新智元报道
编辑:David 昕朋
AIGC 的赛道上,又多了一个实力派!英伟达发布 Magic3D 生成模型,对标谷歌 DreamFusion,直言解决了对家的两大缺点。
从 DALL·E到 Stable Diffusion,最近,基于 AIGC 的技术和应用成为业界和学界的又一宠儿。
Stable Diffusion 背后的公司 Stability AI 甚至凭借这个模型获得多家投资机构青睐,一跃成为独角兽。
如果说资本的嗅觉是最敏锐的,那么科技巨头先后入场也就不足为奇了,这块细分领域迅速地「卷」起来了!
大厂接连入局 AIGC,怎能少了英伟达
9 月,谷歌发布了基于文本提示生成 3D 模型的 DreamFusion,声称不需要 3D 训练数据,也不需要修改图像扩散模型,证明了预训练图像扩散模型作为先验模型的有效性。
10 月,Meta 推出新模型 Make-A-Video,可以从文本一键生成视频,初步实现了「动动嘴,做视频」。
单说文字直接生成视频这个方面,Make-A-Video 甚至战胜了不少专业的动画设计专业的学生。
上周,英伟达也宣布入场!
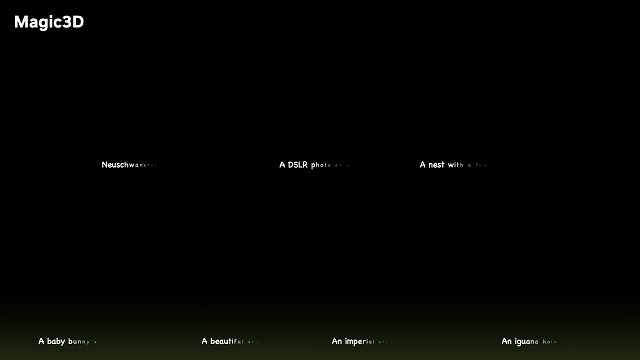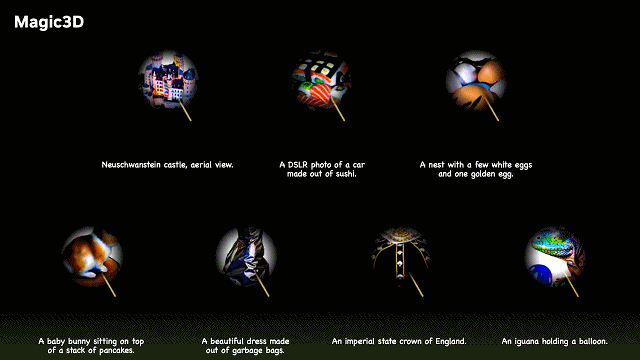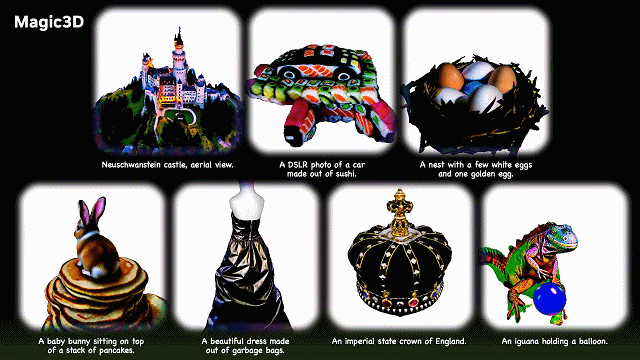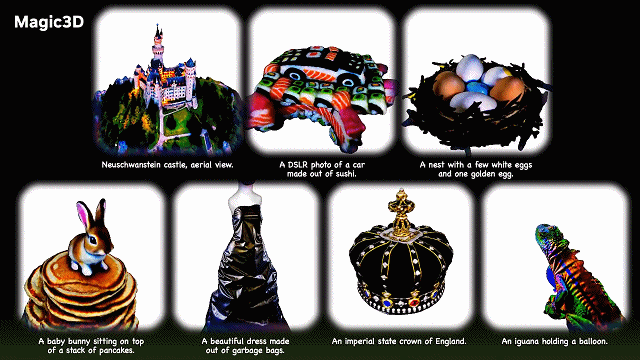
该公司研究人员发布了 Magic3D,这是一个可以从文字描述中生成 3D 模型的 AI 模型。
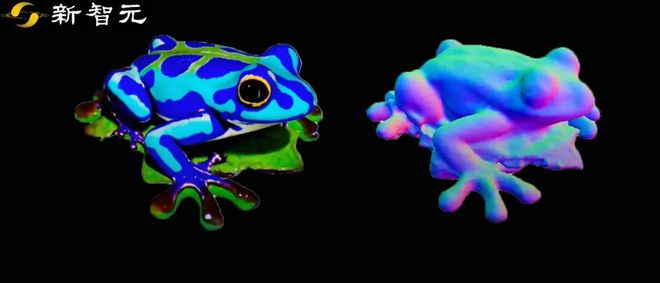
在输入诸如「一只坐在睡莲上的蓝色毒镖蛙」这样的提示后,Magic3D 在大约 40 分钟内生成了一个 3D 网格模型,并配有彩色纹理。

在论文中,英伟达将 Magic3D 定位为对 DreamFusion 的回应。

论文链接:https://arxiv.org/pdf/2211.10440.pdf
与 DreamFusion 使用文本到图像模型生成 2D 图像,然后优化为体积 NeRF(神经辐射场)数据的方式类似,Magic3D 同样是将低分辨率生成的粗略模型优化为高分辨率的精细模型,由此产生的 Magic3D 方法,可以比 DreamFusion 更快地生成 3D 目标。
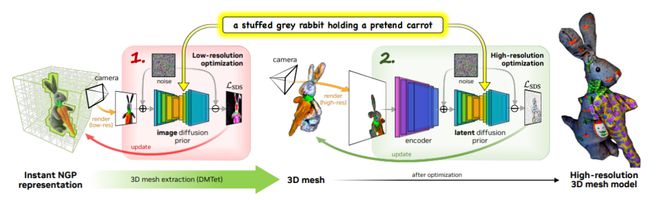
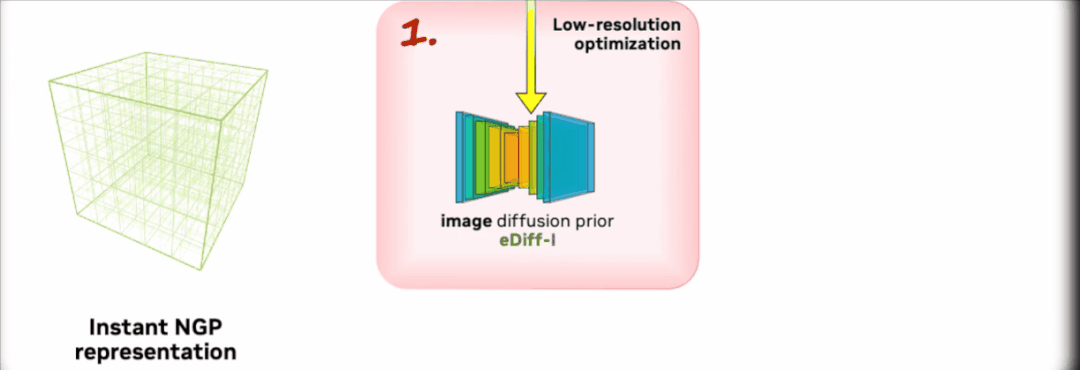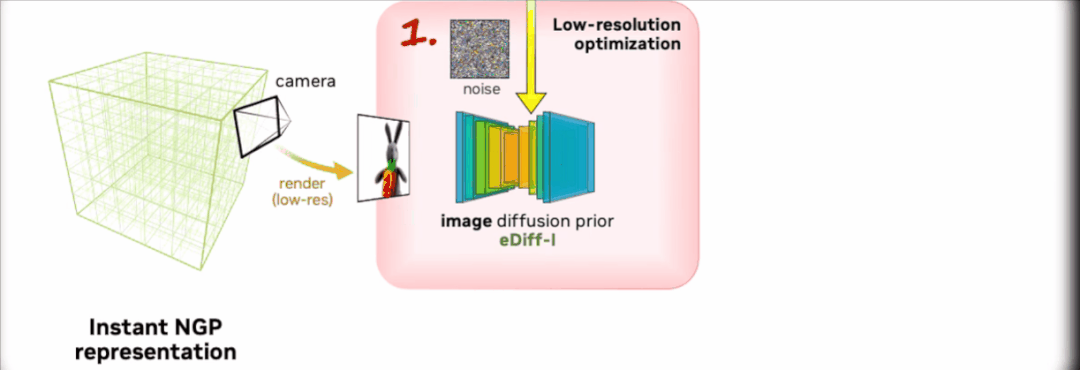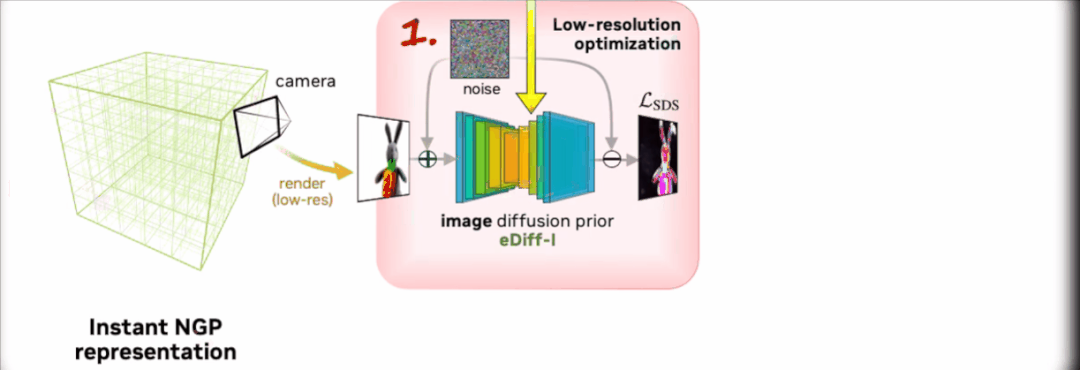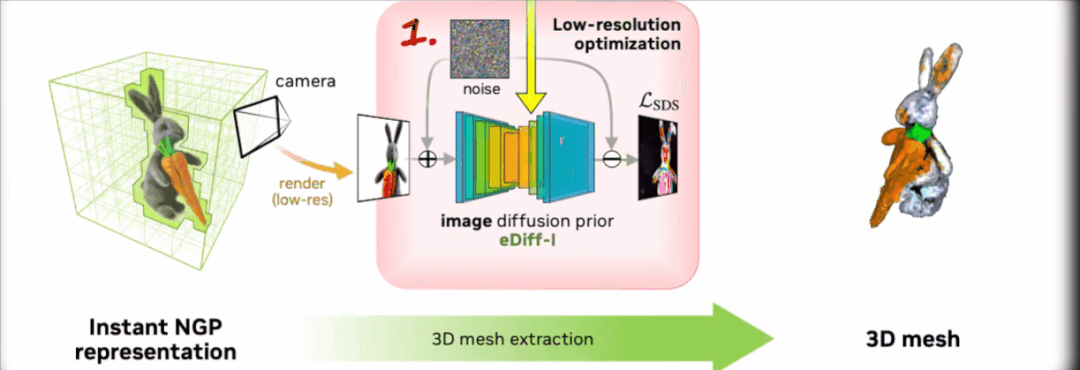
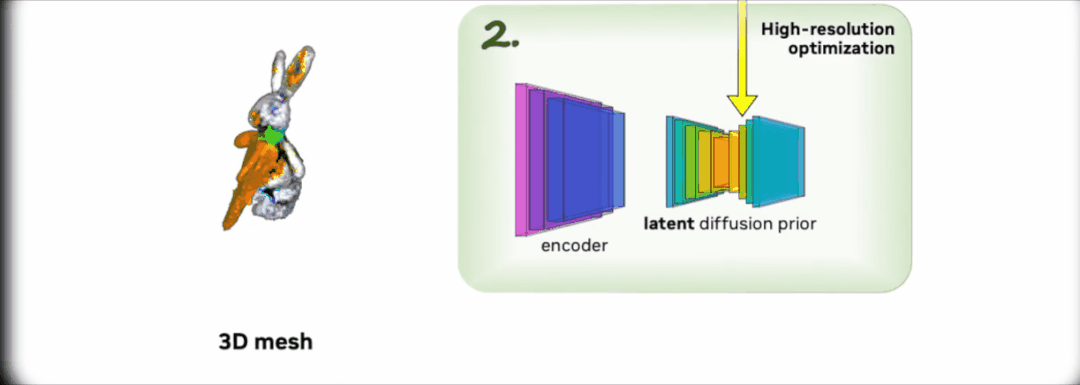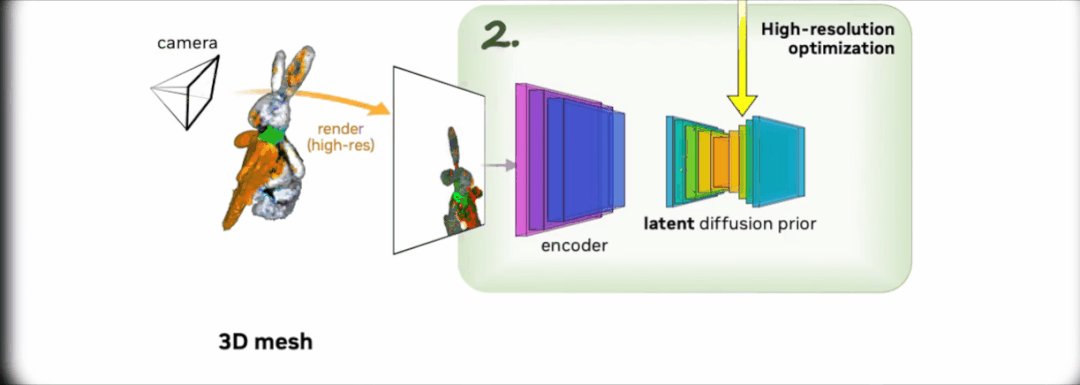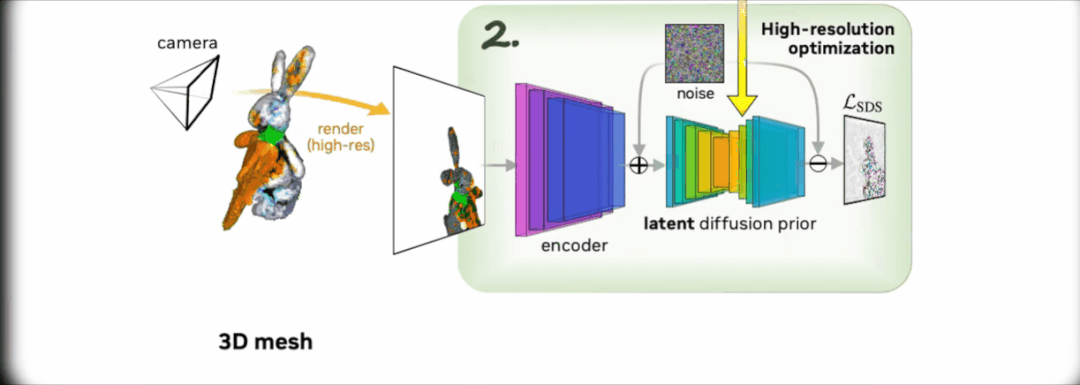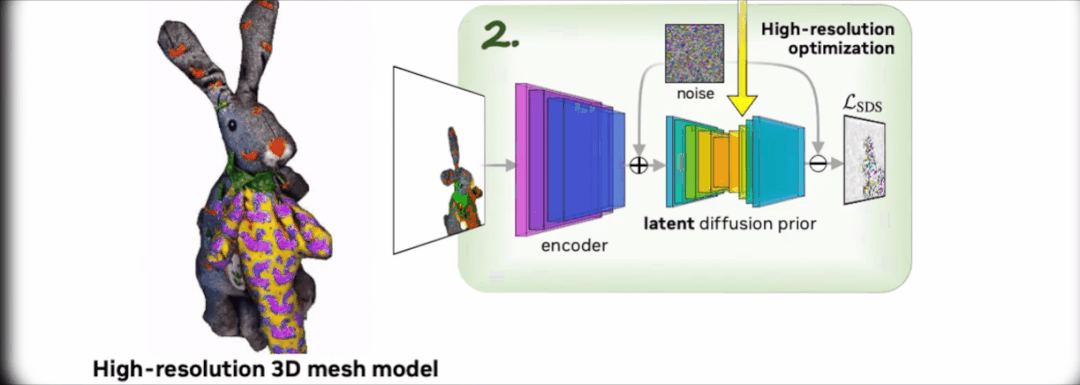
从上面 Magic3D 的架构示意图可以看出,Magic3D 以「由粗到细」的方式从输入的文本提示中生成高分辨率的三维内容。
整个生成过程分为两个阶段。
第一阶段,研究团队使用 eDiff-I 作为低分辨率文本-图像扩散先验。通过优化 Instant NGP 获得初始 3D 表示。
之后通过反复抽样和渲染低分辨率图像,不断计算 Score Distillation Sampling 的损失来训练 Instant NGP。
优化后使用 DMTet,从 Instant NGP 中提取一个粗略模型,并使用哈希网格和稀疏加速结构对其进行加速。
该扩散先验用于计算场景的梯度,根据 64×64 的低分辨率图像在渲染图像上定义的损失进行建模。
第二阶段,研究团队使用高分辨率潜在扩散模型(LDM),不断抽样和渲染第一阶段的粗略模型。通过交互渲染器进行优化,反向生成 512×512 的高分辨率渲染图像。
Magic3D 还可以对 3D 网格进行基于提示的实时编辑。想改变生成模型,只要改改文字提示,就能立即生成新的模型。

另外,Magic3D 可以在几代生成图像中均保留相同的主题(一般称为「一致性」),不会出现越画越离谱的情况,并将 2D 图像(如立体派绘画)的风格应用于 3D 模型。
通过该模型,不仅可以获得高分辨率的 3D 模型,还保证了降低了运算强度。
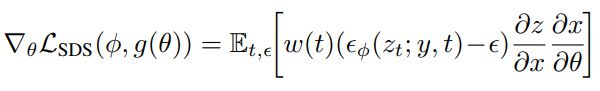
Magic3D 模型中,运算时间主要与高分辨率渲染图像和 LDM 编码器的梯度相关,保证了运算强度的可控。
在生成和训练速度方面,在使用 8 块英伟达 A100 GPU 情况下,两阶段运行时间加起来共计 40 分钟。
不过,英伟达此次没有随论文发布任何 Magic3D 的代码。
谷歌 DreamFusion 要加油了
英伟达团队指出,DreamFusion 存在两大缺陷。
首先,通过该模型,无法获得 3D 模型的高分辨率几何体或纹理,因为扩散模型仅对 64x64 的图像生效。
其次,这种方法的扩展性表现并不好。DreamFusion 的场景渲染模型使基于 Mip-NeRF 360 的大型 MLP。该模型在体渲染时需要海量样本,这在计算上费时费力。
因此,DreamFusion 生成高分辨率的图像需要更大的计算成本,去评估每个样本的神经网络。
英伟达团队使用 Instant NGP 的哈希特征编码,大大降低高分辨率图像特征表示的计算成本。
使用与 DreamFusion 相同的文本提示。对于每个 3D 模型,团队从两个视图渲染它,每个视图都有无纹理渲染,并删除背景以专注于实际的 3D 形状。
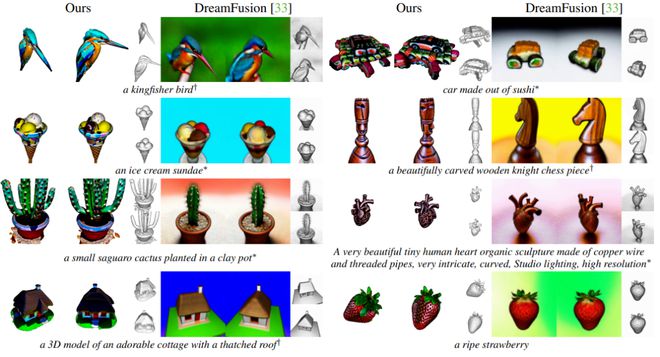
可以发现,Magic3D 生成的 3D 模型在整体和纹理上都更胜一筹。
作为对比,我们向用户并排展示了两个 3D 生成模型的视频,这两个视频分别由谷歌的 DreamFusion 和 Magic3D 使用相同的文本提示从标准视图中生成的,由用户选择更逼真的那个。
在总共 1191 个反馈意见中,有 61.7% 的用户认为 Magic3D 生成的模型质量比 DreamFusion 更高。

研究人员表示,随着模型的完善,所产生的技术可以加速游戏和 VR 应用的开发,可能最终会在电影和电视的特效制作中实现落地应用。
「我们希望通过 Magic3D,可以使 3D 合成技术进一步普及,并激发每个人在 3D 内容上的创造力。」
经过近十年的技术发展,人们对 AIGC 的探索已经进入了商业化、规模化的阶段。
随着越来越多的科技巨头加入这个赛道,创造出令人惊叹的 AI 生成作品,有理由相信,AIGC 的大航海时代已经来临。
参考资料:






