詹士发自凹非寺
量子位公众号 QbitAI
AI 如何学到知识的?科学家敲开了它的脑壳看了看。
这两天,DeepMind 及谷歌大脑一篇文章被《美国国家科学院院刊》(PNAS)收录,其内容正是以 5 年前发布的 AlphaZero 为例,研究神经网络如何获取并理解国际象棋知识。

在内容中,研究者重点关注了「神经网络是如何学习的」「知识又如何被量化表示」等问题。
有意思的是,他们发现:
在没有人类对弈指导下,AlphaZero 仍形成了一套类似专业棋手才懂的概念体系。研究者还进一步探寻了这些概念何时何处形成。
此外,他们还对比了 AlphaZero 与人类开局棋风的不同。
有网友感慨,这是个影响深远的工作:
也有人感慨,AlphaZero 能计算任何人类行为特征了?!
欲知更多观察结果,往下看。
掀起了神经网络的头盖骨
AlphaZero 于 2017 年由 DeepMind 发布并一鸣惊人。
这是一种神经网络驱动的强化学习器,专精于棋类,内部包含了残差网络(ResNet)骨干网及分离的策略及价值 heads。
其输出函数可表示如下,z为国际象棋排布情况:
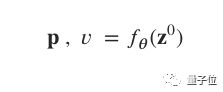
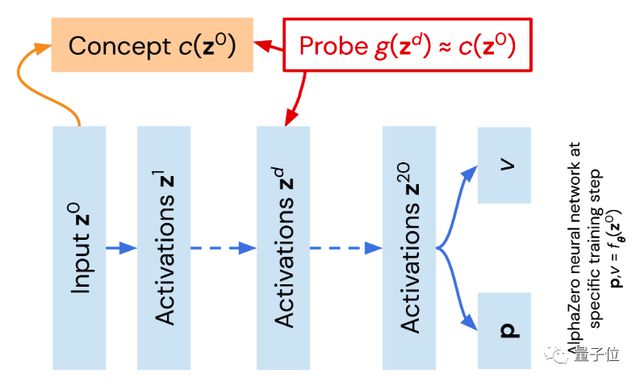
为研究 AlphaZero 如何「学习」的,研究者构建了一个人类理解国际象棋的函数c(z0)。其中,z0 为一个象棋特定排布概念,c(z0) 以专业国际象棋引擎 Stockfish 8 评估分数作为参考。
再从 AlphaZero 角度,设一个广义线性函数g(zd),作为在不同层取值的探针。训练设定下,g(zd)将不断趋近(0),研究者通过观察g(zd)与(0) 近似情况,以确认系统是否理解相关概念。
接着,研究团队随机抽取了 10 万盘游戏作为训练集,观察 AlphaZero 表现。
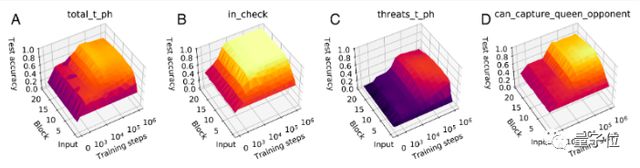
情况如下图,结果显示,随着训练步数(step)及 ResNet 网络块数(block)越来越多,AlphaZero 表现出来的分数越来越高(图A),对弈过程中,每一步对敌方威胁性的也随之增加(图C)。
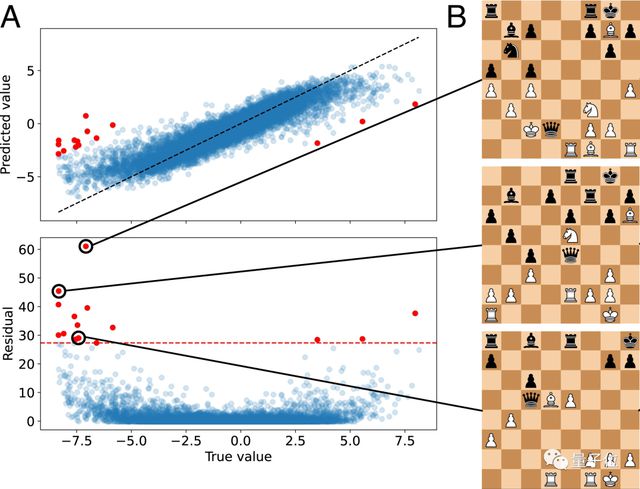
由于实验中出现了异常值,研究者探讨了其背后的潜在语义。
如下图,少数红色点位置远离主流分布,残差值也在红虚线之上,说明人类对棋局判断c函数与g函数有明显差异。
研究团队发现,这些值对应棋局中,人类判断为白方有利,同时,黑方皇后都能在兑子(exchange)过程中被进一步吃掉。
研究者推断认为,这是源于 AlphaZero 的 Value Head 与参考评价函数编码方式与参考系统的不同。
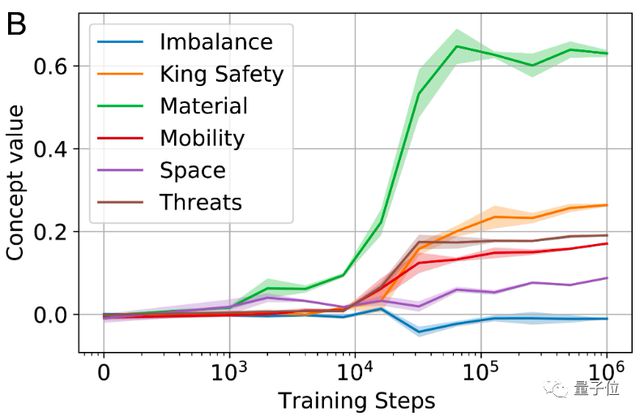
此外,研究者还观察了人类棋手及国际象棋编程所看重的重要参数,随训练过程的变化,其中包括:国王安全度(King Safety)、一方棋子总战力(Material)、机动性(Mobility)、走棋威胁性(Threats)等。
结果显示,它们在初始情况下几乎为零,但随着训练不断往下进行,以国王安全度(King Safety)、一方棋子总战力(Material)为代表,部分参数在模型中的权重明显上升。
这让研究者相信,通过训练过程,AlphaZero 已经逐渐掌握了原本没有教给它的相关重要概念或者说知识。
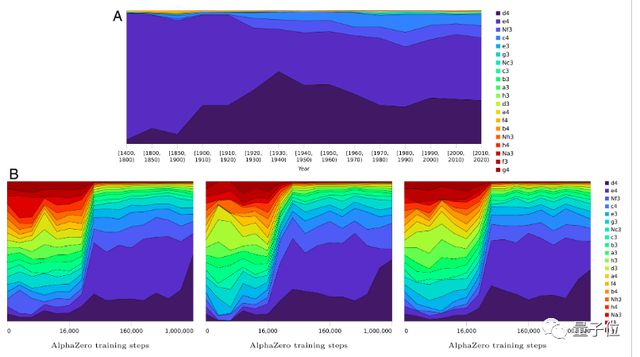
最后,研究者还着重看了看开局演变与下棋风格,发现 AlphaZero 随时间推移,下棋路径选择范围在缩小,而人类下棋偏好和路径在变多。
科研人员表示,目前原因尚不清楚,但它反应了人与机器神经网络之间的根本差异。
关于后续研究方向,作者提出,下一步希望能探索 AI 模型能否超越人类的认知概念范围,去掌握学会新的东西。
团队介绍
本文一作 Thomas McGrath 来自 DeepMind,博士毕业于伦敦帝国学院,主要研究领域包括 ML、人工智能安全及可解释性。
二作 Andrei Kapishnikov,来自 Google Brain,主攻人工智能应用领域,早前曾在 VMware 及 Oracle 从事技术工作。
值得一提的是,国际象棋大师 Vladimir Kramnik 也参与了该项目的研究。
参考链接:
[1]https://twitter.com/weballergy/status/1461281358324588544






