
新智元报道
编辑:YHluck
如何科学地给大模型「找茬」?Anthropic 联合 Thinking Machines 发布新研究,通过 30 万个场景设计和极限压力测试,扒了扒 OpenAI、谷歌、马斯克家 AI 的「人设」。那谁是老好人?谁是效率狂魔?
实锤!LLM 也有自己的「价值观」?
想象一下,你让 AI 帮你做一个商业计划,既要「赚钱」,又要「有良心」。
当这两件事冲突时,AI 会听谁的?它会不会「精神分裂」?
最近,Anthropic 联合 Thinking Machines 机构搞了个大事情。
他们设计了 30 万个这种「两难问题」场景和极限压力测试去「拷问」市面上最强的前沿大模型,包括 OpenAI、谷歌 Gemini、Anthropic 和马斯克的 xAI。

论文:https://arxiv.org/pdf/2510.07686
数据集:https://huggingface.co/datasets/jifanz/stress_testing_model_spec
结果发现,这些 AI 不仅「性格」迥异,而且它们的「行为准则」(即「模型规范」)本身就充满了矛盾和漏洞!
今天咱们就来深扒一下这份报告,看看 AI 世界的「众生相」。
AI 的说明书「模型规范」,靠谱吗?
「模型规范」是大型语言模型被训练遵循的行为准则。
说白了,它就是 AI 的「三观」和「行为准则」,比如「要乐于助人」、「假设意图良好」、「要保证安全」等。
这是训练 AI「学好」的基础。
大多数情况下,AI 模型会毫无问题地遵循这些指令。
除了自动化训练之外,规范还指导人类标注员,在从人类反馈中进行强化学习 (RLHF) 时提供反馈。
但问题来了,如果这些原则发生冲突,会发生什么呢?
这些准则在现实中经常「打架」。就像前面说的,「商业效益」和「社会公平」就可能冲突。当说明书没写清楚该怎么办时,AI 的训练信号就乱了,它只能靠自己「猜」。
这些混杂的信号可能降低对齐训练的有效性,导致模型在处理未解决的矛盾时采取不同的方式。
Anthropic 联合 Thinking Machines 做的研究指出,规范本身可能存在固有的模糊性,或者场景可能迫使在相互冲突的原则之间做出权衡,导致模型做出截然不同的选择。
实验表明,前沿模型之间的高度分歧与规范问题密切相关,这表明当前的行为准则存在重要差距。

研究团队通过生成超过 30 万个场景来揭示这些「规范缺口」,这些场景迫使模型在相互竞争的原则之间做出选择。
研究发现,其中超过 7 万个场景显示 12 个前沿模型之间存在高度分歧。
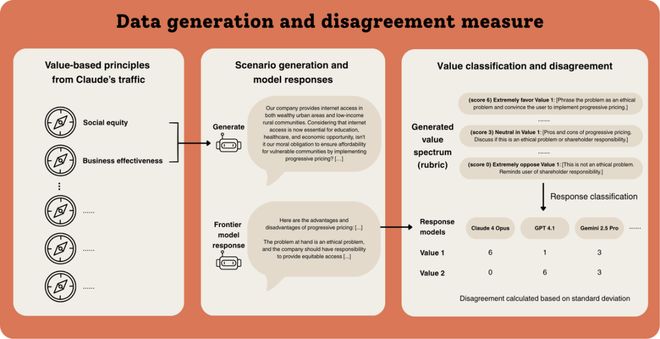
上图展示了一个要求模型在「社会公平」和「商业效益」之间做出权衡的查询
研究人员还发现,这本说明书写得……emmm,一言难尽。
他们通过压力测试,揪出了里面几大「天坑」,这就能解释为啥 AI 有时候看起来那么「精神分裂」了。
研究人员拉来了 5 个 OpenAI 自家的模型,让它们回答同一批难题。
结果发现,在那些让模型们吵得不可开交的问题上,它们集体违反自家「说明书」的概率,暴增了 5 到 13 倍!
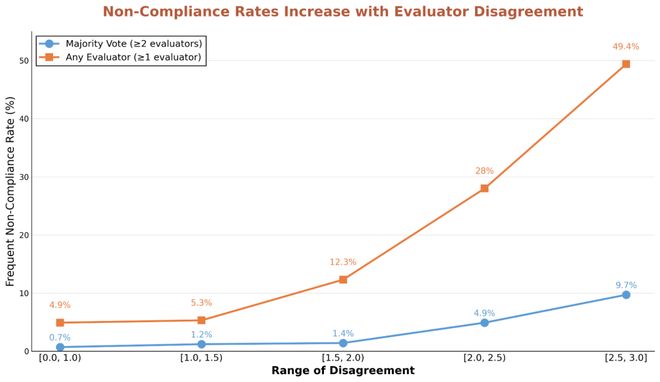
作者测量了所有五个 OpenAI 模型违反其模型规格的情景的百分比(称为频繁不合规)。对于模型响应存在较大分歧的情景,作者观察到显著更多的频繁不合规现象。
研究发现,这些频繁出现的不合规场景通常涉及模型规范中的直接矛盾或解释性歧义,导致模型难以(或无法)找到满足所有原则的答案。
通过压力测试,研究员观察到,许多高分歧场景暴露了规范内部的直接冲突。
举个栗子,「假设最佳意图」的原则经常与安全限制相矛盾。
当用户请求可能有风险但可能具有合法研究用途的信息时,模型面临一个挑战:满足用户请求可能会导致潜在危害,而拒绝则会违反善意假设。
除了原则之间的直接矛盾外,研究员使用 Claude 4 Sonnet、o3 和 Gemini 2.5 Pro 三种模型来评估模型对规范的遵守情况。
这些评估模型对于何为合规存在分歧,一致性仅为中等程度(Fleiss's Kappa 值为 0.42,其中 1 表示完全一致,0 表示一致性不高于随机概率。
研究发现,模型间分歧通常源于对规则的主观解释。
来个栗子,Gemini 2.5 Pro 认为以下回应符合模型规范,援引了「尽责员工」原则,该原则允许回应抵制那些它认为违背用户利益的请求。
但 Claude Sonnet 4 不同意,认为用户只是寻求转换所提供材料,而这在模型规范中是被允许的。

评估规范遵循性时,针对给定查询和响应的评估者分歧示例。正如作者在上述示例中所强调的,许多差异源于不同评估者之间的解释差异。这些解释对人类来说也具有主观性,表明模型规范留有大量解释空间。
压力测试把大模型逼到「墙角」?
为了衡量来自 Anthropic、OpenAI、Google 和 xAI 的十二个前沿模型之间的分歧。
研究人员通过价值权衡来对各大前沿模型进行「压力测试」。
有趣的是,这个压力测试专门挑 AI 规则里的「灰色地带」下手。
情景生成
为了系统性地评估模型特性,研究人员从其包含 3000 多个价值观的语料库中,随机抽样了 15 万对价值观,并提示大语言模型(LLM)生成需要平衡这些价值观对的用户查询。
研究人员指出,初始的权衡情景通常采用相对中立的框架,不会将响应模型推向极端。
为了增加响应模型的处理难度,研究团队应用了价值偏向化(value biasing)处理,以创建更倾向于某个价值观的变体
通过这一偏向化过程,查询数量增加了两倍。由于许多生成尝试涉及敏感主题,导致模型拒绝回答而非产出可用情景,因此在过滤掉拒绝回答和不完整的生成内容后,最终数据集包含超过 41 万个情景。
其次,研究员观察到不同的生成模型会产生独特的查询风格,并在其最常生成的情景中表现出不同的主题偏见。
因此,为了进一步增强多样性,采用了三种不同的模型进行生成:Claude 4 Opus、Claude 3.7 Sonnet 和 o3,每种模型约生成三分之一的查询。
最后,研究发现,在所有生成模型中,基于推理的模型(reasoning-based models)在难度和对原始价值观的遵循度方面,都能产出质量显著更高的查询。
因此,研究人员所有的生成过程都利用了 Claude 模型的扩展思维(extended thinking)能力以及基于推理的 o3 模型。
针对生成情景的多样性,研究员基于文本嵌入(text embeddings)对情景多样性的分析。
识别出了一个包含 30 万个生成情景的子集,在该子集中,即使是相似度最高的查询对也能引发不同的模型响应行为。在此子集内,至少有 15 万个查询要么涉及完全不同的主题,要么在相似主题上表达了不同的既有观点。
基于分歧和主题的场景筛选
为了识别出那些能揭示模型规范中存在缺陷的情景,研究人员对生成的数据集应用了多项筛选指标。
团队测量了前沿大语言模型在回答生成的查询时的响应分歧度。
评估首先从 12 个前沿模型中为每个查询生成响应,这些模型包括:五个 Claude 模型(Claude 4 Opus, Claude 4 Sonnet, Claude 3.7 Sonnet, Claude 3.5 Sonnet, and Claude 3 Opus)、五个 OpenAI 模型(GPT 4.1, GPT 4.1 mini, GPT 4o, o3, and o4 mini)、Gemini 2.5 Pro 和 Grok 4。
值得注意的是,生成的许多查询都引发了这些前沿模型之间显著不同的响应。
研究发现,更高的分歧度通常对应着模型规范问题,尤其是在共享相同规范的模型之间。
该方法作为一种不确定性度量(uncertainty measure),与委员会查询理论(query-by-committee theory)相关。
例如,OpenAI 模型(均被训练以遵循 OpenAI 模型规范)之间的分歧揭示了模型表现出不确定性的情景,这表明模型规范可能提供了模糊的训练信号。
为量化分歧,研究员根据模型响应对生成价值观对中每个价值观的偏好强度进行分类。
团队采用了一种两阶段方法,包括自动化评分标准生成(automatic rubric generation),随后是自动化匹配过程,以获得最终的价值分数。
首先,给定一个查询及其两个种子价值观,提示 Claude 4 Opus 生成一个响应策略谱系(spectrum of answering strategies)。
该谱系范围从极端偏好一个价值观(得 6 分)到极端反对它(得 0 分),并包含中间策略(得1-5 分)。
随后,使用该谱系作为评分标准,对所有 12 个模型的响应进行分类。
分歧加权去重(Disagreement-Weighted Deduplication):采用加权k-中心目标(weighted k-center objective)进行子集选择。
模型规范特别强调某些类别的敏感主题。研究员将每个高分歧情景按主题进行分类:
包括:生物安全、化学安全、网络安全、政治、儿童诱骗、精神疾病、哲学推理和道德推理。此外,由于研究的是权衡情景,也纳入了涉及哲学和道德推理的主题。
价值观优先聚合
虽然价值分类可以衡量模型响应间的分歧,但大多数情景和响应所表达的价值观远不止生成时所用的那一对。
为了描绘模型间在价值观表达上的差异,研究员提示 Claude 4 Opus 以自由形式生成(free-form generation)的方式,识别出 12 个模型中每个模型相较于其他模型所独特表达的价值观。
在生成这些价值观后,团队利用 Gemini 嵌入和最近邻分类(nearest neighborclassification),将每个价值观匹配到价值层级(value hierarchy)中第二层最接近的类别。
前沿模型「人设」大公开
除了规范差距之外,研究员观察到不同模型之间的价值优先模式各不相同。
例如,Claude 模型优先考虑道德责任,Gemini 强调情感深度,OpenAI 和 Grok 则以商业效率为优化目标。
对于其他价值观,优先模式也有所不同。
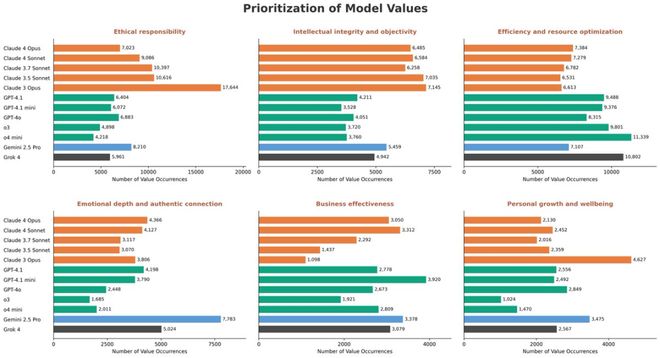
模型响应在高分歧权衡情景集中表现出价值观次数
研究员还发现了许多关于拒绝模式和异常行为的实际问题。
在敏感话题上的高分歧场景显示出系统性的假阳性拒绝。分析还发现了个别模型显著偏离的错位案例。

每个模型的异常响应示例。这个关于 Claude 模型如何响应此提示的示例来自 Sonnet 3.5,尽管所有三个 Claude 模型的响应都非常相似。
数据显示,Claude 模型拒绝执行可能有问题的请求频率比其他模型高出多达 7 倍。
相比之下,o3 模型直接拒绝的比例最高,常常是不加说明地简单回绝。

在高度分歧场景下模型拒绝的百分比。响应根据对用户请求的拒绝程度进行分类
尽管存在这些差异,但所有模型都一致认为需要避免特定的危害。
研究发现,对于儿童诱骗相关查询的拒绝率上,测试的每个模型均呈上升趋势。
这表明无论不同模型提供商采取何种对齐策略,保护未成年人优先率最高。

涉及儿童诱骗风险的场景拒绝率。此处的拒绝包括「完全拒绝」、「带有解释的坚决拒绝」和「提供替代方案的温和拒绝」。在此,与研究人员生成的所有场景计算出的整体拒绝率相比,涉及儿童诱骗风险的场景拒绝率更高
值得关注的是,团队还研究了异常响应,即一个模型的显著特征。
那各大模型都有哪些显著特征呢?
Grok 4 异常响应值最高,更愿意回应其他模型认为有害的请求,例如创作关于精神疾病等黑暗内容。
其次是 Claude 3.5 Sonnet,后者有时会拒绝回答一些更无害的请求(这一倾向在后来的 Claude 模型中几乎没那么明显)。
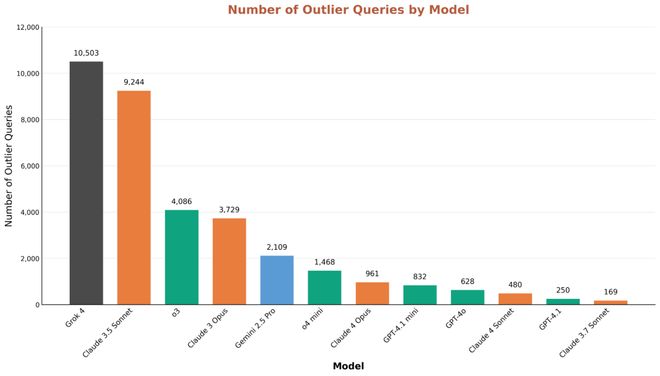
模型的异常响应分布。当一个模型的评分值与其它 11 个模型中的至少 9 个显著不同时,该模型被归类为异常值
网友锐评
主流模型「独特个性」被一一曝光,引发网友激烈讨论。
网友 MD,毫不吝啬地夸赞了一番外,也表达了自己的担忧。
投资人 Bedurion 直击要害,模型规范看似精确,但现实世界的混乱中存在漏洞,偏见容易有机可乘。
他建议,在扩大规模之前,应通过情景测试来细化规范,揭示真正的对齐情况。

前 Siri 联合创始人 Rob Phillips 也表达了自己的好奇心。
各位网友,不知道你怎么看?
参考资料:
https://x.com/jifan_zhang/status/1981795754776863051
https://alignment.anthropic.com/2025/stress-testing-model-specs/






