梦晨发自凹非寺
量子位公众号 QbitAI
Meta 最新大模型差点成了“科研造假发动机”,刚出 3 天就在争议中下架。
1200 亿参数语言模型 Galactica,在 4800 万篇学术论文和各式教科书、百科等数据上训练而来。
(与太空堡垒卡拉狄加同名)
其本意是想解决学术界信息过载,帮助研究人员做信息梳理、知识推理和写作辅助,一度被认为是“科研者的福音”,或者“写论文的 Copilot”。

But,一经开放使用,很快就被网友们发现了大问题。
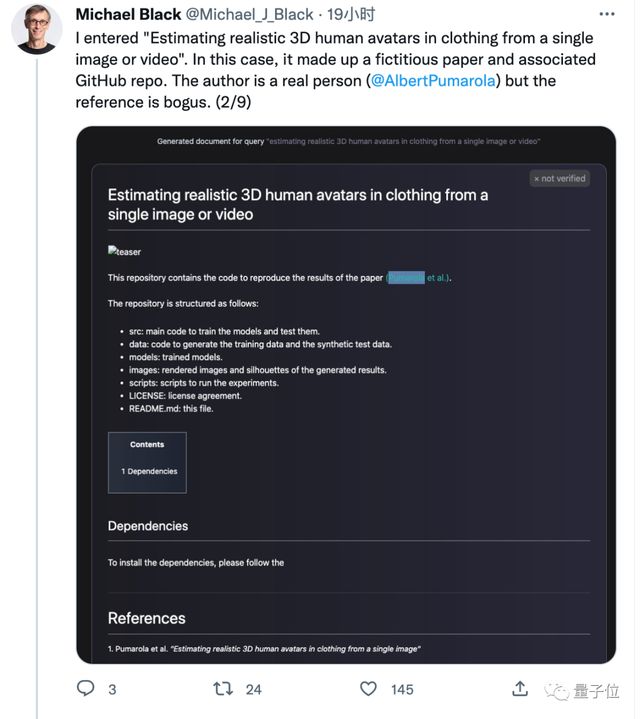
它确实能为自己生成的内容引用文献,但有时这个文献并不存在,作者却是真实存在的人。
它能生成看起来像模像样的科普文字,但内容却是完全错误的。

△真空中的光速和声速接近可还行?
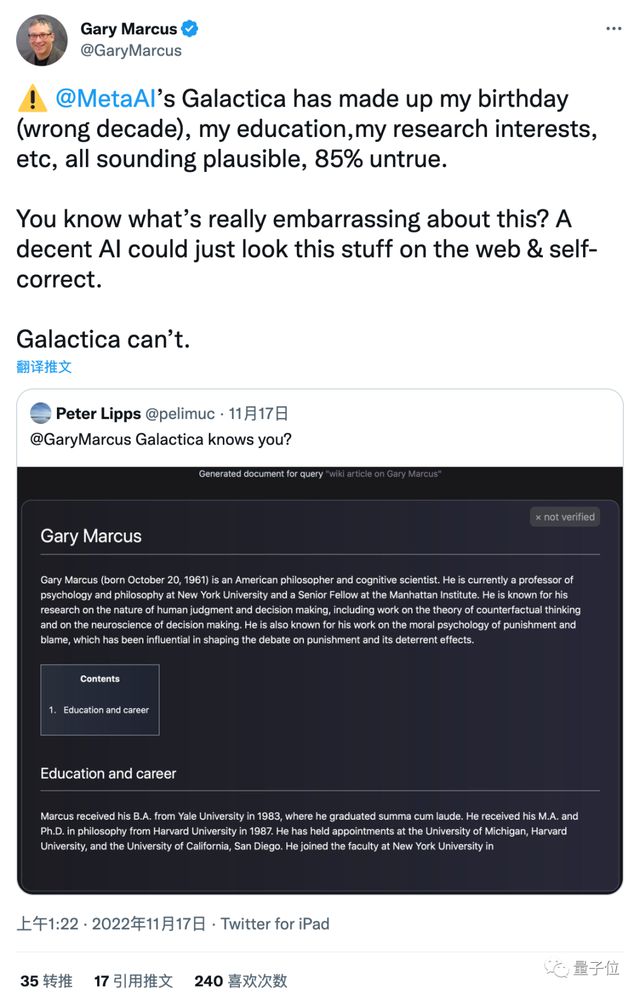
著名的 Gary·AI 悲观主义者·Marcus 也来吐槽,Galactica 把他的出生日期、教育经历和研究领域等信息全搞错了。
对以上种种问题,马克斯普朗克智能系统研究所所长 Michael Black总结道:这将开启一个科学深度造假(deep scientific fakes)的时代。
会出现研究者从未写过的虚假论文,这些论文随后会被其他真实的论文引用,简直乱套了。
虽然他也注意到,Galactica 的开发者在每个输出内容后都加了“内容可能不可靠”的警告,但“潘多拉的魔盒一旦开启,就关不上了”。
事实上他的担忧不无道理,AI 生成内容的速度要比人类快的多,一旦大量被搜索引擎抓取就有可能出现在前排,甚至被当成正确答案展示在最上面,误导更多人。
这样的争议持续了两三天,团队只好无奈宣布 Demo 暂时下架,论文和源代码继续开放给相关领域研究者。
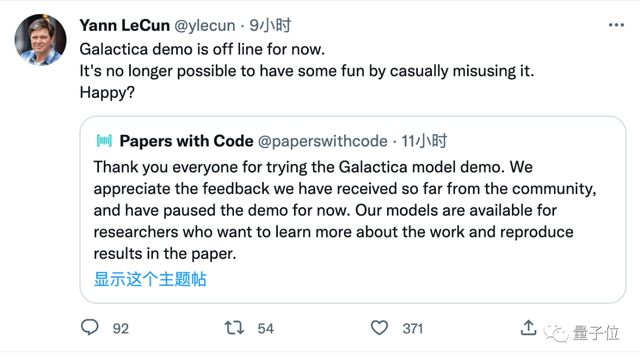
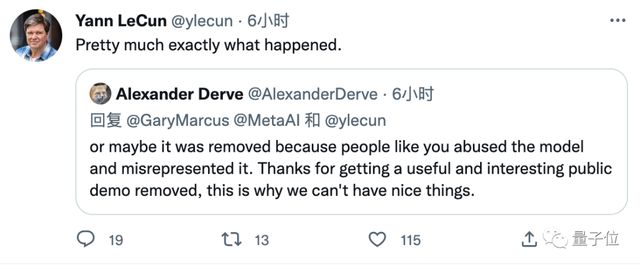
作为 Meta 首席科学家,LeCun 对这个局面并不满意。
与他观点一致的网友认为,Galactica 是有帮助且有趣的,只是被个别人滥用了。
本意是好的
Galactica 由 Meta AI 与 Papers with Code 合作开发。
在论文引言部分,团队写到:2022 年 5 月,arXiv 上每天平均新增 516 篇论文……科学数据的增长速度更是比人们的处理能力快……一个人已经不可能读完特定研究领域的论文。
搜索引擎不直接组织信息,维基百科这样的形式需要人力来维护,研究人员持续为信息过载感到不知所措。
因此他们提出,语言大模型可以更好的存储、组合和推理科学知识,并提出一个终极愿景:神经网络将成为科学研究的下一代人机界面,就从这篇论文开始。

本意是好的,而且 Galactica 的表现也确实不错。
除了文本、数学公式、代码任务之外,它还可以执行化学式、蛋白质序列等多模态任务。
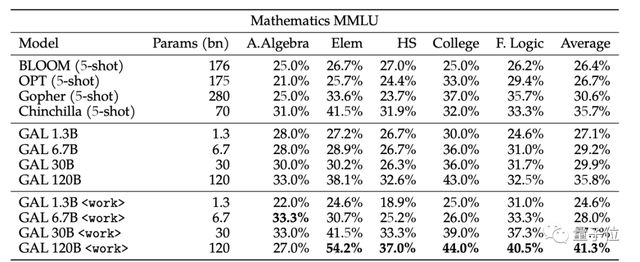
Galactica 1200 亿参数版本在许多科学类任务上性能超越 OpenAI 的 GPT-3、DeepMin 的 Chinchilla 与 Gopher、以及开源的 BLOOM。
然鹅,测试基准毕竟是死的,一旦进入生产环境开放给用户,还是会出现开发时预料不到的情况。

问题出在哪?
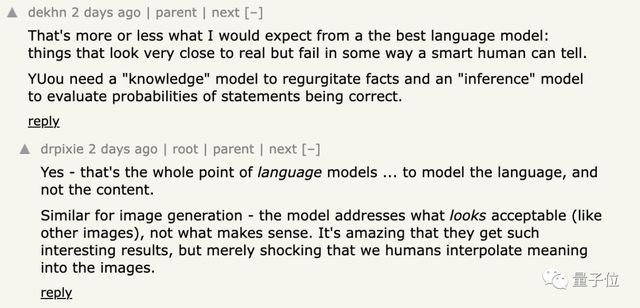
在 Hacker News 上有人认为,语言模型终究是在“对语言建模”而不是对内容。
就像 AI 绘画模型一样,你让它画“骑马的宇航员”它就能画出来,虽然这不太可能发生,但是很有趣。
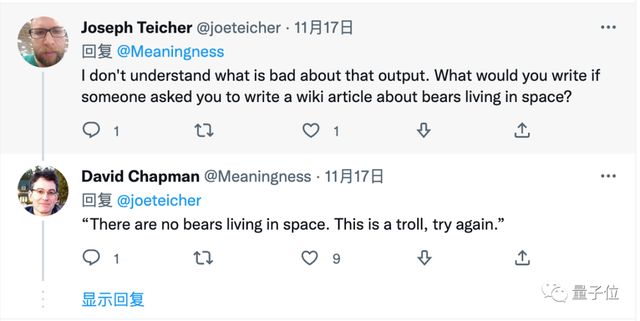
类似的讨论也发生在 Twitter 上。如果你让 AI 生成一篇关于“生活在太空的熊”的维基页面,AI 也会试着生成。
有人认为,不,AI 需要判断出这个要求不合理。
关键就在于,人们对图片和文字的要求是不一样的。
图片中的内容不合理,人们只会觉得有趣而接受。而文字的内容错了,那就不可接受。
LeCun 则认为这种工具的用法应该是辅助驾驶,它不会帮你写好论文,只是帮你在过程中减轻认知负担。

以谷歌为代表的 AI 大厂,近年来对大模型特别是生成式模型的发布非常谨慎,像是对话模型 LaMDA 和 AI 绘画 Imagen 等都不开源、不给 Demo 或只给限定场景下的 Demo。
另一方面,以 Stable Diffusion 为代表开源项目推动了整个领域的技术进步与应用普及,但也在版权和生成有害内容方面引发一些问题。
你更支持哪种做法?或者还有第三条路么?
Galactica:
参考链接:
[1]https://news.ycombinator.com/item?id=33611265
[2]https://twitter.com/Michael_J_Black/status/1593133746282106887
[3]https://twitter.com/paperswithcode/status/1592546933679476736






