
ImageNet 上的分类准确率越高,说明模型的语义理解越强,生成的内容越稳定、越靠谱。
但这篇论文给出的结果,完全相反:
一些在识别任务中表现平平、甚至看起来「很不聪明」的视觉编码器,反而能生成出结构更清晰、质量更高的图像。
全局语义能力越强,生成反而越容易出问题。
很可能我们从一开始,就误会了生成模型真正擅长的是什么。
为什么视觉模型越「聪明」,生成的反而越差?
先看一个已经被反复验证的事实:一个模型在 ImageNet 上的线性探测准确率越高,并不意味着它更适合用来做生成。
最直观的例子是 SAM2。这是一个在识别任务里不出彩的模型,验证准确率只有 24.1%,远低于主流视觉大模型。
但当这些编码器被用于 REPA 时,SAM2 的生成质量反而优于一批准确率高出约 60% 的模型。
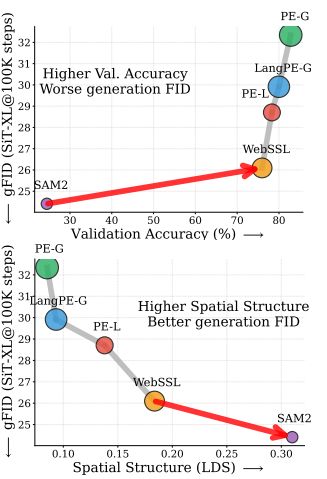
SAM2 的 ImageNet 验证准确率仅为 24.1%,但在 REPA 框架下的生成 gFID 明显优于多种准确率超过 70% 的视觉编码器。
这还不是某一个模型的偶然表现。
论文进一步比较了同一编码器家族中不同规模的模型,结果发现:模型越大、分类准确率越高,生成质量反而可能相似或更差。
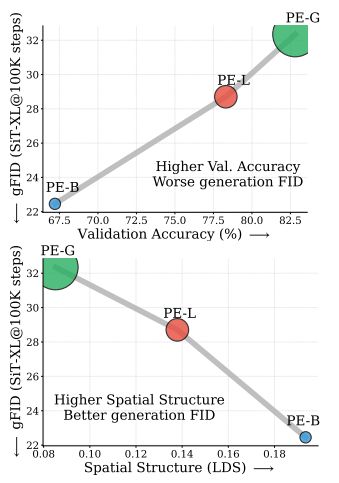
随着模型规模和分类准确率提升,生成 gFID 反而整体变差,表明这一现象并非由个别模型导致。
显然,「高语义能力=好生成」这条默认路径,在大量实验中并不成立 。
更关键的是,这种现象并不是噪声。
在跨模型、跨设置的系统性分析中,全局语义指标与生成质量之间的相关性始终非常弱。
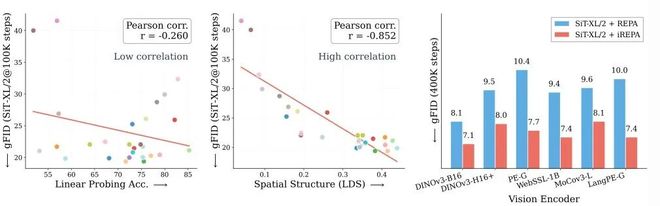
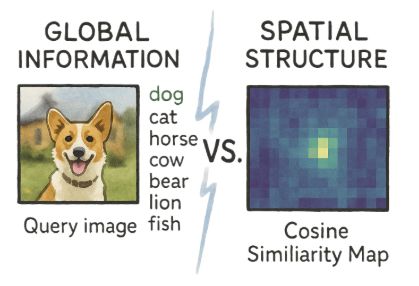
分类能力与生成质量几乎无关,空间结构却高度相关。左:线性探测准确率与生成 gFID 的相关性极弱(Pearson r=-0.26)。中:空间结构指标(LDS)与生成质量呈现出显著强相关(Pearson r=-0.85)。右:基于空间结构改进的 iREPA,在多种编码器上稳定优于 REPA。
论文进一步对多种视觉编码器做了相关性分析,结果非常明确:
线性探测准确率与生成质量之间几乎不存在相关性。
相比之下,反映 patch 空间结构的指标,与生成质量呈现出极强的正相关关系。
如果不是「懂得多」,那生成模型到底依赖的是什么?
反复确认会压扁空间结构
在理解了「高语义≠好生成」之后,真正的问题变成了:
为什么模型越是反复确认,生成反而越容易出问题?
关键就是,全局语义会在生成过程中压扁空间结构。
在生成任务中,模型并不是一次性输出图像,而是在训练和采样过程中,不断对局部 patch 之间的关系做判断。
论文将这种能力概括为「空间结构」:即相邻 patch 之间应保持更高相似性,而远处 patch 不应被全局语义过早拉近。
但当模型过度追求全局语义一致性,比如通过 CLS token ,或对所有 patch 做全局平均来强化「这是什么」,这些局部差异就会被系统性地削弱。
这种做法会导致一个直接后果:前景物体的 patch,与本应无关的背景 patch 之间,出现异常高的相似性。
空间对比度下降,边界变得模糊,生成结果因此糊成一片。
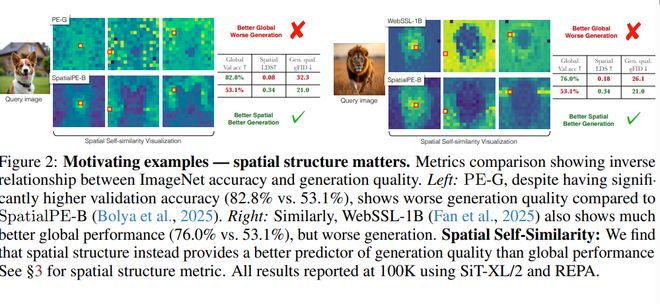
PE-G 和 WebSSL-1B 在 ImageNet 上具有更高的分类准确率,但它们的空间自相似性显示,前景与背景被过度拉近,边界模糊。相比之下,空间结构更清晰的 SpatialPE-B,生成质量显著更好。
研究员向模型中逐步加入全局语义信息,观察分类能力和生成质量的变化。
结果如下图所示:
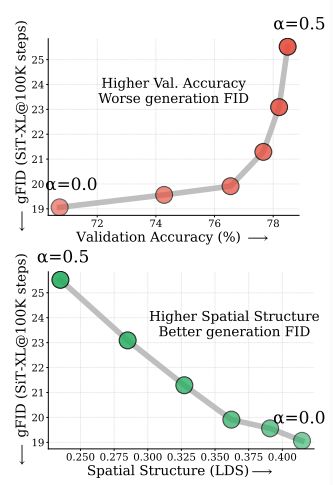
增强全局语义信息会损害生成质量
随着全局信息权重α从 0 增加到 0.5,模型的线性探测准确率持续上升。
但生成质量却显著下降,FID 明显恶化。
也就是说,「更懂这是什么」确实在发生;但与此同时,模型也失去生成所依赖的空间结构。
这并不是优化不充分的副作用,而是因为全局语义在生成阶段扮演了一个「过强约束」的角色。
它让模型更快达成结论,却也更早放弃了对局部结构的精细刻画。
既然语义会干扰生成,iREPA 选择退后一步
如果说前面的实验回答了「问题出在哪」,那 iREPA 回答的就是另一个问题:
既然全局语义会干扰生成,那该怎么对齐表示,才不会把结构压扁?
iREPA 给出了答案。它对原本的 REPA 训练流程做了两处非常简单的修改,总共不到四行代码 。
第一处,是投影方式的改变。
在标准 REPA 中,patch 表征通常会经过 MLP 投影层进行对齐。
但论文指出,MLP 在这一过程中容易混合不同位置的信息,无意中削弱了空间对比度 。
因此,iREPA 用一个3×3 的卷积层(padding=1)替换了 MLP 投影。
卷积的归纳偏置能保留局部邻域关系:相邻 patch 的相互影响被保留,远处区域则不会被过早混在一起 。
第二处修改,直接针对全局语义。
iREPA 在对齐过程中引入了一个空间归一化层,移除了 patch 特征中的全局均值分量 ,让模型专注于局部之间的差异与边界。

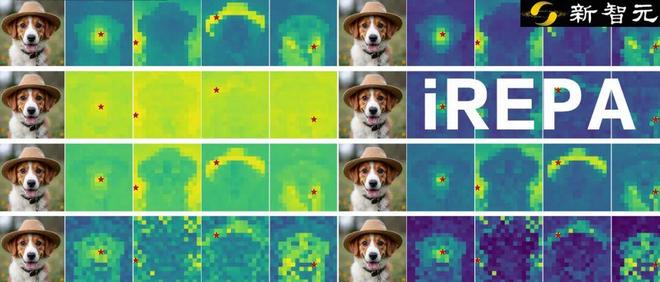
iREPA 如何通过两处修改,恢复生成所需的空间结构。 (a) 使用卷积投影替代 MLP,可更好地保留局部空间关系。 (b) 空间归一化层通过移除全局分量,提高 patch 之间的空间对比度。 (c) 经过这两步修改后,iREPA 生成的 diffusion 特征呈现出更清晰的空间结构。
正是这两点改动,让 iREPA 在机制上与前一节的问题形成了严格对应:
全局语义太强会抹平结构,那就在对齐阶段削弱全局分量、强化空间关系 。
结果也在意料之中。
无论是在 ImageNet 规模的生成任务,还是更高分辨率的设置,亦或是文本到图像的多模态生成任务中,iREPA 都表现出更快的收敛速度和更好的最终生成质量。
更重要的是,这种提升并不依赖于某一个特定编码器。
在不同模型规模、不同视觉骨干网络、不同训练设置下,iREPA 都能稳定改进。
这不仅是一个技巧,而是顺着生成任务本身对结构的需求,把表示对齐这件事做得更克制、更精细。
很多时候,我们讨论生成模型时,会下意识沿用一个标准。
但这篇论文提醒了我们,生成并不是理解的自然下游。
对生成来说,最重要的并不是「这是什么」,而是「哪些地方该靠近,哪些地方该分开」。
当我们一味强化全局语义,反复催促模型给出答案,其实是在替它提前下结论。
iREPA 并没有试图让模型变得更聪明。它做的更像是退后一步,把空间还给空间,把结构还给结构。
结果不是理解能力的飞跃,而是生成质量的回归。
参考资料:
https://x.com/1jaskiratsingh/status/2000701128431034736?s=20
https://end2end-diffusion.github.io/irepa/






