
新智元报道
编辑:Cris
AI 用光所有数据,这一天真的快来了?
作为人工智能的三要素之一,数据的作用举足轻重。
但大家有没有想过:假如有一天,全世界的数据都用完了那咋整?

实际上,提出这个问题的人绝对没有精神问题,因为这一天——可能真的快来了!!!
近日,研究员 Pablo Villalobos 等人一篇名为《我们会用完数据吗?机器学习中数据集缩放的局限性分析》的论文,发表在了 arXiv 上。
他们根据之前对数据集大小趋势的分析,预测了语言和视觉领域数据集大小的增长,估计了未来几十年可用未标记数据总存量的发展趋势。
他们的研究表明:最早在 2026 年,高质量语言数据就将全部消耗殆尽!机器学习发展的速度也将因此而放缓。实在不容乐观。

两方法双管齐下,结果不容乐观
这篇论文的研究团队由 11 名研究员和 3 位顾问组成,成员遍布世界各地,致力于缩小 AI 技术发展与 AI 战略之间的差距,并为 AI 安全方面的关键决策者提供建议。

Chinchilla 是 DeepMind 的研究人员提出的一种新型预测计算优化模型。
实际上,此前在对 Chinchilla 进行实验时,就曾有研究员提出「训练数据很快就会成为扩展大型语言模型的瓶颈」。
因此他们分析了用于自然语言处理和计算机视觉的机器学习数据集大小的增长,并使用了两种方法进行推断:使用历史增长率,并为未来预测的计算预算估计计算最佳数据集大小。
在此之前,他们一直在收集有关机器学习输入趋势的数据,包括一些训练数据等,还通过估计未来几十年互联网上可用未标记数据的总存量,来调查数据使用增长。
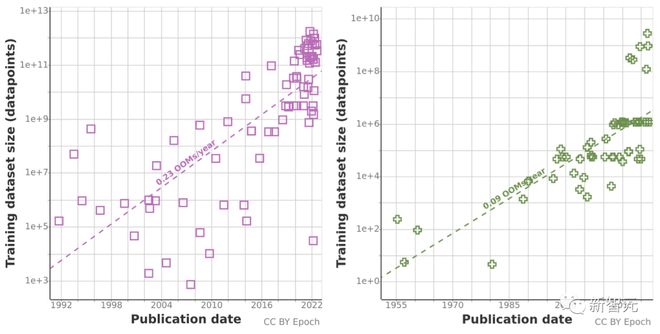
由于历史预测趋势可能会受过去十年计算量异常增长的「误导」,研究团队还使用了 Chinchilla 缩放定律,来估计未来几年的数据集大小,提升计算结果的准确性。
最终,研究人员使用一系列概率模型估计未来几年英语语言和图像数据的总存量,并比较了训练数据集大小和总数据库存的预测,结果如下图所示。
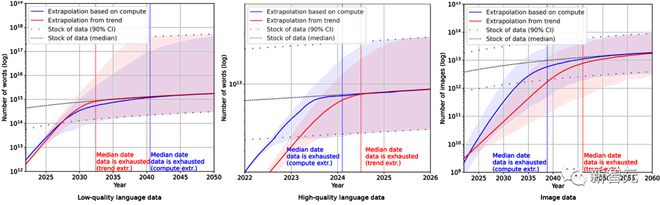
这说明数据集的增长速度将远快于数据存量。
因此,如果当前趋势继续保持下去,数据存量被用光将是不可避免的。下表则显示了预测曲线上每个交叉点的中值耗尽年数。
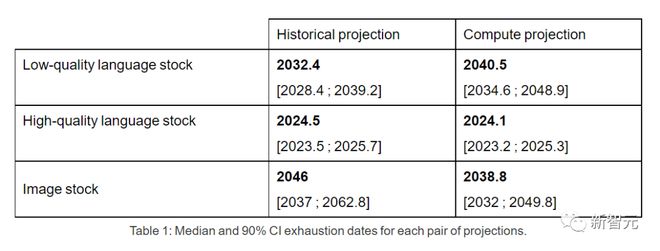
高质量的语言数据库存最早可能在 2026 年之前用尽。
相比之下,低质量的语言数据和图像数据情况略好:前者将在 2030 年至 2050 年间用光,后者将在 2030 年至 2060 年之间。
在论文的最后,研究团队给出结论:如果数据效率没有大幅提高或新的数据来源可用,当前依赖巨大数据集不断膨胀的机器学习模型,它的增长趋势很可能会放缓。
网友:杞人忧天,Efficient Zero 了解一下
不过在这篇文章的评论区里,大多数网友却认为作者杞人忧天。
Reddit 上,一位名为 ktpr 的网友表示:
「自我监督学习有啥毛病么?如果任务指定得好,它甚至可以组合扩展数据集大小。」
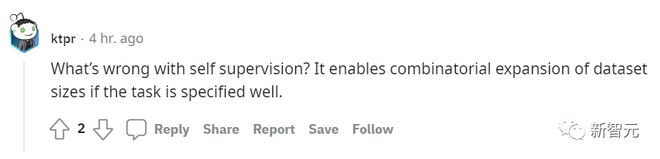
名为 lostmsn 的网友则更加不客气。他直言:
「Efficient Zero 都不了解一下?我认为作者已经严重脱离时代了。」
Efficient Zero 是一种能高效采样的强化学习算法,由清华大学的高阳博士提出。
在数据量有限的情况下,Efficient Zero 一定程度上解决了强化学习的性能问题,并在算法通用测试基准 Atari Game 上获得了验证。
在这篇论文作者团队的博客上,就连他们自己也坦言:
「我们所有的结论都基于不切实际的假设,即当前机器学习数据使用和生产的趋势将继续保持下去,并且数据效率不会有重大提升。」
「一个更加靠谱的模型应该考虑到机器学习数据效率的提高、合成数据的使用以及其他算法和经济因素。」
「因此就实际情况来说,这种分析有严重的局限性。模型的不确定性非常高。」
「不过总体而言,我们仍认为由于缺乏训练数据,到 2040 年时机器学习模型的扩展有大约有 20% 的可能性会显著放缓。」
参考资料:
https://arxiv.org/abs/2211.04325
https://epochai.org/blog/will-we-run-out-of-ml-data-evidence-from-projecting-dataset






