萧箫发自凹非寺
量子位公众号 QbitAI
要说 Transformer 的核心亮点,当然是注意力机制了。
但现在,一篇新研究却突然提出了带点火药味的观点:注意力机制对于预训练 Transformer 有多重要,这事儿得打个问号。

研究人员来自希伯来大学、艾伦人工智能研究所、苹果和华盛顿大学,他们提出了一种新的方法,用来衡量注意力机制在预训练 Transformer 模型中的重要性。
结果表明,即使去掉注意力机制,一些 Transformer 的性能也没太大变化,甚至与原来的模型差异不到十分之一!
这个结论让不少人感到惊讶,有网友调侃:你亵渎了这个领域的神明!

所以,究竟如何判断注意力机制对于 Transformer 模型的重要性?
把注意力换成常数矩阵
这种新测试方法名叫 PAPA,全称“针对预训练语言模型注意力机制的探测分析”(Probing Analysis for PLMs’ Attention)。
PAPA 采用的方法,是将预训练语言模型(PLMs)中依赖于输入的注意力矩阵替换成常数矩阵。
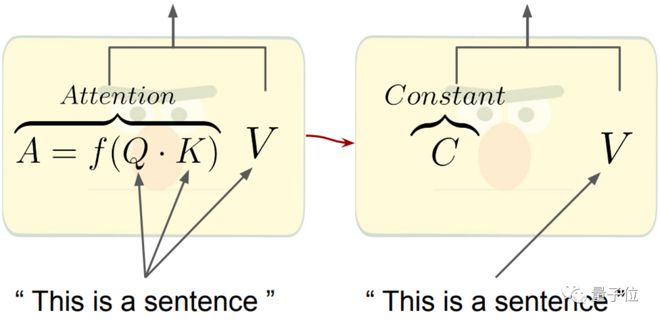
如下图所示,我们熟悉的注意力机制是通过Q和K矩阵,计算得到注意力权重,再作用于V得到整体权重和输出。
现在,Q和K的部分直接被替换成了一个常数矩阵C:
其中常数矩阵C的计算方式如下:
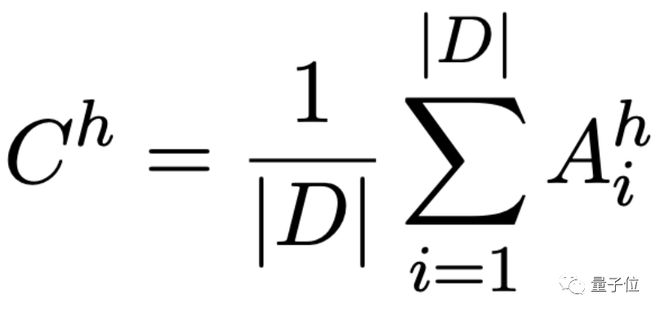
随后,用 6 个下游任务测试这些模型(CoLA、MRPC、SST-2、MNLI、NER、POS),对比采用 PAPA 前后,模型的性能差距。
为了更好地检验注意力机制的重要性,模型的注意力矩阵并非一次性全换成常数矩阵,而是逐次减少注意力头的数量。
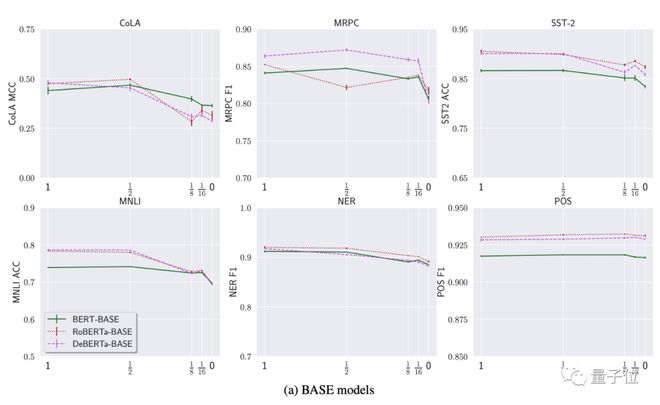
如下图,研究先用了 BERT-BASE、RoBERTa-BASE 和 DeBERTa-BASE 做实验,其中y轴表示性能,x轴是注意力头相比原来减少的情况:
随后,研究又用了 BERT-LARGE、RoBERTa-LARGE 和 DeBERTa-LARGE 做实验:
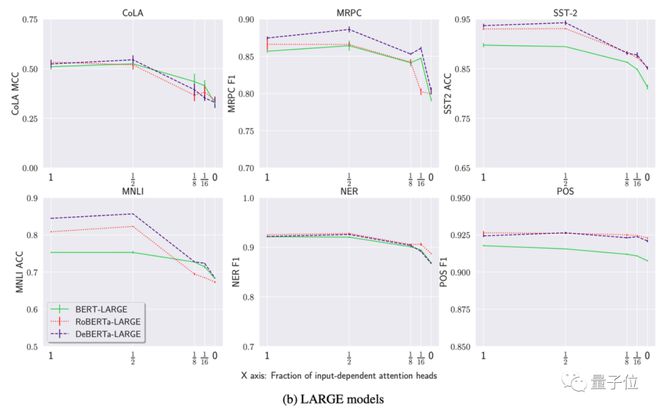
通过比较结果,研究人员发现了一些有意思的现象:首先,用常数矩阵替换一半的注意矩阵,对模型性能的影响极小,某些情况下甚至可能导致性能的提升(x值达到½时,图中有些模型数值不减反增)。
其次,即使注意力头数量降低为0,平均性能下降也就8%,与原始模型相比最多不超过 20%。
研究认为,这种现象表明预训练语言模型对注意力机制的依赖没那么大(moderate)。
模型性能越好,越依赖注意力机制
不过,即使是预训练 Transformer 模型之间,性能表现也不完全一样。
作者们将表现更好的 Transformer 模型和更差的 Transformer 模型进行了对比,发现原本性能更好的模型,在经过 PAPA 的“测试”后,性能反而变得更差了。
如下图,其中y轴代表各模型原本的平均性能,x轴代表将所有注意力矩阵替换为常数矩阵时(经过 PAPA 测试)模型性能的相对降低分值:
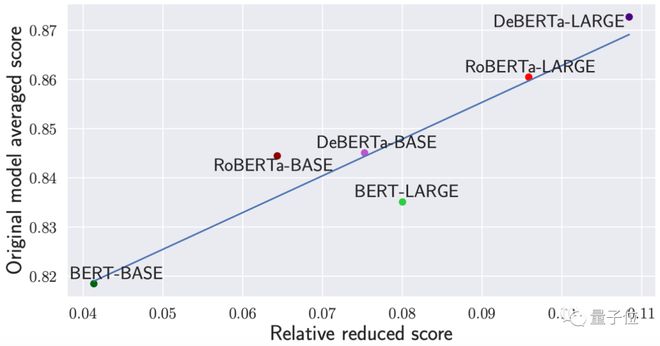
可以看出,之前性能越好的模型,将注意力矩阵替换成常数矩阵受到的损失也越高。
这说明如果模型本身性能越好,对注意力机制的利用能力就越好。
对于这项研究,有网友感觉很赞:
听起来很酷,现在不少架构太重视各种计算和性能任务,却忽略了究竟是什么给模型带来的改变。

但也有网友认为,不能单纯从数据来判断架构变化是否重要。
例如在某些情况下,注意力机制给隐空间(latent space)中数据点带来的幅度变化仅有2-3%:难道这种情况下它就不够重要了吗?不一定。
对于注意力机制在 Transformer 中的重要性,你怎么看?
论文地址:
https://arxiv.org/abs/2211.03495
参考链接:






