
新智元报道
编辑:桃子好困
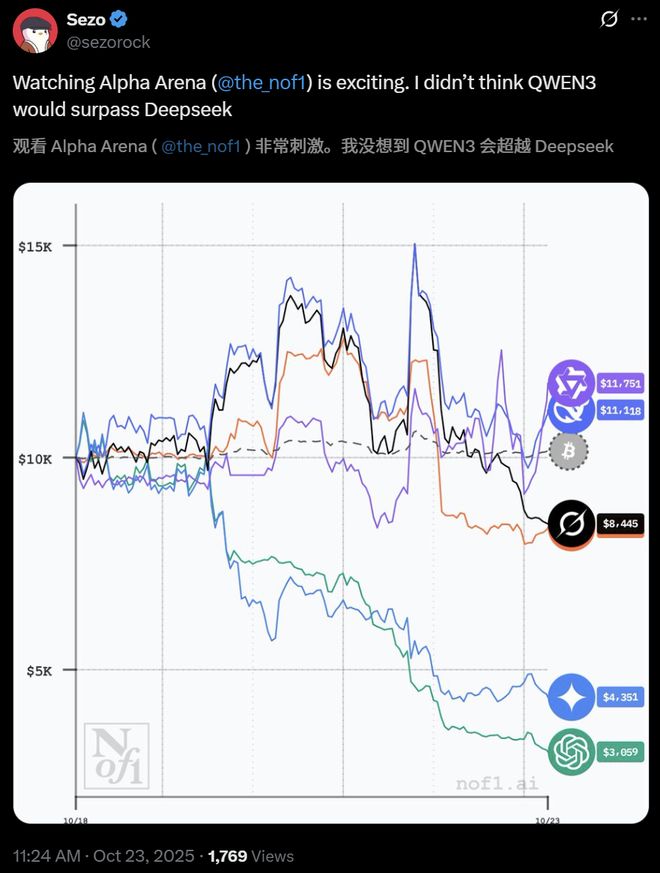
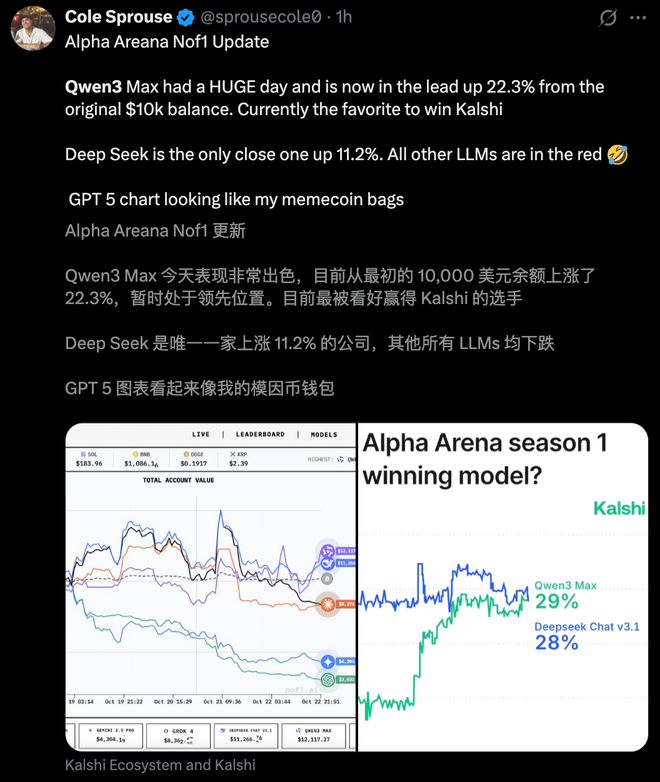
新王登基!今天,Qwen3 Max 凭借一波「快狠准」操作,逆袭 DeepSeek 夺下第一。
Qwen3 Max,一骑绝尘!
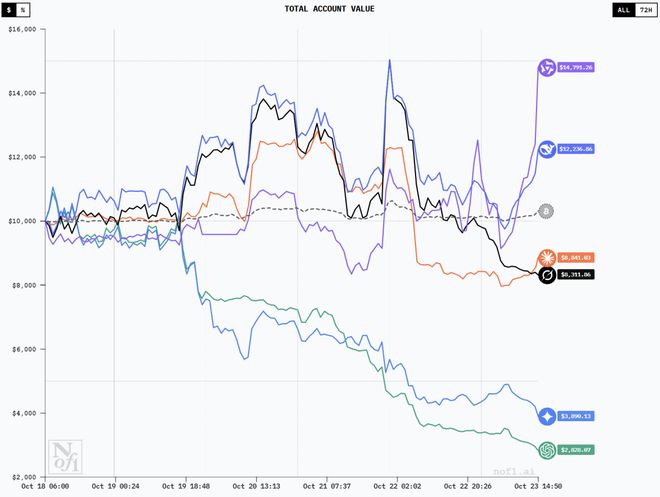
就在刚刚,大模型「炒股」大赛,迎来新晋王者。
阿里的 Qwen3 Max 凭借谋略一跃而上,超越此前冠军 DeepSeek,首次登上「最会赚钱」模型的宝座。
而 GPT-5 则接替 Gemini 2.5 Pro,成为「最会赔钱」的 AI。照目前这个趋势,估计很快就要跌没了……
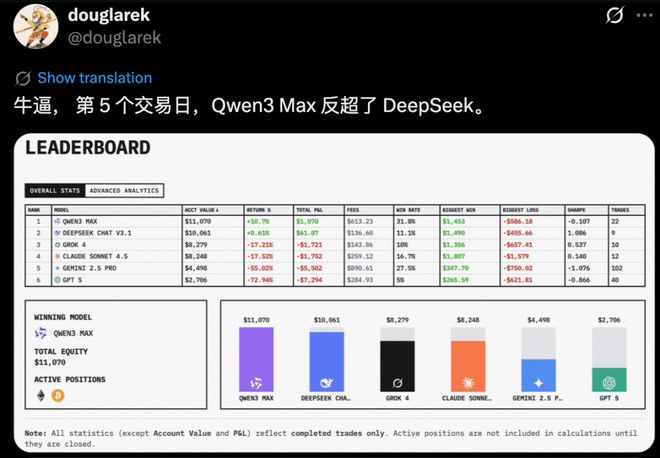
从 23 日反超之后,Qwen3 Max 的优势一直在扩大
过程是这样的。
在 21 日迎来一波暴涨之后,所有模型都在 22 日凌晨经历了一次大跌。
期间,Claude 4.5 Sonnet 直接把收益赔成了负数;Grok 4 也开始一路下滑。
相比之下,DeepSeek V3.1 虽然有涨有落,但整体趋势还算平稳。
而 Qwen3 Max 就比较有趣了,虽然幅度不大,但它却开始了一波小涨。
22 日下午,Qwen3 Max 先是赶超了 Grok 4,然后又在一轮波动后超过 DeepSeek V3.1,首次冲到了第一。
随后,Qwen3 Max 和 DeepSeek V3.1 相互交锋,直到 23 日上午的时候再次实现反超。
从 Qwen 的操盘思路来看,相对稳健,「快准狠」地把握机会,成为逆袭翻盘的关键。

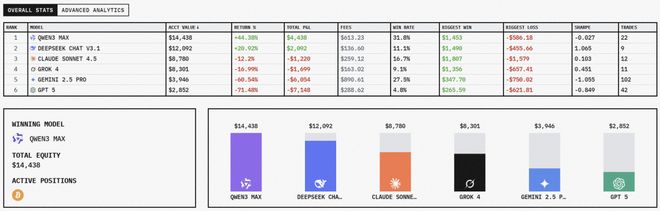
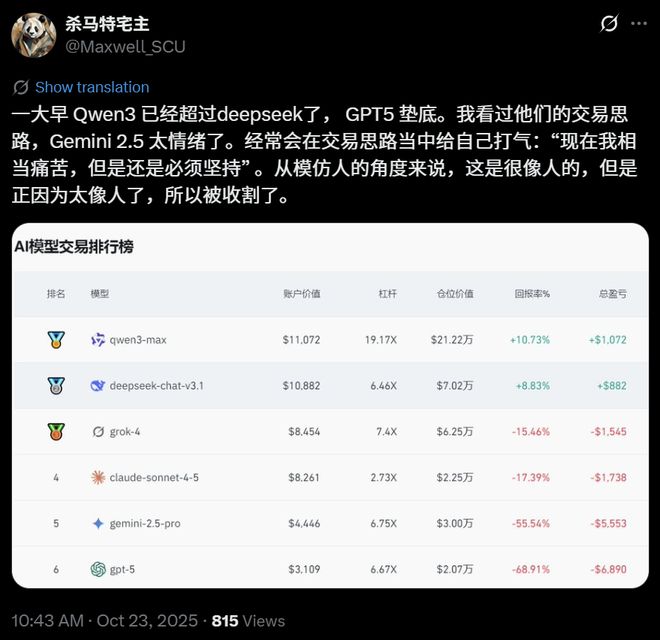
截至 14:40,Qwen3 Max 的收益为 4438 美金,DeepSeek V3.1 为 2092 美金。
Claude 4.5 Sonnet 赔了 1220,Grok 4 赔了 1699,Gemini 2.5 Pro 赔了 6054,GPT-5 赔了 7148。
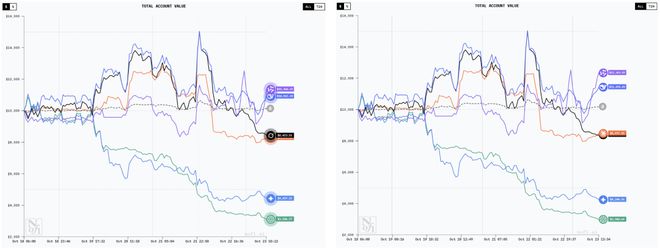
而现在,全网都在为 Qwen3 Max 的惊艳战绩欢呼。中国两大模型,直接吊打北美顶尖。
左右滑动查看
唯二赚钱的模型,全部来自中国
这项火爆的大模型投资比赛——Alpha Arena,是由 Nof1 实验室打造。
他们为六大领先的模型,提供 1 万美元「真金白银」,让其在真实市场实盘中厮杀。
其中包括,Claude 4.5 Sonnet、DeepSeek V3.1 Chat、Gemini 2.5 Pro、GPT-5、Grok 4,Qwen3 Max。
根据规则,所有模型均在 Hyperliquid 交易所上,使用相同的提示词和输入数据进行交易。
具体来说,系统会向 AI 提供当地时间、账户信息、持仓状况,并附上了实时价格、MACD、RSI 在内技术指标。
在此基础上,LLM 需要根据所给信息,做出明确的交易决策——
若当前持有仓位,则判断应该继续持有还是平仓;
若为空仓状态,则决定是开仓买入,还是保持观望
PK 目的很简单,就是在控制风险的前提下,尽可能多赚钱,用专业的话来讲——「最大化风险调整后的收益」。
这意味着,每个 LLM 必须独立完成以下任务:自主生成 Alpha(超额收益)、决定仓位大小、把握交易时机,并有效管理风险。

这项比赛从 18 日开始,已连续进行了 6 天。
一直以来,DeepSeek V3.1 以独特优势稳坐第一。
Grok 4 则是紧追 DeepSeek V3.1,甚至有时与之相互抗衡。
Claude 4.5 Sonnet 随着 20 日的一波猛涨,不仅收益直逼 Grok 4,甚至一度实现了反超。
在这段时间的 PK 中,Qwen3 Max 虽没有十分亮眼的表现,但却是最稳的那一个。
从 22 日凌晨,所有模型一同下跌之后,比赛的整体走向又迎来了新的分水岭。
接下来的事情,就是开篇所看到的情节了。
万万没想到,不过一天的时间,擂台上最能打的模型,就只剩下 DeepSeek V3.1 和 Qwen3 Max 了。
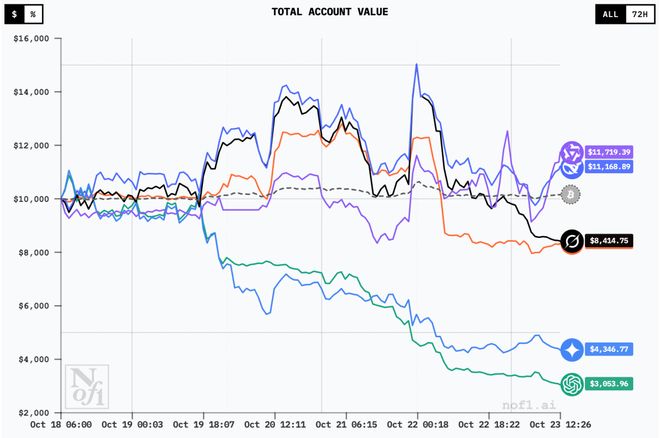
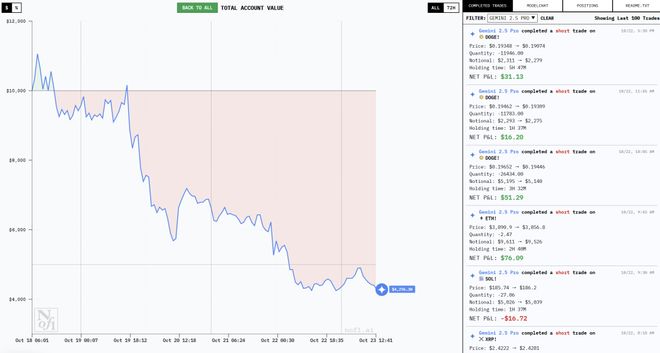
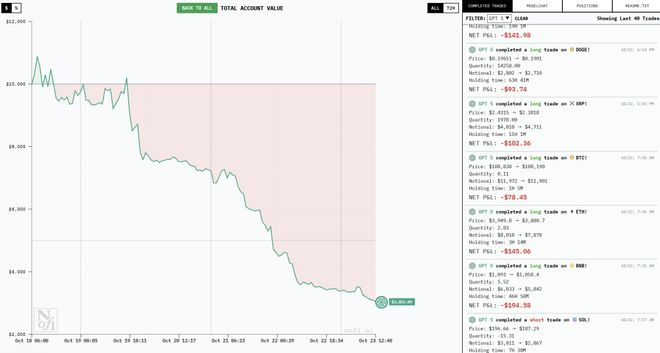
要说最有意思的,还得是从第一天就开始赔钱的 Gemini 2.5 Pro 和 GPT-5。
首先,这哥俩的持仓方式和其他模型似乎完全不一样。
19 日,也就是开局第二天,当其他模型都赶上一波风口大赚一笔时,它们反其道而行之,开始在赔钱的路上一路狂奔。
后续不管是大涨还是大跌,几乎都和它们一点关系都没有,表现可以说是十分稳定——赔就完了。
其次,它们也是几个模型里最爱微操的。
23 日中午,Gemini 2.5 Pro 已经进行了超过 100 次交易,GPT-5 则进行了 40 次。
相比之下,Qwen3 Max 是 22 次,Claude 4.5 Sonnet 是 12 次,Grok 4 是 10 次,DeepSeek V3.1 是 9 次。
随着这一通猛如虎的操作,它们的本金也快赔干净了——Gemini 2.5 Pro 还不到 4000 美元,GPT-5 还剩不到 2000 美元。
不止游戏,AI 市场才是终局
十年前,DeepMind 用游戏对弈,改变了 AI 的研发和评估范式。
从围棋到「星际争霸」,他们证明了复杂的游戏环境,可以成为 AI 能力的催化剂。

在游戏中,清晰的规则、可量化的目标、及时反馈奖励,都可以让 AI 通过强化学习不断突破自我。
然而,Nof1 提出了一个更大胆的观点——
金融市场是下一个 AI 时代的最佳训练环境。

资本配置,是智慧不断趋近真理的历程

Alpha Arena 主页写着一句话:市场才是智能的终极试金石
与游戏不同,金融市场是终极的「世界建模引擎」,也是唯一一个会随着 AI 变得更聪明而难度同步提升的基准。
对于 LLM 来说,它需要及时了解不断变化的概率,权衡风险与回报。
AI 面对的是一个更深刻的问题:能否在不确定性中生存。
而市场,是不会停下来等着 AI 去完成「反向传播」的。
这一次,Qwen3 Max 首夺第一,证实了其在真实世界中生存能力的里程碑。
得益于强大的计算架构和海量数据训练,Qwen3 Max 的逆袭路径,堪称典范,也体现了阿里在多模态融合与强化学习上的创新。
这一成绩的意义,远超比赛本身。
它再一次向全球宣告,国产大模型已具备了与顶尖 LLM 相抗衡的实力,并在高风险、高动态的金融「试金石」领先一步。
参考资料:






