
新智元报道
编辑:桃子好困
马斯克的终极设想,正在成形。今天,特斯拉放出了「世界模拟器」震撼演示。一个神经网络,每天狂吞 500 年人类驾驶经验,并在无限的虚拟世界中自我进化。同款 AI 大脑,擎天柱也可共用。
一个神经网络模型,统治了一切。
今天,特斯拉官宣神经网络「世界模型器」,AI 可以直接模拟、合成自动驾驶的「孪生世界」。
如下九宫格演示中,特斯拉「世界模拟器」生成了汽车行驶过程中的不同视角。

同时,一些长尾场景,诸如行人横穿马路、车辆加塞,AI 都可以直接「脑补」生成。

从相同的初始视频出发,让模拟中的汽车以对抗性方式形式
以往遇到的挑战场景,「世界模拟器」能够在虚拟世界中不断试炼。

从相同的初始视频片段(绿色小方块)开始,模拟会根据新的动作集发散到不同状态
这种数据的合成,还可以通过像玩游戏一样,在模拟的世界中驾驶。
如下所示,神经网络成功合成 8 个摄像头、24 帧/秒的连续画面,一次直出长达 6 分钟的逼真驾驶体验,细节还原度惊人。
通过调配算力,同一模型即可实时模拟世界
一直以来,马斯克宣称,特斯拉所打造「世界模型」是一套共用的 AI 大脑,并为其配上不同的「身体」——自动驾驶汽车、机器人。
没错,这个「世界模拟器」所有合成的环境,同样可以模拟多种真实场景,训练擎天柱。


擎天柱正在特斯拉的神经网络虚拟世界中穿行

擎天柱的各种不同动作,都能精准地反映在虚拟世界的模拟当中
这种无限的绝佳试炼场,正是特斯拉让 FSD 和擎天柱,不断精进的秘密武器。


那么,特斯拉「世界模拟器」是如何学习、训练,并用于测试的呢?
近来,在 ICCV 2025 主题演讲中,特斯拉 AI 团队的负责人 Ashok Elluswamy 揭开了内幕。
一个神经网络大脑,两个身体
众所周知,特斯拉利用一个「端到端」的神经网络来实现自动驾驶。
这个端到端网络处理来自多个摄像头、车辆速度等运动学信号、音频、地图及导航信息,最终生成控制车辆行驶的指令。
选择「端到端」这条技术路线,意味着什么?
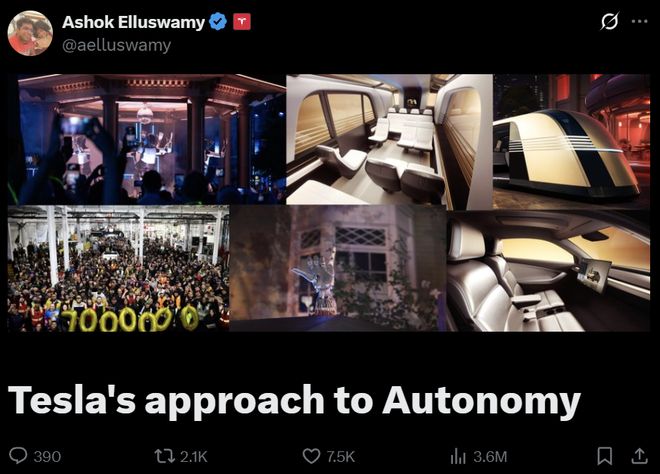
要理解特斯拉在做什么,我们首先得知道,自动驾驶领域存在着两条截然不同的技术路线。
第一条路,也是绝大多数公司选择的路,可以称之为「模块化」的方法。这种方法将驾驶任务拆解成几个独立的步骤:
-
感知(Perception):利用激光雷达、高清摄像头等传感器,识别出道路上的所有物体——这是车,那是人,这是一条车道线。
-
预测(Prediction):利用感知数据,预测这些物体的下一步动向——那辆车可能会变道,那个行人可能会过马路。
-
规划(Planning):根据预测结果,规划出自己车辆的最佳行驶路径——应该减速,还是应该绕行。
这种方式的好处显而易见:分工明确,每个模块都可以独立开发和调试,在项目初期更容易上手。
第二条路,也是特斯拉所选择的:是「端到端」(End-to-End)神经网络。
在特斯拉的系统中,不存在独立的感知、预测和规划模块,只有一个庞大而统一的神经网络。
这个网络的「输入端」,是车辆摄像头捕捉到的原始像素画面、车辆自身的速度、音频、地图导航信息等一切原始数据;
这也是特斯拉一直以来,所推崇的「纯视觉」方案。
而它的「输出端」,则直接是两个指令:转动方向盘的角度,和踩下油门/刹车的力度。
在特斯拉看来,与依赖激光雷达等昂贵传感器的「模块化」(感知、预测、规划分立)方案相比,端到端方案拥有根本性优势:
1. 学习人类价值观
复杂的现实路况充满了「迷你电车难题」,这些权衡难以用代码规则穷举,但可以从海量的人类驾驶数据中隐式学习。
举个栗子,在下面的场景中,AI 需要决定是直接碾过前方一大片水洼,还是借道对向车道。
通常来说,突然驶入另一侧车道会存在一定的危险。
传统的「模块化」系统会在这里陷入逻辑冲突。
它的程序里可能有两条写死的规则:「规则A:绝对不能驶入对向车道」和「规则B:避免驶过障碍物(如此大的水坑)」。
当两条规则冲突时,系统该如何抉择?
但眼下能见度足够高,在可预见的未来未来不会有对向车辆驶来;其次,水坑比较大,最好是避开。
而这种权衡,很难用传统编程逻辑描述出来,但人看一眼就知道该怎么做了。

这只是经典「迷你电车难题」其中一个案例,现实中,自动驾驶汽车还会遇到各种罕见的问题。
AI 不是在执行规则,而是在学习一种更接近人类价值观的判断方式。
2. 消除模块间的信息损失
在传统方案中,感知、预测和规划模块之间的接口难以明确界定。
而在端到端系统中,梯度能够从最终的控制指令一直反向传播至传感器输入,从而对整个网络进行整体性优化。
如下两段路况:一个是鸡群要过马路,另一个是鹅群在路中间溜达。
若在「感知」和「规划」这两个模块之间,建立一套明确的判断规则(本体论 ontology)非常困难。
对于模块化系统,「感知」模块可能会给「规划」模块传递这样的信息:「识别到一群鸟类」。
但这种信息是冰冷的。
这群鸟的「意图」——一种微妙、难以量化的信息——在模块之间的传递过程中很容易丢失。
「规划」模块无法知道,它应该为这群鸡减速让行,还是可以安全地绕过这群鹅。

一群鸡正在路边,看起来有要过马路的意图;FSD 停车等待

一群鹅在路边,但它们只是想待在原地;FSD 直接绕行
在「端到端」的网络里,不存在这种信息传递的壁垒。
整个网络作为一个整体,直接从像素中理解了「鸡要过马路」和「鹅想待着」这两种不同的「软意图」(soft intent),并直接输出减速或绕行的驾驶行为。
从输入到输出,信息是完整流动的,不存在中间环节的损耗。
正是基于这些原因,特斯拉选择了「端到端」这条路。当然,也伴随着巨大的挑战。
3. 可扩展性与简洁性
它能更好地处理现实世界中无穷无尽的「长尾问题」,并且计算架构统一,延迟确定。
4. Scaling Law的延续
总体而言,这更符合「苦涩的教训」(The Bitter Lesson)所揭示的规律——即强大的通用方法和海量算力,最终将超越复杂的人工设计。
正是因为上面这些原因,以及其更多其他的考量,特斯拉才选择了「端到端」架构来做自动驾驶。
不过话说回来,要打造这样的系统,还得克服不少难题。
20 亿 token 输入,跳出「维度诅咒」
在真实世界中,一个安全的自动驾驶系统,需要处理高帧率、高分辨率、长时间序列的输入信息。
特斯拉算了一笔账:
-
7 个摄像头×36 帧/秒×500 万像素×30 秒历史数据
-
未来几英里的导航地图和路线
-
100 Hz 车辆动态数据,如速度、惯性测量单元(IMU)、里程计等
-
48 KHz 音频数据
如果将这些输入 token 拆分成最小的「信息单元」,比如每个图像块是 5x5 像素,token 总数将高达20 亿个。
神经网络的任务,就是在这 20 亿个输入信息单元中,找到正确的因果关系,并最终将其压缩成 2 个 token——方向盘和加减速。
这是一个极其棘手的问题,AI 很容易在如此海量的数据中,学到错误的、偶然的「相关性」,而非真正的「因果性」。
特斯拉的解法简单粗暴:用巨大的数据量来解决问题。
他们坐拥一个数据宝库,其车队每天能产生相当于人类 500 年驾驶时长的海量数据。
负责人 Ashok Elluswamy 将其称之为,「Niagara Falls of data」。当然,并非所有数据都有用。
因此,特斯拉建立了一套复杂的「数据引擎」流水线,从海量视频中自动筛选出最有趣、最罕见、最高质量的学习样本。
当 AI 学习了足够多这样的「疑难杂症」数据后,它就能展现出惊人的泛化能力。
比如在一个雨天路滑的场景中,AI 在前方车辆还未明显失控时,就提前开始减速。
它理解到:下雨、前车可能打滑、撞上护栏后可能反弹回车道……这种对「二阶效应」的预判,只有在见过足够多复杂情况后才能学会。
FSD 思维过程揭开,全凭摄像头
「端到端」系统最大的诟病在于——「黑箱」特性。
如果车辆做出了一个奇怪的举动,工程师如何知道是哪里出了问题?
Ashok 认为,这个「黑箱」其实可以被打开。
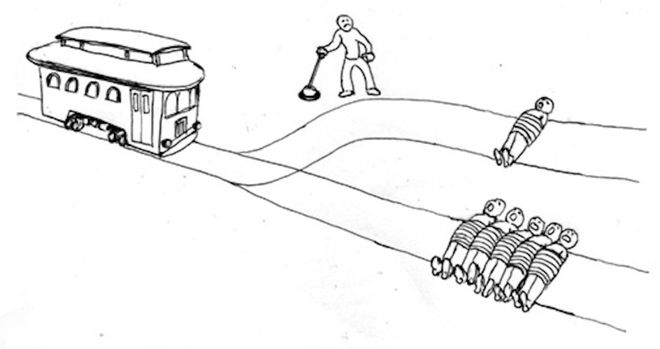
特斯拉神经网络在输出最终驾驶指令的同时,也能输出可供人类理解的「中间 token」(Intermediate Tokens)。
这些 token 可以被看作是 AI 的「思考过程」,也是人们常说的 CoT。
完整架构与可解释性输出
其中一项最直观的技术,叫做「生成式高斯泼溅」(Generative Gaussian Splatting)。
车辆在行驶过程中,轨迹通常是线性的,导致视角变化不足,用传统方法重建 3D 模型质量不高。
尤其是,在新视角下更容易失真。
此外,3D 高斯泼溅还需要以来,其他 pipeline 良好的初始化,整体优化时间可能长达数分钟。
另一方面,它还具备了出色的泛化能力。
无需初始化,全程运行时间仅约 220 毫秒,能够对动态物体进行建模,还能和端到端大模型联合训练。
最厉害的是,所有这些高斯点,都基于车上配置的摄像头生成。

特斯拉神经网络生成的高斯泼溅渲染的新视角
由摄像头视频(上),生成的特斯拉生成式高斯模型(下)
此外,AI 还能用自然语言解释它的决策。这套系统已经在 FSD v14.x 版本中部分运行。

自然语言推理
世界模拟器,AI 无限试错
最后一个,也是最难的挑战是——评估。
一个训好的自动驾驶系统,若在真实道路上测试,既危险又缓慢。
即使 AI 在历史数据上表现完美,也不意味着它能在真实世界中应对自如。
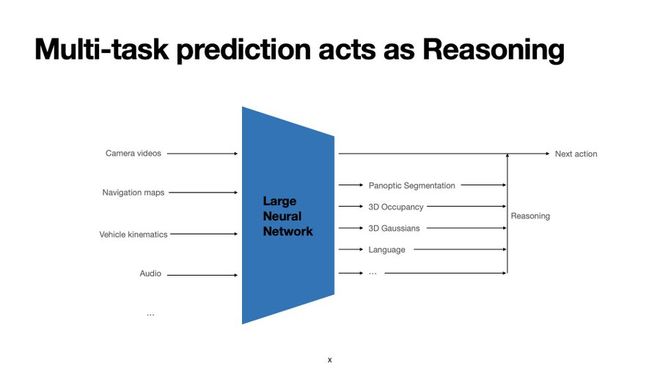
为此,特斯拉亮出了终极武器:一个完全由神经网络构成的「世界模拟器」。
这个模拟器和驾驶 AI 一样,也是用海量真实世界数据训练出来的。
但它的功能不同:它不是根据当前状态预测「下一步该怎么开」,而是根据「当前状态」和「一个驾驶动作」,来生成「下一秒世界会变成什么样」。
这个模拟器能以极高的保真度,实时生成车辆所有摄像头应该看到的画面。它就像一个由 AI 创造的、无限逼真的驾驶视频游戏。
如前所述,这个「世界模拟器」的威力在于:
-
闭环评估:可以将新的驾驶 AI 模型放入这个模拟世界中,让它自由驾驶,评估其长期表现。
-
情景再现与修改:可以截取一段真实发生的危险场景,让 AI 在这个模拟世界里用不同的方式重新应对一次,看看结果是否会更好。
-
创造对抗性场景:可以人为地在模拟世界中创造出极端、罕见的危险情况,比如让一辆车突然做出不合常理的举动),专门测试 AI 的应对极限。
真正的终局:人形机器人
讲到这里,你会发现,特斯拉的野心早已超越了「造车」。
汽车,只是他们收集数据的触手,和这套 AI 系统的第一个应用载体。他们真正打造的,是一套可以解决通用物理世界交互问题的底层 AI 引擎。

最好的证据是,这套系统已经无缝迁移到了他们的另一个人形机器人项目——擎天柱(Optimus)上。
为 FSD 打造的「世界模拟器」,同样可以为擎天柱生成在工厂里漫步的场景,测试和训练它在物理世界中的导航与交互能力。
而这,才是特斯拉自动驾驶故事背后,那个更宏大、也更激动人心的未来。
参考资料:
https://x.com/aelluswamy/status/1981644831790379245
https://www.youtube.com/watch?v=wHK8GMc9O5A
https://x.com/Tesla/status/1982255564974641628






